This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
You know the one, the mathematician / statistician / computer scientist / dataengineer / industry expert. Some companies are starting to segregate the responsibilities of the unicorn data scientist into multiple roles (dataengineer, ML engineer, ML architect, visualization developer, etc.),
Building a scalable, reliable and performant machinelearning (ML) infrastructure is not easy. It takes much more effort than just building an analytic model with Python and your favorite machinelearning framework. Impedance mismatch between data scientists, dataengineers and production engineers.
The second blog dealt with creating and managing Data Enrichment pipelines. The third video in the series highlighted Reporting and Data Visualization. Specifically, we’ll focus on training MachineLearning (ML) models to forecast ECC part production demand across all of its factories. Data Collection – streaming data.
In this last installment, we’ll discuss a demo application that uses PySpark.ML to make a classification model based off of training data stored in both Cloudera’s Operational Database (powered by Apache HBase) and Apache HDFS. Machinelearning is now being used to solve many real-time problems. Background / Overview.
Databricks is now a top choice for data teams. Its user-friendly, collaborative platform simplifies building data pipelines and machinelearning models. Many data practitioners, myself included, have faced various deployment and resource management strategies. You must build a data ingestion app.
If you’re already a software product manager (PM), you have a head start on becoming a PM for artificial intelligence (AI) or machinelearning (ML). AI products are automated systems that collect and learn from data to make user-facing decisions. Machinelearning adds uncertainty.
With App Studio, technical professionals such as IT project managers, dataengineers, enterprise architects, and solution architects can quickly develop applications tailored to their organizations needswithout requiring deep software development skills.
In the beginning, CDP ran only on AWS with a set of services that supported a handful of use cases and workload types: CDP Data Warehouse: a kubernetes-based service that allows business analysts to deploy data warehouses with secure, self-service access to enterprise data. Predict – DataEngineering (Apache Spark).
Rule-based fraud detection software is being replaced or augmented by machine-learning algorithms that do a better job of recognizing fraud patterns that can be correlated across several data sources. DataOps is required to engineer and prepare the data so that the machinelearning algorithms can be efficient and effective.
We've been focusing a lot on machinelearning recently, in particular model inference — Stable Diffusion is obviously the coolest thing right now, but we also support a wide range of other things: Using OpenAI's Whisper model for transcription , Dreambooth , object detection (with a webcam demo!).
As a partner of the McLaren Formula 1 Team , DataRobot is excited to share an exclusive view of how McLaren uses machinelearning and AI. Learn how the McLaren Formula 1 Team is delivering AI-powered predictions and insights to maximize performance and optimize simulations. New DataRobot AI Cloud Product Announcements.
As AI continues to advance at such an aggressive pace, solutions built on machinelearning are quickly becoming the new norm. Data scientists and dataengineers want full control over every aspect of their machinelearning solutions and want coding interfaces so that they can use their favorite libraries and languages.
In this blog we will take you through a persona-based data adventure, with short demos attached, to show you the A-Z data worker workflow expedited and made easier through self-service, seamless integration, and cloud-native technologies. Company data exists in the data lake. The Data Scientist.
Going from prototype to production is perilous when it comes to artificial intelligence (AI) and machinelearning (ML). However, many organizations struggle moving from a prototype on a single machine to a scalable, production-grade deployment. And for the few models that are ever deployed, it takes 90 days or more to get there.
Data Innovation Summit topics. Same as last year, the event offers six workshops (crash-course) themes, each dedicated to a unique domain area: Data-driven Strategy, Analytics & Visualisation, MachineLearning, IoT Analytics & Data Management, Data Management and DataEngineering.
We wanted to provide a modern cloud-based platform leveraging the latest in machinelearning, analytics and automation to fight the many cyber attacks businesses face every day. Cortex XDR’s Third-Party DataEngine Now Delivers the Ability to Ingest, Normalize, Correlate, Query and Analyze Data from Virtually Any Source.
Predictive Analytics – predictive analytics based upon AI and machinelearning (Fraud detection, predictive maintenance, demand based inventory optimization as examples). Security & Governance – an integrated set of security, management and governance technologies across the entire data lifecycle.
