This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
With growing disparate data across everything from edge devices to individual lines of business needing to be consolidated, curated, and delivered for downstream consumption, it’s no wonder that dataengineering has become the most in-demand role across businesses — growing at an estimated rate of 50% year over year.
Let’s break them down: A data source layer is where the raw data is stored. Those are any of your databases, cloud-storages, and separate files filled with unstructured data. These are both a unified storage for all the corporate data and tools performing Extraction, Transformation, and Loading (ETL).
Today’s general availability announcement covers Iceberg running within key data services in the Cloudera Data Platform (CDP) — including Cloudera Data Warehousing ( CDW ), Cloudera DataEngineering ( CDE ), and Cloudera Machine Learning ( CML ). Read why the future of data lakehouses is open.
4:45pm-5:45pm NFX 202 A day in the life of a Netflix Engineer Dave Hahn , SRE EngineeringManager Abstract : Netflix is a large, ever-changing ecosystem serving millions of customers across the globe through cloud-based systems and a globally distributed CDN. Thursday?—?December
Much of Cloudera’s internal research and development infrastructure for CDP Public Cloud and CDP Private Cloud runs on compute and storage from the big three cloud providers, and at the beginning of 2020 costs were on course to top $25 million per year. When we can do this, we can put resources where they matter most.
This solution uses Amazon Bedrock, Amazon Relational Database Service (Amazon RDS), Amazon DynamoDB , and Amazon Simple Storage Service (Amazon S3). The workflow consists of the following steps: An end-user (data analyst) asks a question in natural language about the data that resides within a data lake.
The data journey from different source systems to a warehouse commonly happens in two ways — ETL and ELT. The former extracts and transforms information before loading it into centralized storage while the latter allows for loading data prior to transformation. Each node has its own disk storage. Database storage layer.
4:45pm-5:45pm NFX 202 A day in the life of a Netflix Engineer Dave Hahn , SRE EngineeringManager Abstract : Netflix is a large, ever-changing ecosystem serving millions of customers across the globe through cloud-based systems and a globally distributed CDN. Thursday?—?December
4:45pm-5:45pm NFX 202 A day in the life of a Netflix Engineer Dave Hahn , SRE EngineeringManager Abstract : Netflix is a large, ever-changing ecosystem serving millions of customers across the globe through cloud-based systems and a globally distributed CDN. Thursday?—?December
These powerful frameworks simplify the complexities of parallel processing, enabling you to write code in a familiar syntax while the underlying enginemanagesdata partitioning, task distribution, and fault tolerance. He helps customers architect and build highly scalable, performant, and secure cloud-based solutions on AWS.
As the picture above clearly shows, organizations have data producers and operational data on the left side and data consumers and analytical data on the right side. Data producers lack ownership over the information they generate which means they are not in charge of its quality. It works like this.
Outdated software applications are creating roadblocks to AI adoption at many organizations, with limited data retention capabilities a central culprit, IT experts say. Moreover, the cost of maintaining outdated software, with a shrinking number of software engineers familiar with the apps, can be expensive, he says.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


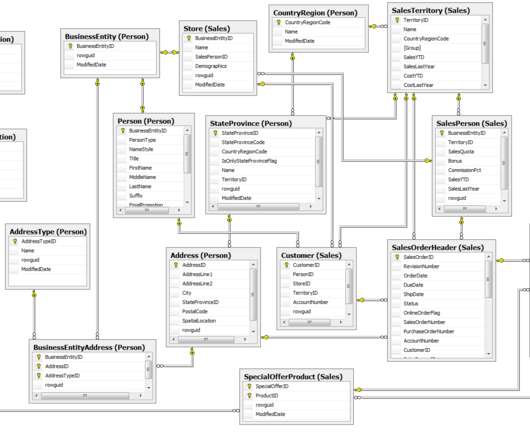



















Let's personalize your content