This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
It’s important to understand the differences between a dataengineer and a data scientist. Misunderstanding or not knowing these differences are making teams fail or underperform with big data. I think some of these misconceptions come from the diagrams that are used to describe data scientists and dataengineers.
What is a dataengineer? Dataengineers design, build, and optimize systems for data collection, storage, access, and analytics at scale. They create data pipelines that convert raw data into formats usable by data scientists, data-centric applications, and other data consumers.
What is a dataengineer? Dataengineers design, build, and optimize systems for data collection, storage, access, and analytics at scale. They create data pipelines used by data scientists, data-centric applications, and other data consumers. The dataengineer role.
It shows in his reluctance to run his own servers but it’s perhaps most obvious in his attitude to dataengineering, where he’s nearing the end of a five-year journey to automate or outsource much of the mundane maintenance work and focus internal resources on data analysis. It’s not a good use of our time either.”
Speaker: Mindy Chen, Director of Decision Science, Hudl
In this webinar, we will unpack how data team structures have evolved, drawing on examples from our customers and specifically from the data team at Hudl. Mindy Chen, Director of Decision Science at Hudl, will take us on a journey through the challenges and opportunities she has seen when building a data team from scratch.
Gen AI-related job listings were particularly common in roles such as data scientists and dataengineers, and in software development. In the Randstad survey, for example, 35% of people have been offered AI training up from just 13% in last years survey. For example, the District of Columbia has already invested $1.2
After the launch of CDP DataEngineering (CDE) on AWS a few months ago, we are thrilled to announce that CDE, the only cloud-native service purpose built for enterprise dataengineers, is now available on Microsoft Azure. . Prerequisites for deploying CDP DataEngineering on Azure can be found here.
A great example of this is the semiconductor industry. Educating and training our team With generative AI, for example, its adoption has surged from 50% to 72% in the past year, according to research by McKinsey. For example, when we evaluate third-party vendors, we now ask: Does this vendor comply with AI-related data protections?
Dbt is a popular tool for transforming data in a data warehouse or data lake. It enables dataengineers and analysts to write modular SQL transformations, with built-in support for data testing and documentation. Jaffle Shop Demo To demonstrate our setup, we’ll use the jaffle_shop example.
“The fine art of dataengineering lies in maintaining the balance between data availability and system performance.” The Original Testlogs Table Table Schema The testlogs table has the following simplified schema: Column Data Type Description lot_id string Identifier for the production lot. PASSED, FAILED).
Engineers from across the company came together to share best practices on everything from Data Processing Patterns to Building Reliable Data Pipelines. The result was a series of talks which we are now sharing with the rest of the DataEngineering community! In this video, Sr.
For example, events such as Twitters rebranding to X, and PySparks rise in the dataengineering realm over Spark have all contributed to this decline. In my opinion, sbt (Simple Build Tool) is a perfect example of this evolution. Various business decisions have altered its public perception.
Registered investment advisors, for example, have to jump over a few hurdles when deploying new technologies. For example, a faculty member might want to teach a new section of a course. The most common pattern Im seeing is custom-building capabilities and leveraging other systems for data, she says.
Confidence from business leaders is often focused on the AI models or algorithms, Erolin adds, not the messy groundwork like data quality, integration, or even legacy systems. For example, one of BairesDevs clients was surprised when it spent 30% of an AI project timeline integrating legacy systems, Erolin says.
The team should be structured similarly to traditional IT or dataengineering teams. For example, there should be a clear, consistent procedure for monitoring and retraining models once they are running (this connects with the People element mentioned above).
For example, a retailer might scale up compute resources during the holiday season to manage a spike in sales data or scale down during quieter months to save on costs. For example, data scientists might focus on building complex machine learning models, requiring significant compute resources.
With growing disparate data across everything from edge devices to individual lines of business needing to be consolidated, curated, and delivered for downstream consumption, it’s no wonder that dataengineering has become the most in-demand role across businesses — growing at an estimated rate of 50% year over year.
For example, a retailer might scale up compute resources during the holiday season to manage a spike in sales data or scale down during quieter months to save on costs. For example, data scientists might focus on building complex machine learning models, requiring significant compute resources.
Not cleaning your data enough causes obvious problems, but context is key. “A A lot of organizations spend a lot of time discarding or improving zip codes, but for most data science, the subsection in the zip code doesn’t matter,” says Kashalikar. That’s a classic example of too much good is wasted.”
Data science is the sexy thing companies want. The dataengineering and operations teams don't get much love. The organizations don’t realize that data science stands on the shoulders of DataOps and dataengineering giants. Let's call these operational teams that focus on big data: DataOps teams.
For example, most people now use AI to take meeting notes. According to Leon Roberge, CIO for Toshiba America Business Solutions and Toshiba Global Commerce Solutions, technology leaders should become more visible to the business and lead by example to their teams. Each company has its own way of doing business and its own data sets.
If you’re an executive who has a hard time understanding the underlying processes of data science and get confused with terminology, keep reading. We will try to answer your questions and explain how two critical data jobs are different and where they overlap. Data science vs dataengineering. Feature engineering.
By Abhinaya Shetty , Bharath Mummadisetty At Netflix, our Membership and Finance DataEngineering team harnesses diverse data related to plans, pricing, membership life cycle, and revenue to fuel analytics, power various dashboards, and make data-informed decisions.
Once a successful proof of concept is made, the team often hits a wall regarding its data management. The organization may not collect, store or manage the data in a way that is “AI friendly.” Once a few examples are completed manually, the business can start planning the AI’s path to production.
Job titles like dataengineer, machine learning engineer, and AI product manager have supplanted traditional software developers near the top of the heap as companies rush to adopt AI and cybersecurity professionals remain in high demand. An example of the new reality comes from Salesforce.