The data management platform, models, and end applications are powered by cloud infrastructure and/or specialized hardware. In a stack including Cloudera Data Platform the applications and underlying models can also be deployed from the data management platform via Cloudera MachineLearning.
Databricks is now a top choice for data teams. Its user-friendly, collaborative platform simplifies building data pipelines and machinelearning models. Many data practitioners, myself included, have faced various deployment and resource management strategies. You must build a data ingestion app.
Databricks is now a top choice for data teams. Its user-friendly, collaborative platform simplifies building data pipelines and machinelearning models. Many data practitioners, myself included, have faced various deployment and resource management strategies. You must build a data ingestion app.
What is Databricks Databricks is an analytics platform with a unified set of tools for dataengineering, data management , data science, and machinelearning. Besides that, it’s fully compatible with various data ingestion and ETL tools. How dataengineering works in 14 minutes.
At Cloudera, we also provide machinelearning as part of our lakehouse, so data scientists get easy access to reliable data in the data lakehouse to quickly launch new machinelearning projects and build and deploy new models for advanced analytics.
Data scientists play a critical role in the DataOps ecosystem, leveraging advanced analytics and machinelearning techniques to gain insights from large and complex data sets. DataOps team roles In a DataOps team, several key roles work together to ensure the data pipeline is efficient, reliable, and scalable.
While these instructions are carried out for Cloudera Data Platform (CDP), Cloudera DataEngineering, and Cloudera Data Warehouse, one can extrapolate them easily to other services and other use cases as well. Watch our webinar Supercharge Your Analytics with Open Data Lakehouse Powered by Apache Iceberg.
Enterprise data architects, dataengineers, and business leaders from around the globe gathered in New York last week for the 3-day Strata Data Conference , which featured new technologies, innovations, and many collaborative ideas. DataRobot Data Prep. free trial. Try now for free.
AI Cloud brings together any type of data, from any source, giving you a unique, global view of insights that drive your business. All of this is part of a unified, integrated platform spanning dataengineering, machinelearning, decision intelligence, and continuous AI – the entire AI lifecycle.
Almost 90% of the machinelearning models encounter delays and never make it into production. Developing a machinelearning model requires a big amount of training data. Therefore, the data needs to be properly labeled/categorized for a particular use case.
It outperforms other data warehouses on all sizes and types of data, including structured and unstructured, while scaling cost-effectively past petabytes. Running on CDW is fully integrated with streaming, dataengineering, and machinelearning analytics. Demo Video. Solution brief. Contributors: .
Watch our webinar Supercharge Your Analytics with Open Data Lakehouse Powered by Apache Iceberg. It includes a live demo recording of Iceberg capabilities. Try Cloudera Data Warehouse (CDW), Cloudera DataEngineering (CDE), and Cloudera MachineLearning (CML) by signing up for a 60 day trial , or test drive CDP.
Gema Parreño Piqueras – Lead Data Science @Apiumhub Gema Parreno is currently a Lead Data Scientist at Apiumhub, passionate about machinelearning and video games, with three years of experience at BBVA and later at Google in ML Prototype. Twitter: [link] Linkedin: [link]. Twitter: ??
Source: McKinsy&Company For example, a data science team may spend 70 to 80 percent of their time preparing data for machinelearning projects , with a prevailing part of this time being spent on data cleansing alone. Learn how data is prepared for machinelearning in our dedicated video.
What was worth noting was that (anecdotally) even engineers from large organisations were not looking for full workload portability (i.e. There were also two patterns of adoption of HashiCorp tooling I observed from engineers that I chatted to: Infrastructure-driven?—?in
The AI evolution: Transforming software engineering In the past year, the landscape of tech has seen unprecedented upheaval. Generative AI (GenAI) has catapulted data science, machinelearning, and AI into the limelight, sparking conversations and at all levels of business and democratizing access to the power of AI.
TIBCO DQ will become the new data quality product family, through an evolution of our current data quality offerings, significantly enhancing current capabilities available throughout the TIBCO data fabric with built-in AI and ML to automate quality, detection, monitoring, and anomaly resolution.
A quick look at bigram usage (word pairs) doesn’t really distinguish between “data science,” “dataengineering,” “data analysis,” and other terms; the most common word pair with “data” is “data governance,” followed by “data science.” But these topics are relatively small and narrow.
