This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
With many of these tools, “they don’t do the work of connecting and building the relationship,” between data she said, adding that “documentation is still important, but being able to automatically generate [metadata] allows data teams to get value right away.”. Photo via Select Star.
Fishtown Analytics , the Philadelphia-based company behind the dbt open-source dataengineering tool, today announced that it has raised a $29.5 The company is building a platform that allows data analysts to more easily create and disseminate organizational knowledge. million Series A round in April.
It shows in his reluctance to run his own servers but it’s perhaps most obvious in his attitude to dataengineering, where he’s nearing the end of a five-year journey to automate or outsource much of the mundane maintenance work and focus internal resources on data analysis. It’s not a good use of our time either.”
This approach is repeatable, minimizes dependence on manual controls, harnesses technology and AI for data management and integrates seamlessly into the digital product development process. Operational errors because of manual management of data platforms can be extremely costly in the long run.
Baker says productivity is one of the main areas of gen AI deployment for the company, which is now available through Office 365, and allows employees to do such tasks as summarize emails, or help with PowerPoint and Excel documents. With these paid versions, our data remains secure within our own tenant, he says.
Traditional keyword-based search mechanisms are often insufficient for locating relevant documents efficiently, requiring extensive manual review to extract meaningful insights. This solution improves the findability and accessibility of archival records by automating metadata enrichment, document classification, and summarization.
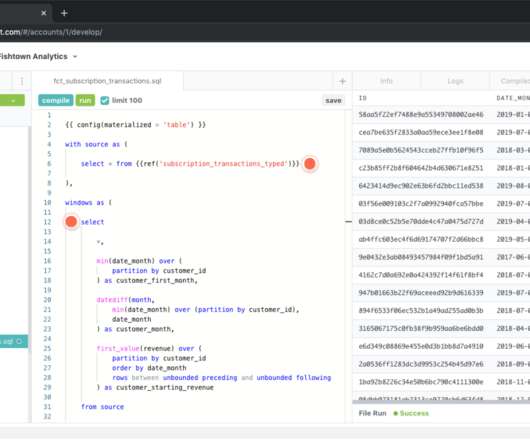
Dbt is a popular tool for transforming data in a data warehouse or data lake. It enables dataengineers and analysts to write modular SQL transformations, with built-in support for data testing and documentation. This makes dbt a natural choice for the Ducklake setup.
If we look at the hierarchy of needs in data science implementations, we’ll see that the next step after gathering your data for analysis is dataengineering. This discipline is not to be underestimated, as it enables effective data storing and reliable data flow while taking charge of the infrastructure.
Maintaining conventions in a dbt project Most teams working in a dbt project will document their conventions. Regardless of location, documentation is a great starting point, writing down the outcome of discussions allows new developers to quickly get up to speed. Sometimes this is in the README.md dbt-checkpoint 0.49 dbt-score 0.94
Principal wanted to use existing internal FAQs, documentation, and unstructured data and build an intelligent chatbot that could provide quick access to the right information for different roles. For queries earning negative feedback, less than 1% involved answers or documentation deemed irrelevant to the original question.
In today’s data-intensive business landscape, organizations face the challenge of extracting valuable insights from diverse data sources scattered across their infrastructure. Create and load sample data In this post, we use two sample datasets: a total sales dataset CSV file and a sales target document in PDF format.
Neudesic leverages extensive industry expertise and advanced skills in Microsoft Azure, AI, dataengineering, and analytics to help businesses meet the growing demands of AI. For instance, using AI to automate document preparation can cut processing time from hours to minutes. First, set clear objectives and success metrics.
What is Cloudera DataEngineering (CDE) ? Cloudera DataEngineering is a serverless service for Cloudera Data Platform (CDP) that allows you to submit jobs to auto-scaling virtual clusters. Refer to the following cloudera blog to understand the full potential of Cloudera DataEngineering. .
collect() Next, you can visualize the size of each document to understand the volume of data you’re processing. You can generate charts and visualize your data within your PySpark notebook cell using static visualization tools like matplotlib and seaborn. latest USER root RUN dnf install python3.11 python3.11-pip
That’s why a data specialist with big data skills is one of the most sought-after IT candidates. DataEngineering positions have grown by half and they typically require big data skills. Dataengineering vs big dataengineering. Big data processing. maintaining data pipeline.
Big data architect: The big data architect designs and implements data architectures supporting the storage, processing, and analysis of large volumes of data. Data architect vs. dataengineer The data architect and dataengineer roles are closely related.
Not cleaning your data enough causes obvious problems, but context is key. “You Rather than doing masses of data cleaning up front and only then starting development, take an iterative approach with incremental data cleaning and quick experiments.
Our help documentation site, help.github.com , is now available in Brazilian Portuguese. Brazil is an emerging market and with the addition of documentation in Portuguese, we hope to welcome more developers in Brazil to the GitHub community and provide the resources they need to code, create, and collaborate. GitHub in Brazil.
Introduction: We often end up creating a problem while working on data. So, here are few best practices for dataengineering using snowflake: 1.Transform Please see online documentation for detailed instructions loading data into Snowflake.
The company was founded in 2021 by Brian Ip, a former Goldman Sachs executive, and dataengineer YC Chan. They also don’t have features for performance appraisals, recruitment, onboarding and employee document management. Many were still using spreadsheets or basic payroll software.