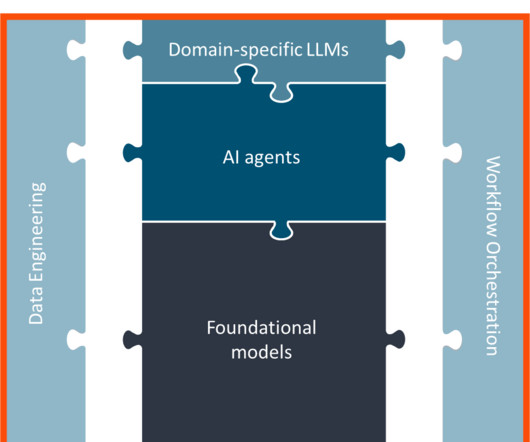
Choreographing data, AI, and enterprise workflows While vertical AI solves for the accuracy, speed, and cost-related challenges associated with large-scale GenAI implementation, it still does not solve for building an end-to-end workflow on its own.
Machine learning can provide companies with a competitive advantage by using the data they’re collecting — for example, purchasing patterns — to generate predictions that power revenue-generating products (e.g. e-commerce recommendations). “It also enables companies to generate more accurate predictions.
In thinking about features, it can be helpful to visualize a table, where the data used by AI systems is organized into rows of examples (data from which the system learns to make predictions) and columns of attributes (data describing those examples). They serve as the interface between data and [AI] models.”
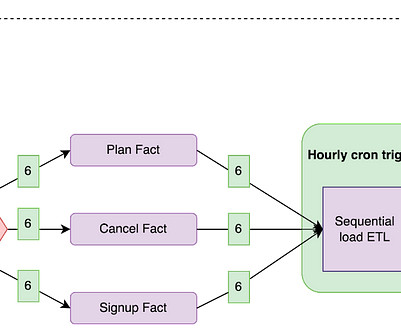
A simple example of this would be parameterizing SQL query within the CDW operator. the developer can include placeholders for different parts of the query, for example the SELECT expression or the table being referenced in the FROM section. Using the special syntax {{.}} SELECT . {{ dag_run.conf['conf1'] }}.
Dataengineers have a big problem. Almost every team in their business needs access to analytics and other information that can be gleaned from their data warehouses, but only a few have technical backgrounds. The New York-based startup announced today that it has raised $7.6
This post was co-written with Vishal Singh, DataEngineering Leader at Data & Analytics team of GoDaddy Generative AI solutions have the potential to transform businesses by boosting productivity and improving customer experiences, and using large language models (LLMs) in these solutions has become increasingly popular.
Today, Cloudera DataEngineering, a data service that streamlines and scales data pipeline development, is available with support for AWS Graviton processors. Cloudera DataEngineering is just the start. Give it a try today.
Its about taking the data you already have and asking: How can we use this to do business better? For example, if a customer service rep is empowered with real-time data, they can anticipate a customers needs and offer tailored solutions. Mike Vaughan serves as Chief Data Officer for Brown & Brown Insurance.
For example, a football team consisting of 11 quarterbacks would get crushed in a game against talented linemen, running backs and receivers. Interestingly, many companies do just that, creating a disconnect between data science teams and IT/DevOps when it comes to AI development. Great teams incorporate a variety of skill sets.
For example, I was trying to understand underwriting in our Canadian operations. In that example, it was better to just go and understand what is happening locally. It covers essential topics like artificial intelligence, our use of data models, our approach to technical debt, and the modernization of legacy systems.
The development- and operations world differ in various aspects: Development ML teams are focused on innovation and speed Dev ML teams have roles like Data Scientists, DataEngineers, Business owners. Taking into account automating operations related to all of the code, data and model is what makes MLOps different from DevOps.
Throughout the COVID-19 recovery era, location data is set to be a core ingredient for driving business intelligence and building sustainable consumer loyalty. Scalable and data-rich location services are helping consumer-facing business drive transformation and growth along three strategic fronts: Creating richer consumer experiences.
Here is a basic example to get started with: manifest_checks: - name: check_model_directories include: ^models permitted_sub_directories: - intermediate - marts - staging This check will validate that all your models exist in one of the sub-directories specified in the permitted_sub_directories key. Loaded config from dbt-bouncer-example.yml.
Mind, data lineage and discoverability become paramount when collaborating on features. Data lineage clarifies what data sources and transformations create a certain feature. You may, for example, want to know what values it can take. This blog post will not focus on data lineage nor discoverability.
I know this because I used to be a dataengineer and built extract-transform-load (ETL) data pipelines for this type of offer optimization. Part of my job involved unpacking encrypted data feeds, removing rows or columns that had missing data, and mapping the fields to our internal data models.
DataOps (data operations) is an agile, process-oriented methodology for developing and delivering analytics. It brings together DevOps teams with dataengineers and data scientists to provide the tools, processes, and organizational structures to support the data-focused enterprise. What is DataOps?
Deployment isolation: Handling multiple users and environments During the development of a new data pipeline, it is common to make tests to check if all dependencies are working correctly. Let’s see through an example. Therefore, we can just run databricks bundle deploy command, to deploy on dev target.
And in a mature ML environment, ML engineers also need to experiment with serving tools that can help find the best performing model in production with minimal trials, he says. Dataengineer. Dataengineers build and maintain the systems that make up an organization’s data infrastructure.
For example, q-aurora-mysql-source. Provide the following details: In the Application details section, for Application name , enter a name for the application (for example, sales_analyzer ). In the Name and description section, configure the following parameters: For Data source name , enter a name (for example, aurora_mysql_sales ).
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content