It’s reasonable to have something to demo in two weeks (or whatever interval you choose). This year’s growth in Python usage was buoyed by its increasing popularity among data scientists and machinelearning (ML) and artificial intelligence (AI) engineers. Data quality might get worse before it gets better.
You can hardly compare dataengineering toil with something as easy as breathing or as fast as the wind. The platform went live in 2015 at Airbnb, the biggest home-sharing and vacation rental site, as an orchestrator for increasingly complex data pipelines. How dataengineering works. What is Apache Airflow?
These file formats not only help avoid data duplication into proprietary storage formats but also provide highly efficient storage formats. Multiple analytical engines (data warehousing, machinelearning, dataengineering, and so on) can operate on the same data in these file formats.
Setup Ranger Policy to allow “rest-demo” access for sharing: Create a policy that will allow the “rest-demo” role to have read access to the Carriers table, but will have no access to read the Airports table. In this case I’m using a role named – “UnitedAirlinesRole” that I can use to share data.
Our use case demo implements a specialized team of three agents, each with distinct responsibilities that mirror roles you might find in a professional security consulting firm: Infrastructure mapper Acts as our system architect, methodically documenting AWS resources and their configurations.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















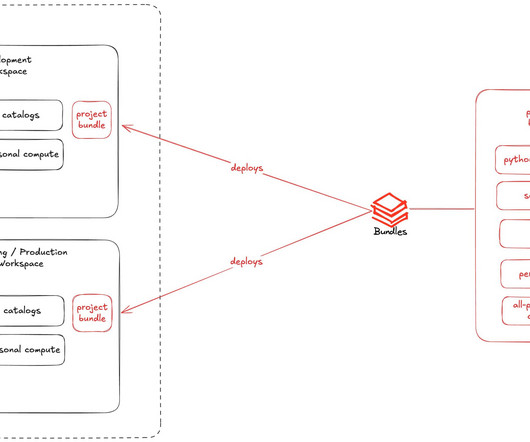
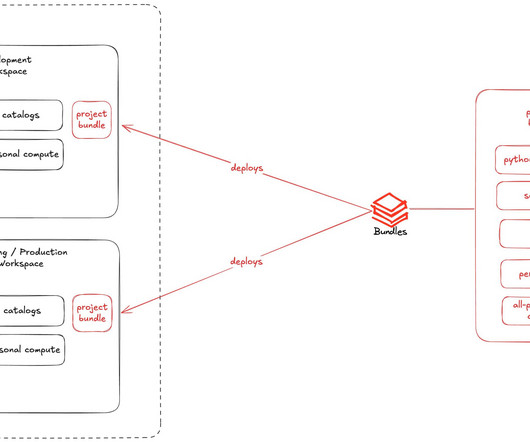






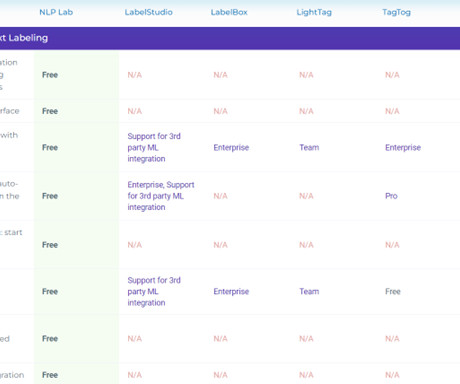



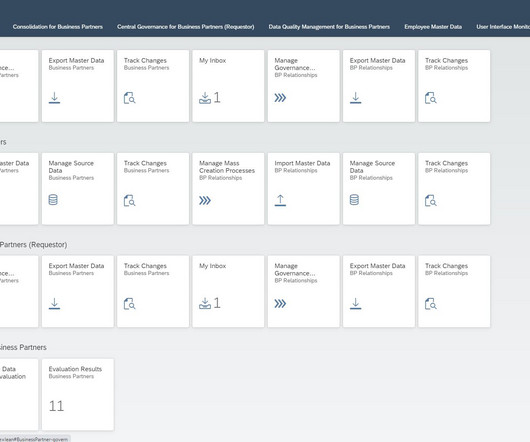

















Let's personalize your content