This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
It’s important to understand the differences between a dataengineer and a data scientist. Misunderstanding or not knowing these differences are making teams fail or underperform with big data. I think some of these misconceptions come from the diagrams that are used to describe data scientists and dataengineers.
Strata Data London will introduce technologies and techniques; showcase use cases; and highlight the importance of ethics, privacy, and security. The growing role of data and machinelearning cuts across domains and industries. Data Science and MachineLearning sessions will cover tools, techniques, and case studies.
Recent research shows that 67% of enterprises are using generative AI to create new content and data based on learned patterns; 50% are using predictive AI, which employs machinelearning (ML) algorithms to forecast future events; and 45% are using deep learning, a subset of ML that powers both generative and predictive models.
It was not alive because the business knowledge required to turn data into value was confined to individuals minds, Excel sheets or lost in analog signals. We are now deciphering rules from patterns in data, embedding business knowledge into ML models, and soon, AI agents will leverage this data to make decisions on behalf of companies.
In this short talk, I describe some interesting trends in how data is valued, collected, and shared. Economic value of data. It’s no secret that companies place a lot of value on data and the data pipelines that produce key features. But if data is precious, how do we go about estimating its value?
Universities have been pumping out Data Science grades in rapid pace and the Open Source community made ML technology easy to use and widely available. Both the tech and the skills are there: MachineLearning technology is by now easy to use and widely available. Big part of the reason lies in collaboration between teams.
What is a dataengineer? Dataengineers design, build, and optimize systems for data collection, storage, access, and analytics at scale. They create data pipelines used by data scientists, data-centric applications, and other data consumers. The dataengineer role.
Confidence from business leaders is often focused on the AI models or algorithms, Erolin adds, not the messy groundwork like data quality, integration, or even legacy systems. For example, one of BairesDevs clients was surprised when it spent 30% of an AI project timeline integrating legacy systems, Erolin says.
Gen AI-related job listings were particularly common in roles such as data scientists and dataengineers, and in software development. Training and development Many companies are growing their own AI talent pools by having employees learn on their own, as they build new projects, or from their peers. Thomas, based in St.
Machinelearning can provide companies with a competitive advantage by using the data they’re collecting — for example, purchasing patterns — to generate predictions that power revenue-generating products (e.g. e-commerce recommendations). ” Tecton’s monitoring dashboard.
In the previous blog post in this series, we walked through the steps for leveraging Deep Learning in your Cloudera MachineLearning (CML) projects. RAPIDS on the Cloudera Data Platform comes pre-configured with all the necessary libraries and dependencies to bring the power of RAPIDS to your projects. Project Setup.
Job titles like dataengineer, machinelearningengineer, and AI product manager have supplanted traditional software developers near the top of the heap as companies rush to adopt AI and cybersecurity professionals remain in high demand. An example of the new reality comes from Salesforce.
You know the one, the mathematician / statistician / computer scientist / dataengineer / industry expert. Some companies are starting to segregate the responsibilities of the unicorn data scientist into multiple roles (dataengineer, ML engineer, ML architect, visualization developer, etc.),
Building a scalable, reliable and performant machinelearning (ML) infrastructure is not easy. It takes much more effort than just building an analytic model with Python and your favorite machinelearning framework. Impedance mismatch between data scientists, dataengineers and production engineers.
As the data community begins to deploy more machinelearning (ML) models, I wanted to review some important considerations. We recently conducted a survey which garnered more than 11,000 respondents—our main goal was to ascertain how enterprises were using machinelearning. Model lifecycle management.
In a world fueled by disruptive technologies, no wonder businesses heavily rely on machinelearning. For example, Netflix takes advantage of ML algorithms to personalize and recommend movies for clients, saving the tech giant billions. The role of a machinelearningengineer in the data science team.
This becomes more important when a company scales and runs more machinelearning models in production. Mind, data lineage and discoverability become paramount when collaborating on features. Data lineage clarifies what data sources and transformations create a certain feature. You train a model with these features.
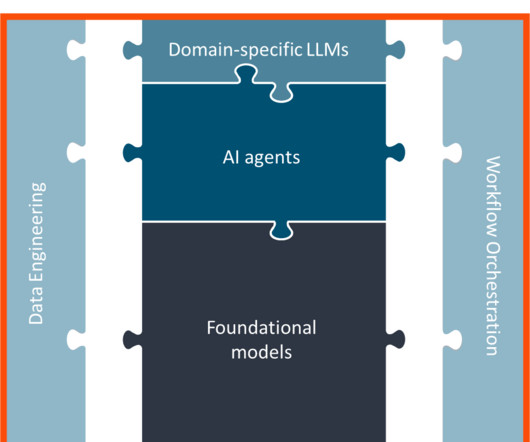
Choreographing data, AI, and enterprise workflows While vertical AI solves for the accuracy, speed, and cost-related challenges associated with large-scale GenAI implementation, it still does not solve for building an end-to-end workflow on its own.
We are excited by the endless possibilities of machinelearning (ML). We recognise that experimentation is an important component of any enterprise machinelearning practice. Continuous Operations for Production MachineLearning (COPML) helps companies think about the entire life cycle of an ML model.
In thinking about features, it can be helpful to visualize a table, where the data used by AI systems is organized into rows of examples (data from which the system learns to make predictions) and columns of attributes (data describing those examples).
For example, a retailer might scale up compute resources during the holiday season to manage a spike in sales data or scale down during quieter months to save on costs. For example, data scientists might focus on building complex machinelearning models, requiring significant compute resources.
