This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
What is a dataengineer? Dataengineers design, build, and optimize systems for data collection, storage, access, and analytics at scale. They create data pipelines that convert raw data into formats usable by data scientists, data-centric applications, and other data consumers.
What is a dataengineer? Dataengineers design, build, and optimize systems for data collection, storage, access, and analytics at scale. They create data pipelines used by data scientists, data-centric applications, and other data consumers. The dataengineer role.
For example, a retailer might scale up compute resources during the holiday season to manage a spike in sales data or scale down during quieter months to save on costs. For example, data scientists might focus on building complex machine learning models, requiring significant compute resources.
For example, a retailer might scale up compute resources during the holiday season to manage a spike in sales data or scale down during quieter months to save on costs. For example, data scientists might focus on building complex machine learning models, requiring significant compute resources.
Dbt is a popular tool for transforming data in a data warehouse or data lake. It enables dataengineers and analysts to write modular SQL transformations, with built-in support for data testing and documentation. Jaffle Shop Demo To demonstrate our setup, we’ll use the jaffle_shop example.
If we look at the hierarchy of needs in data science implementations, we’ll see that the next step after gathering your data for analysis is dataengineering. This discipline is not to be underestimated, as it enables effective data storing and reliable data flow while taking charge of the infrastructure.
Lakehouse Optimizer : Cloudera introduced a service that automatically optimizes Iceberg tables for high-performance queries and reduced storage utilization. The net result is that queries are more efficient and run for shorter durations, while storage costs and energy consumption are reduced. Give it a try today.
When we introduced Cloudera DataEngineering (CDE) in the Public Cloud in 2020 it was a culmination of many years of working alongside companies as they deployed Apache Spark based ETL workloads at scale. It’s no longer driven by data volumes, but containerization, separation of storage and compute, and democratization of analytics.
I know this because I used to be a dataengineer and built extract-transform-load (ETL) data pipelines for this type of offer optimization. Part of my job involved unpacking encrypted data feeds, removing rows or columns that had missing data, and mapping the fields to our internal data models.
A few months ago, I wrote about the differences between dataengineers and data scientists. An interesting thing happened: the data scientists started pushing back, arguing that they are, in fact, as skilled as dataengineers at dataengineering. Dataengineering is not in the limelight.
With growing disparate data across everything from edge devices to individual lines of business needing to be consolidated, curated, and delivered for downstream consumption, it’s no wonder that dataengineering has become the most in-demand role across businesses — growing at an estimated rate of 50% year over year.
The data preparation process should take place alongside a long-term strategy built around GenAI use cases, such as content creation, digital assistants, and code generation. Known as dataengineering, this involves setting up a data lake or lakehouse, with their data integrated with GenAI models.
If you’re an executive who has a hard time understanding the underlying processes of data science and get confused with terminology, keep reading. We will try to answer your questions and explain how two critical data jobs are different and where they overlap. Data science vs dataengineering. Feature engineering.
download Model-specific cost drivers: the pillars model vs consolidated storage model (observability 2.0) All of the observability companies founded post-2020 have been built using a very different approach: a single consolidated storageengine, backed by a columnar store. and observability 2.0. understandably). moving forward.
DataEngineers of Netflix?—?Interview Interview with Pallavi Phadnis This post is part of our “ DataEngineers of Netflix ” series, where our very own dataengineers talk about their journeys to DataEngineering @ Netflix. Pallavi Phadnis is a Senior Software Engineer at Netflix.
The solution combines data from an Amazon Aurora MySQL-Compatible Edition database and data stored in an Amazon Simple Storage Service (Amazon S3) bucket. Solution overview Amazon Q Business is a fully managed, generative AI-powered assistant that helps enterprises unlock the value of their data and knowledge.
That’s why a data specialist with big data skills is one of the most sought-after IT candidates. DataEngineering positions have grown by half and they typically require big data skills. Dataengineering vs big dataengineering. This greatly increases data processing capabilities.
So, along with data scientists who create algorithms, there are dataengineers, the architects of data platforms. In this article we’ll explain what a dataengineer is, the field of their responsibilities, skill sets, and general role description. What is a dataengineer?
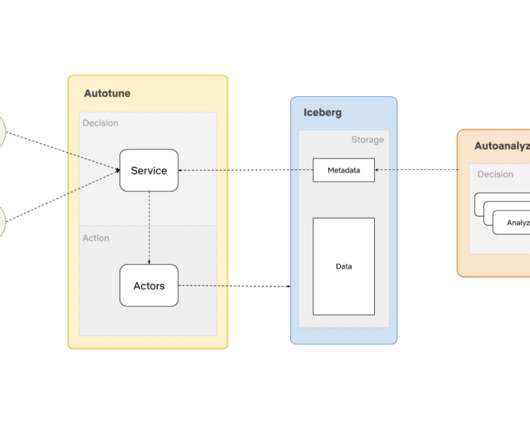
At this scale, we can gain a significant amount of performance and cost benefits by optimizing the storage layout (records, objects, partitions) as the data lands into our warehouse. We built AutoOptimize to efficiently and transparently optimize the data and metadata storage layout while maximizing their cost and performance benefits.
Introduction: We often end up creating a problem while working on data. So, here are few best practices for dataengineering using snowflake: 1.Transform Using COPY and SNOWPIPE is the fastest and cheapest way to load data. In fact, this is another example of using the right tools.
Data Science and Machine Learning sessions will cover tools, techniques, and case studies. This year’s sessions on DataEngineering and Architecture showcases streaming and real-time applications, along with the data platforms used at several leading companies. Data platforms. Privacy and security.
