This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This summer, Databricks announced the open-sourcing of Unity Catalog. In this post, we’ll dive into how you can integrate DuckDB with the open-source Unity Catalog, walking you through our hands-on experience, sharing the setup process, and exploring both the opportunities and challenges of combining these two technologies.
Like similar startups, y42 extends the idea data warehouse, which was traditionally used for analytics, and helps businesses operationalize this data. At the core of the service is a lot of opensource and the company, for example, contributes to GitLabs’ Meltano platform for building data pipelines.
In this last installment, we’ll discuss a demo application that uses PySpark.ML to make a classification model based off of training data stored in both Cloudera’s Operational Database (powered by Apache HBase) and Apache HDFS. As a result, I decided to use an open-source Occupancy Detection Data Set to build this application.
However, this requires a lot of custom engineering work and is not an easy task. Besides that you need to create a dashboard on top of this artifact data, to get meaningful insights out of it. Luckily, there is an open-source solution for this called Elementary Data.
This blog post focuses on how the Kafka ecosystem can help solve the impedance mismatch between data scientists, dataengineers and production engineers. Impedance mismatch between data scientists, dataengineers and production engineers. For now, we’ll focus on Kafka.
A Big Data Analytics pipeline– from ingestion of data to embedding analytics consists of three steps DataEngineering : The first step is flexible data on-boarding that accelerates time to value. This will require another product for data governance. This is colloquially called data wrangling.
What is Databricks Databricks is an analytics platform with a unified set of tools for dataengineering, data management , data science, and machine learning. It combines the best elements of a data warehouse, a centralized repository for structured data, and a data lake used to host large amounts of raw data.
The prospect of taking on a costly data infrastructure project is daunting. If your company is starting out on this path, it’s important to recognize that there are now widely available opensource tools and commercial platforms that can power this foundation for you. AI doesn’t fit that model. How do you select what to work on?
The skills and resources required for opensource don’t match core ISP priorities. With the advent of opensource big dataengines, the power of big data network analytics has seemed tantalizingly close. And that keeps generic opensource tools from being a fully viable path.
We see AI applications like chatbots being built on top of closed-source or opensource foundational models. Those models are trained or augmented with data from a data management platform. The data management platform, models, and end applications are powered by cloud infrastructure and/or specialized hardware.
Usually, data integration software is divided into on-premise, cloud-based, and open-source types. On-premise data integration tools. As the name suggests, these tools aim at integrating data from different on-premise source systems. Open-sourcedata integration tools. Suitable for.
However, other query engines such as Hive and Spark can also benefit from this Iceberg improvement as well. Repeated metadata reads problem in Impala + Iceberg Apache Impala is an opensource, distributed, massively parallel SQL query engine. It includes a live demo recording of Iceberg capabilities.
For example, there isn’t much data you operate with: You maintain your reporting in Excel spreadsheets, store some data in a CRM, and also use a BI tool. In such a case, you can delegate integration work to a dataengineer who will manually upload data into, say, a CSV file and move it to a BI system.
That’s why network operations has for years involved deployment of a mix of different commercial, open-source, and home-grown tools. Another API-based option that we’ve developed for our customers is Kentik Connect Pro, a plug-in that we worked with Grafana to develop for their popular open-sourcedata graphing software.
Gema Parreño Piqueras – Lead Data Science @Apiumhub Gema Parreno is currently a Lead Data Scientist at Apiumhub, passionate about machine learning and video games, with three years of experience at BBVA and later at Google in ML Prototype. She started her own startup (Cubicus) in 2013. Twitter: [link] Linkedin: [link].
But before you dive in, we recommend you reviewing our more beginner-friendly articles on data transformation: Complete Guide to Business Intelligence and Analytics: Strategy, Steps, Processes, and Tools. What is DataEngineering: Explaining the Data Pipeline, Data Warehouse, and DataEngineer Role.
Kentik’s founders, who ran large network operations at Akamai, Netflix, YouTube, and Cloudflare, well understand the challenges faced by teams working with siloed legacy tools and fragmented data sets. The time has come for them to put away their point solutions, spreadsheets, and opensource tools.
Of course just opening one’s mind to the dream isn’t the same as having the solution. You could try to construct it yourself, for example by building it with opensource tools. Learn more by digging into our product , seeing what our customers think, or reading a white paper on the Kentik DataEngine.
Developed as a model for “processing and generating large data sets,” MapReduce was built around the core idea of using a map function to process a key/value pair into a set of intermediate key/value pairs, and then a reduce function to merge all intermediate values associated with a given intermediate key.
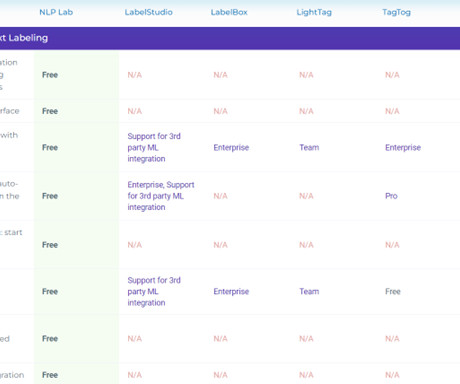
Label Studio Label Studio is an opensourcedata annotation tool for labeling multiple types of data. The two important functions of this tool are: – Performing different types of labeling with various data formats. – It offers documentation and live demos for ease of use.
What was worth noting was that (anecdotally) even engineers from large organisations were not looking for full workload portability (i.e. There were also two patterns of adoption of HashiCorp tooling I observed from engineers that I chatted to: Infrastructure-driven?—?in
As the article is big enough, we suggest you to navigate using this outline, if needed: What is data visualization: how it works, types of data to visualize, visualization formats. Tools for data visualization: paid, free, and open-source instruments. Data visualization pitfalls: issues and challenges to consider.
A quick look at bigram usage (word pairs) doesn’t really distinguish between “data science,” “dataengineering,” “data analysis,” and other terms; the most common word pair with “data” is “data governance,” followed by “data science.” It’s worth looking at alternatives to Oracle though.
You can hardly compare dataengineering toil with something as easy as breathing or as fast as the wind. The platform went live in 2015 at Airbnb, the biggest home-sharing and vacation rental site, as an orchestrator for increasingly complex data pipelines. How dataengineering works. Source: Apache Airflow.
Drawing on more than a decade of experience in building and deploying massive scale data platforms on economical budgets, Cloudera has designed and delivered a cost-cutting cloud-native solution – Cloudera Data Warehouse (CDW), part of the new Cloudera Data Platform (CDP). Watch this video to get an overview of CDW. .
As advanced analytics and AI continue to drive enterprise strategy, leaders are tasked with building flexible, resilient data pipelines that accelerate trusted insights. A New Level of Productivity with Remote Access The new Cloudera DataEngineering 1.23 Why Cloudera DataEngineering?
In this post, we explore how CrewAIs opensource agentic framework , combined with Amazon Bedrock , enables the creation of sophisticated multi-agent systems that can transform how businesses operate. A US Army veteran, Tony brings a diverse background in healthcare, dataengineering, and AI. billion in 2024 to $47.1
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



































Let's personalize your content