Python is used extensively among DataEngineers and Data Scientists to solve all sorts of problems from ETL/ELT pipelines to building machinelearning models. Apache HBase is an effective data storage system for many workflows but accessing this data specifically through Python can be a struggle.
For example, a retailer might scale up compute resources during the holiday season to manage a spike in sales data or scale down during quieter months to save on costs. For example, data scientists might focus on building complex machinelearning models, requiring significant compute resources.
For AI, there’s no universal standard for when data is ‘clean enough.’ A lot of organizations spend a lot of time discarding or improving zip codes, but for most data science, the subsection in the zip code doesn’t matter,” says Kashalikar. That’s a classic example of too much good is wasted.”
Being at the top of data science capabilities, machinelearning and artificial intelligence are buzzing technologies many organizations are eager to adopt. If we look at the hierarchy of needs in data science implementations, we’ll see that the next step after gathering your data for analysis is dataengineering.
The second blog dealt with creating and managing Data Enrichment pipelines. The third video in the series highlighted Reporting and Data Visualization. Specifically, we’ll focus on training MachineLearning (ML) models to forecast ECC part production demand across all of its factories. Data Collection – streaming data.
Why companies are turning to specialized machinelearning tools like MLflow. A few years ago, we started publishing articles (see “Related resources” at the end of this post) on the challenges facing data teams as they start taking on more machinelearning (ML) projects. The upcoming 0.9.0
“There were no purpose-built machinelearningdata tools in the market, so [we] started Galileo to build the machinelearningdata tooling stack, beginning with a [specialization in] unstructured data,” Chatterji told TechCrunch via email. ” To date, Galileo has raised $5.1
While companies find AI’s predictive power alluring, particularly on the data analytics side of the organization, achieving meaningful results with AI often proves to be a challenge. It’s true that AI can help to project revenue, for example, by identifying trends in buying and selling. ” Taking Flyte.
While it is a little dated, one amusing example that has been the source of countless internet memes is the famous, “is this a chihuahua or a muffin?” In this example, the MachineLearning (ML) model struggles to differentiate between a chihuahua and a muffin. MachineLearning Model Lineage.
If you’re an executive who has a hard time understanding the underlying processes of data science and get confused with terminology, keep reading. We will try to answer your questions and explain how two critical data jobs are different and where they overlap. Data science vs dataengineering.
Generative AI models (for example, Amazon Titan) hosted on Amazon Bedrock were used for query disambiguation and semantic matching for answer lookups and responses. The first data source connected was an Amazon Simple Storage Service (Amazon S3) bucket, where a 100-page RFP manual was uploaded for natural language querying by users.
DataOps (data operations) is an agile, process-oriented methodology for developing and delivering analytics. It brings together DevOps teams with dataengineers and data scientists to provide the tools, processes, and organizational structures to support the data-focused enterprise. What is DataOps?
When we introduced Cloudera DataEngineering (CDE) in the Public Cloud in 2020 it was a culmination of many years of working alongside companies as they deployed Apache Spark based ETL workloads at scale. Each unlocking value in the dataengineering workflows enterprises can start taking advantage of. Usage Patterns.
Based on Bayesian hierarchical modeling, Faculty says the EWS uses aggregate data (for example, COVID-19 positive case numbers, 111 calls and mobility data) to warn hospitals about potential spikes in cases so they can divert staff, beds and equipment needed. Data across the NHS is rather an archipelago.
A few months ago, I wrote about the differences between dataengineers and data scientists. An interesting thing happened: the data scientists started pushing back, arguing that they are, in fact, as skilled as dataengineers at dataengineering. I agree; learn as much as you can.
What is data science? Data science is a method for gleaning insights from structured and unstructured data using approaches ranging from statistical analysis to machinelearning. Organizations need data scientists and analysts with expertise in techniques for analyzing data.
“Coming from engineering and machinelearning backgrounds, [Heartex’s founding team] knew what value machinelearning and AI can bring to the organization,” Malyuk told TechCrunch via email. The labels enable the systems to extrapolate the relationships between the examples (e.g.,
With growing disparate data across everything from edge devices to individual lines of business needing to be consolidated, curated, and delivered for downstream consumption, it’s no wonder that dataengineering has become the most in-demand role across businesses — growing at an estimated rate of 50% year over year.
Data scientists are the core of any AI team. They process and analyze data, build machinelearning (ML) models, and draw conclusions to improve ML models already in production. Dataengineer. Dataengineers build and maintain the systems that make up an organization’s data infrastructure.
Machinelearning is now being used to solve many real-time problems. One big use case is with sensor data. Corporations now use this type of data to notify consumers and employees in real-time. For example, given a transaction, let’s say that an ML model predicts that it is a fraudulent transaction.
Moreover, many need deeper AI-related skills, too, such as for building machinelearning models to serve niche business requirements. It’s less about the machinelearning skill set and more about how you adapt all your roles to take advantage of AI.” Here’s how IT leaders are coping.
Machinelearning (ML) history can be traced back to the 1950s, when the first neural networks and ML algorithms appeared. Analysis of more than 16.000 papers on data science by MIT technologies shows the exponential growth of machinelearning during the last 20 years pumped by big data and deep learning advancements.
Real-time AI involves processing data for making decisions within a given time frame. Real-time AI brings together streaming data and machinelearning algorithms to make fast and automated decisions; examples include recommendations, fraud detection, security monitoring, and chatbots. It isn’t easy.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















































Let's personalize your content