If you want to know more about Poetry, check out the official documentation. From Databricks official bundles documentation: “Databricks Assets Bundles are an infrastructure-as-code (IaC) approach to managing your Databricks projects. Step 2: Configure a bundle Everything starts with the databricks.yml file.
And in a mature ML environment, ML engineers also need to experiment with serving tools that can help find the best performing model in production with minimal trials, he says. Dataengineer. Dataengineers build and maintain the systems that make up an organization’s data infrastructure.
Cloudera DataEngineering (CDE) is a cloud-native service purpose-built for enterprise dataengineering teams. If you need to use credentials for the docker repository then review these additional instructions from the Cloudera documentation to follow additional steps. image-engine="spark2".
In this blog post, we want to tell you about our recent effort to do metadata-driven data masking in a way that is scalable, consistent and reproducible. Using dbt to define and documentdata classifications and Databricks to enforce dynamic masking, we ensure that access is controlled automatically based on metadata.
Database developers should have experience with NoSQL databases, Oracle Database, big data infrastructure, and big dataengines such as Hadoop. The role typically requires a bachelor’s degree in computer science, electrical engineering, computer engineering or a related discipline.
Early use cases include code generation and documentation, test case generation and test automation, as well as code optimization and refactoring, among others. Additionally, we are looking into training LLMs [large language models] on our code base to unlock further productivity boosts for our developers and dataengineers.
Image processing AI is being used to analyze and process images, while also pulling data and information from visuals and text documents, and interpreting or manipulating that data as needed. It also has important applications in the healthcare industry, contributing to analyzing medical imaging from MRI and CT scans.
Every developer (the origin of our name) has a few basic needs, like clear documentation, help getting started and use cases to spark creativity. If your customers are dataengineers, it probably won’t make sense to discuss front-end web technologies.
Data Modelers: They design and create conceptual, logical, and physical data models that organize and structure data for best performance, scalability, and ease of access. In the 1990s, data modeling was a specialized role. Ownership: decide who owns the documentation based on the content type.
(In computing, a “data warehouse” refers to systems used for reporting and data analysis — analysis usually germane to business intelligence.) Their clients often encountered challenges in transforming data, Petrossian says, as well as documenting these transformations in a way that made intuitive sense.
I'm extremely determined that I want to start my own thing (meaning, don't try to hire me, it's probably a waste of time), and it's highly likely it will be something in the dataengineering/science tools/infra space. I've spent most of my career working in data in some shape or form. At Spotify, I was entirely focused on it.
Software is understood as a series of executable programming codes, related libraries, and documentation. Software engineering is an engineering department related to improving software products using well-described clinical ideas, strategies, and procedures. Software is more than just program code. What is Computer Science?
MLEs are usually a part of a data science team which includes dataengineers , data architects, data and business analysts, and data scientists. Who does what in a data science team. Machine learning engineers are relatively new to data-driven companies. Making business recommendations.
Still, to ensure workers gain the most out of the tools, Mayar suggested multimodal LLMs combining structured datasets and unstructured data should be designed smaller and for specific tasks. Gen AI is not a magic bullet,” she said at the summit. Thomson Reuters is one organization targeting gen AI for efficiency.
The project scope defines the degree of involvement for a certain role, as engineers with similar technology stacks and domain knowledge can be interchangeable. Developing BI interfaces requires a deep experience in software engineering, databases, and data analysis. Report curation and data modeling. Dataengineer.
Opting for a centralized data and reporting model rather than training and embedding analysts in individual departments has allowed us to stay nimble and responsive to meet urgent needs, and prevented us from spending valuable resources on low-value data projects which often had little organizational impact,” Higginson says.
This combination allows businesses to process vast amounts of text data quickly and efficiently, unlocking advanced insights through tasks like named entity recognition, text summarization, question answering, and document classification. For detailed guidance on this process, refer to the relevant section in our documentation.
Capture patient documentation with a digital scribe. Digital solutions to implement generative AI in healthcare EXL, a leading data analytics and digital solutions company , has developed an AI platform that combines foundational generative AI models with our expertise in dataengineering, AI solutions, and proprietary data sets.
You can use the Amazon Q Business ServiceNow Online data source connector to connect to the ServiceNow Online platform and index ServiceNow entities such as knowledge articles, Service Catalogs, and incident entries, along with the metadata and document access control lists (ACLs).
Data architect and other data science roles compared Data architect vs dataengineerDataengineer is an IT specialist that develops, tests, and maintains data pipelines to bring together data from various sources and make it available for data scientists and other specialists.
Dataquest provides these 4: Data Analyst (Python) Data Analyst (R) DataEngineerData Scientist (Python). Dataquest provides a wide range of courses, and some of them are focused on: Python R Git SQL Kaggle Machine Learning. You have access to specific paths.
Among them are cybersecurity experts, technicians, people in legal, auditing or compliance, as well as those with a high degree of specialization in AI where data scientists and dataengineers predominate.
Kedro generates simpler boilerplate code and has thorough documentation and guides. If you want to improve your data pipeline development skills and simplify adapting code to different cloud platforms, Kedro is a good choice. Not everything is unicorns and rainbows, I know.
Knowledge that is not available: Like many other companies, InnoGames also uses wiki software to create documentation, record meeting minutes, discuss concepts and much more. QueryMind training is based on information about the table structure, sample queries and documentation. QueryMind opens up new possibilities at this point.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content