After the data is transcribed, MaestroQA uses technology they have developed in combination with AWS services such as Amazon Comprehend to run various types of analysis on the customer interaction data. For example, Can I speak to your manager? To start developing this product, MaestroQA first rolled out a product called AskAI.
I mentioned in an earlier blog titled, “Staffing your big data team, ” that dataengineers are critical to a successful data journey. That said, most companies that are early in their journey lack a dedicated engineering group. Image 1: DataEngineering Skillsets.
I had my first job as a software engineer in 1999, and in the last two decades I've seen software engineering changing in ways that have made us orders of magnitude more productive. These are just examples — I could go on all day. You need storage to build something to serve 1M concurrent users?
Are you a dataengineer or seeking to become one? This is the first entry of a series of articles about skills you’ll need in your everyday life as a dataengineer. This blog post is for you. So let’s begin with the first and, in my opinion, the most useful tool in your technical tool belt, SQL.
When asked, Heartex says that it doesn’t collect any customer data and open sources the core of its labeling platform for inspection. “We’ve built a data architecture that keeps data private on the customer’s storage, separating the data plane and control plane,” Malyuk added.
Multiple specialized Amazon Simple Storage Service Buckets (Amazon S3 Bucket) store different types of outputs. Solution Components Storage architecture The application uses a multi-bucket Amazon S3 storage architecture designed for clarity, efficient processing tracking, and clear separation of document processing stages.
While companies find AI’s predictive power alluring, particularly on the data analytics side of the organization, achieving meaningful results with AI often proves to be a challenge. It’s true that AI can help to project revenue, for example, by identifying trends in buying and selling.
For example, New York-Presbyterian Hospital, which has a network of hospitals and about 2,600 beds, is deploying over 150 AI and VR/AR projects this year across all clinical specialties. “We On-prem infrastructure will grow cold — with the exception of storage, Nardecchia says.
To do this, they are constantly looking to partner with experts who can guide them on what to do with that data. This is where dataengineering services providers come into play. Dataengineering consulting is an inclusive term that encompasses multiple processes and business functions.
Generative AI models (for example, Amazon Titan) hosted on Amazon Bedrock were used for query disambiguation and semantic matching for answer lookups and responses. The first data source connected was an Amazon Simple Storage Service (Amazon S3) bucket, where a 100-page RFP manual was uploaded for natural language querying by users.
The idea that telemetry data needs to be managed, or needs a strategy, draws a lot of inspiration from the data world (as in, BI and DataEngineering). Your company most likely has a data team that manages the data warehouse(s), data pipelines, data sources, and reporting tools.
Data analytics is a discipline focused on extracting insights from data. It comprises the processes, tools and techniques of data analysis and management, including the collection, organization, and storage of data. For example, how might social media spending affect sales? Data analytics examples.
Here are some examples: Fraud It’s critical to identify bad actors using high-quality AI models and data Product recommendations It’s important to stay competitive in today’s ever-expanding online ecosystem with excellent product recommendations and aggressive, responsive pricing against competitors.
Let’s take an example Say your data is divided in two categories: personal and non-personal data. And that some people in your company should be allowed to view that personal data, while others should not. In our example we want some people (in the group can_handle_personal_data ) to be able to use the entire table.
Currently, the USPTO’s platform engineering team is actively testing an AI capability that can detect performance constraints and address them by allocating more storage, for example, or adding more CPU or memory resources, or moving data from one repository to another. “AI Scale up, then expand out.
The forecasting systems DTN had acquired were developed by different companies, on different technology stacks, with different storage, alerting systems, and visualization layers. Working with his new colleagues, he quickly identified rebuilding those five systems around a single forecast engine as a top priority.
For specific data types (like images), there are new companies like Neuromation, DataGen, and AI.Reverie, that can help lower the cost of training data through tools for generating synthetic data. Another way we can glean the value of data is to look at the valuation of startups that are known mainly for their data sets.
The demand for data skills (“the sexiest job of the 21st century”) hasn’t dissipated. LinkedIn recently found that demand for data scientists in the US is “off the charts,” and our survey indicated that the demand for data scientists and dataengineers is strong not just in the US but globally.
Many low cardinality columns are repeated for all rows, for example, type of car, brand, and ‘Taxi indicator’ to name a few. A columnar storage format like parquet or DuckDB internal format would be more efficient to store this dataset. See substring(<bitint>, example above. parquet # 1.2G
Data intake A user uploads photos into Mixbook. The raw photos are stored in Amazon Simple Storage Service (Amazon S3). The data intake process involves three macro components: Amazon Aurora MySQL-Compatible Edition , Amazon S3, and AWS Fargate for Amazon ECS. DJ Charles is the CTO at Mixbook.
Second, since IaaS deployments replicated the on-premises HDFS storage model, they resulted in the same data replication overhead in the cloud (typical 3x), something that could have mostly been avoided by leveraging modern object store. Storage costs. using list pricing of $0.72/hour hour using a r5d.4xlarge
This blog post focuses on how the Kafka ecosystem can help solve the impedance mismatch between data scientists, dataengineers and production engineers. Impedance mismatch between data scientists, dataengineers and production engineers. Data scientists love Python, period.
Despite the variety and complexity of data stored in the corporate environment, everything is typically recorded in simple columns and rows. This is a classic spreadsheet look we’re all familiar with, and that’s how most databases file data. An example of database tables, structuring music by artists, albums, and ratings dimensions.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content