This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
For example, a retailer might scale up compute resources during the holiday season to manage a spike in sales data or scale down during quieter months to save on costs. For example, data scientists might focus on building complex machine learning models, requiring significant compute resources.
If we look at the hierarchy of needs in data science implementations, we’ll see that the next step after gathering your data for analysis is dataengineering. This discipline is not to be underestimated, as it enables effective data storing and reliable data flow while taking charge of the infrastructure.
For example, a retailer might scale up compute resources during the holiday season to manage a spike in sales data or scale down during quieter months to save on costs. For example, data scientists might focus on building complex machine learning models, requiring significant compute resources.
Not cleaning your data enough causes obvious problems, but context is key. “A A lot of organizations spend a lot of time discarding or improving zip codes, but for most data science, the subsection in the zip code doesn’t matter,” says Kashalikar. That’s a classic example of too much good is wasted.”
Deployment isolation: Handling multiple users and environments During the development of a new data pipeline, it is common to make tests to check if all dependencies are working correctly. Let’s see through an example. Therefore, we can just run databricks bundle deploy command, to deploy on dev target. x-cpu-ml-scala2.12
With growing disparate data across everything from edge devices to individual lines of business needing to be consolidated, curated, and delivered for downstream consumption, it’s no wonder that dataengineering has become the most in-demand role across businesses — growing at an estimated rate of 50% year over year.
If theres one thing we know about data problems, its that cost is always a first class citizen. Get your free copy of Charity’s Cost Crisis in Metrics Tooling whitepaper. Metrics-heavy shops are used to blaming custom metrics for their cost spikes, and for good reason. which has made them less differentiated.
For example, mapping the time taken for tasks such as rate case submissions can pinpoint where AI can streamline processes. By evaluating metrics like lead time (time to start an action) and cycle time (time spent on productive work), utilities can identify repetitive tasks that can be automated.
By Abhinaya Shetty , Bharath Mummadisetty At Netflix, our Membership and Finance DataEngineering team harnesses diverse data related to plans, pricing, membership life cycle, and revenue to fuel analytics, power various dashboards, and make data-informed decisions.
A data scientist is a mix of a product analyst and a business analyst with a pinch of machine learning knowledge, says Mark Eltsefon, data scientist at TikTok. And in a mature ML environment, ML engineers also need to experiment with serving tools that can help find the best performing model in production with minimal trials, he says.
After the data is transcribed, MaestroQA uses technology they have developed in combination with AWS services such as Amazon Comprehend to run various types of analysis on the customer interaction data. For example, Can I speak to your manager? Success metrics The early results have been remarkable.
Generative AI models (for example, Amazon Titan) hosted on Amazon Bedrock were used for query disambiguation and semantic matching for answer lookups and responses. Model monitoring of key NLP metrics was incorporated and controls were implemented to prevent unsafe, unethical, or off-topic responses.
This isn’t just our opinion - our startup metrics prove it! For example, let’s consider Mark. That blurb, and the following examples, were all generated from GPT in only a few seconds, at a cost of less than one penny. Everyone struggles with empty text boxes. Drop-off on the first page of an application is bad news.
Self-service analytics typically involves tools that are easy to use and have basic data analytics capabilities. Business professionals and leaders can leverage these to manipulate data so they can identify market trends and opportunities, for example. Have a data governance plan as well to validate and keep the metrics clean.
Bo Lemmers, Analytics Engineer here at Xebia, and Mike Kamysz, DataEngineer at The Data Institute kick off the series with: “ Why can’t I just query the raw data? ” When you query raw data, it’s like having a blank canvas. You can create your own metrics, dimensions, and transformations on the fly.
Real-time AI brings together streaming data and machine learning algorithms to make fast and automated decisions; examples include recommendations, fraud detection, security monitoring, and chatbots. What metrics are used to understand the business impact of real-time AI?
The idea that telemetry data needs to be managed, or needs a strategy, draws a lot of inspiration from the data world (as in, BI and DataEngineering). Your company most likely has a data team that manages the data warehouse(s), data pipelines, data sources, and reporting tools.
The startup, built by Stiglitz, Sourabh Bajaj , and Jacob Samuelson , pairs students who want to learn and improve on highly technical skills, such as devops or data science, with experts. Edtech’s search for the magic metric. Some classes, like this SQL crash course , are even taught by CoRise employees. It has a 68 NPS score.
Data Scientist Cathy O’Neil has recently written an entire book filled with examples of poor interpretability as a dire warning of the potential social carnage from misunderstood models—e.g., Analysts and data scientists can possibly use model comparison and evaluation methods to assess the accuracy of the models.
The data is stored in a data lake and retrieved by SQL using Amazon Athena. We used a large language model (LLM) with query examples to make the search work using the language used by Imperva internal users (business analysts). Using an LLM with the right examples can make this task less difficult.
You know the one, the mathematician / statistician / computer scientist / dataengineer / industry expert. Some companies are starting to segregate the responsibilities of the unicorn data scientist into multiple roles (dataengineer, ML engineer, ML architect, visualization developer, etc.),
Analyzing impression history, for example, might help determine how well a specific row on the home page is functioning or assess the effectiveness of a merchandising strategy. We accomplish this by gathering detailed column-level metrics that offer insights into the state and quality of each impression.
Businesses typically rely on keywords to make sense of unstructured data to pull out relevant data using searchable terms. Semi-structured data falls between the two. It doesn’t conform to a data model but does have associated metadata that can be used to group it. A method for turning data into value.
We build it super fast — the above example in a couple of seconds, since we built our own container builder and have fast machines in the cloud with super fast internet. I'm deliberately vague about what exact role I mean here: take it to mean dataengineers, data scientists, ML engineers, analytics engineers, and maybe more roles.
KDE handles over 10B flow records/day with a microservice architecture that's optimized using metrics. Here at Kentik, our Kentik Detect service is powered by a multi-tenant big data datastore called Kentik DataEngine. And that leads us to metrics. Health checks and series metrics. The life of a query.
For example, Netflix takes advantage of ML algorithms to personalize and recommend movies for clients, saving the tech giant billions. MLEs are usually a part of a data science team which includes dataengineers , data architects, data and business analysts, and data scientists.
Instead of writing code with hard-coded algorithms and rules that always behave in a predictable manner, ML engineers collect a large number of examples of input and output pairs and use them as training data for their models. And you, as the product manager, are caught between them.
Also, the candidate should have knowledge of the different metrics used to evaluate the performance of a model. . The candidate should have a basic understanding of business or the industry in which he is applying as a data scientist. You could have a bunch of data and very little idea on what to do with it. Neural Networks .
Additionally, the complexity increases due to the presence of synonyms for columns and internal metrics available. Below are some examples which you can keep in mind while asking the questions.") Below are some examples which you can keep in mind while asking the questions.") I am creating a new metric and need the sales data.
Some well-known and widely quoted examples are Albert Einstein saying, “The intuitive mind is a sacred gift,” and Steve Jobs with his “Have the courage to follow your heart and intuition.”. In the era of global digital transformation , the role of data analysis in decision-making increases greatly.
For data warehouses, it can be a wide column analytical table. Many companies reach a point where the rate of complexity exceeds the ability of dataengineers and architects to support the data change management speed required for the business. Data and cloud strategy must align.
Performance metrics appear in charts and graphs. . For example, a user identified by “3xksle8z” runs only 3% of the queries, yet consumes far more memory than any other user, consuming about 5.9 For example, we see a large number of joins in these queries: Too many joins and inline views characterize inefficiently written SQL.
To learn about Analytics and Viz Engineering, have a look at Analytics at Netflix: Who We Are and What We Do by Molly Jackman & Meghana Reddy and How Our Paths Brought Us to Data and Netflix by Julie Beckley & Chris Pham. Curious to learn about what it’s like to be a DataEngineer at Netflix?
Full ownership often means building new data pipelines, navigating complex schemas and large data sets, developing or improving metrics for business performance, and creating intuitive visualizations and dashboards?—?always These are only possible through the one-two punch of deep business context ?? and technical excellence ??.
You may recall from the previous blogs in this series that ECC is leveraging the Cloudera Data Platform (CDP) to cover all the stages of its data life cycle. Data Collection – streaming data. Data Enrichment – dataengineering. Reporting – data warehousing & dashboarding. Schedule ML Jobs.
In our example, obvious stakeholders include healthcare providers, patients, and insurers. These are parties indirectly affected by the project, such as local communities, adjacent industries, regulatory bodies, or, in the example of healthcare, even medical researchers. This goes beyond data and algorithms.
There is a clear consensus that data teams should express their goals and results in business value terms and not in technical, tactical descriptions, such as “improving dataengineering” and “better master data management.” . As an example, specialty insurance underwriting was highlighted.
Over the last 12-18 months, companies that use a lot of ML and employ teams of data scientists have been describing their internal data science platforms (see, for example, Uber , Netflix , Twitter , and Facebook ). There are also many important considerations that go beyond optimizing a statistical or quantitative metric.
Data architect and other data science roles compared Data architect vs dataengineerDataengineer is an IT specialist that develops, tests, and maintains data pipelines to bring together data from various sources and make it available for data scientists and other specialists.
People analytics is the analysis of employee-related data using tools and metrics. Dashboard with key metrics on recruiting, workforce composition, diversity, wellbeing, business impact, and learning. Descriptive analytics is used to gather and analyze data that represents the current state of things or historical events.
Data obsession is all the rage today, as all businesses struggle to get data. But, unlike oil, data itself costs nothing, unless you can make sense of it. Dedicated fields of knowledge like dataengineering and data science became the gold miners bringing new methods to collect, process, and store data.
Exploring your data to target a valuable question you want to find an answer to. Starting with the dataengineering and management work to generate a clean and coherent data set from the source systems, data experts will then move into activities to explore the data, build models, and evaluate them to test for insights.
Recall the following key attributes of a machine learning project: Unlike traditional software where the goal is to meet a functional specification , in ML the goal is to optimize a metric. Quality depends not just on code, but also on data, tuning, regular updates, and retraining. Dataengineers vs. data scientists”.
Read Hilary’s book on this topic: Ethics and Data Science. Panelists shared some examples of how to promote and embrace diversity and get involved. Violeta spoke about the importance of metrics and KPIs. Alice Albrecht is a Manager, Data Science Strategy and Advising at Cloudera Fast Forward Labs. Call to action.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









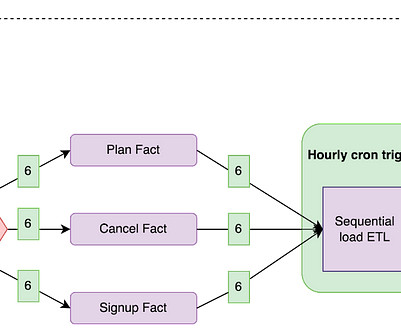












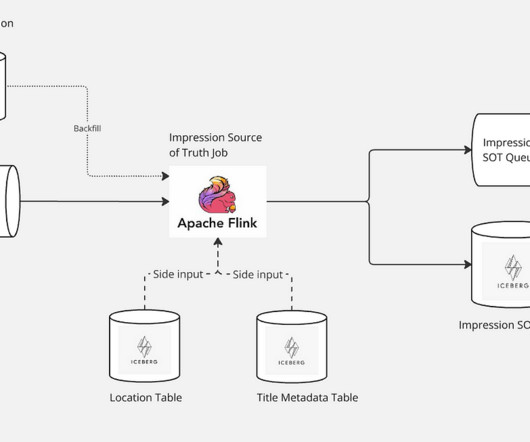



























Let's personalize your content