This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Dataengineering is one of these new disciplines that has gone from buzzword to mission critical in just a few years. As data has exploded, so has their challenge of doing this key work, which is why a new set of tools has arrived to make dataengineering easier, faster and better than ever.
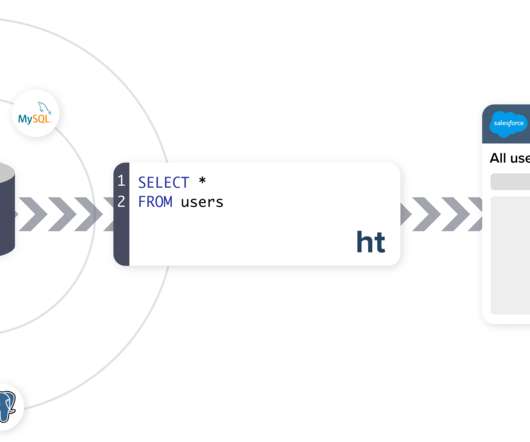
Dbt is a popular tool for transforming data in a data warehouse or data lake. It enables dataengineers and analysts to write modular SQL transformations, with built-in support for data testing and documentation. Jaffle Shop Demo To demonstrate our setup, we’ll use the jaffle_shop example.
.” For example, a factory that wishes to embed smart fault inspection on a production assembly line will be able to demo the AI project pretty fast by using a single camera on a machine for a few minutes. This will require many months or even years to bring the value the AI provides in the demo across the finish line.
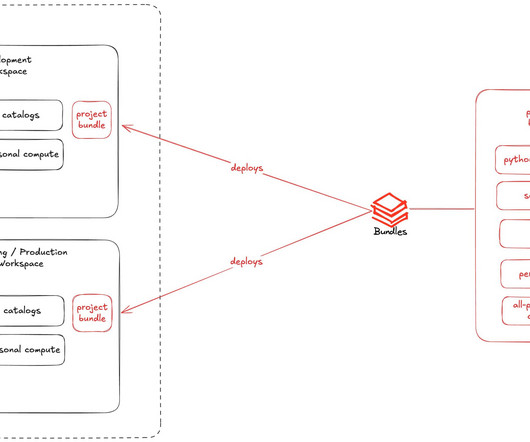
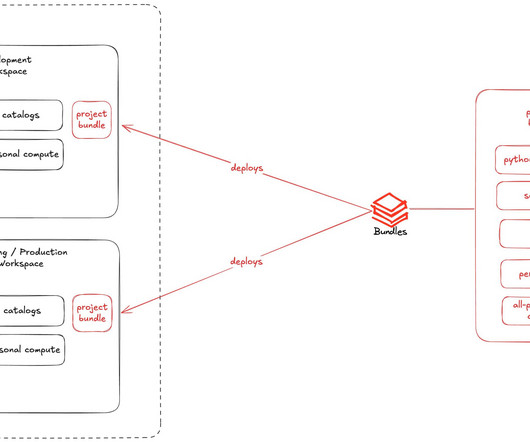
Databricks Asset Bundles: How We’ll work on a demo use case to show the power of bundles. You must build a data ingestion app. In our demo it will contain the.whl files related to our Python wheel package being deployed. Alternatively, you could deploy manually, but that was error-prone and hard to maintain long-term.
There’s no industry term for that yet, but we really believe that that’s the future of where dataengineering is going. Hightouch originally raised its round after its participation in the Y Combinator demo day but decided not to disclose it until it felt like it had found the right product/market fit.
Given his background, it’s maybe no surprise that y42’s focus is on making life easier for dataengineers and, at the same time, putting the power of these platforms in the hands of business analysts. y42 is a powerful single source of truth for data experts and non-data experts alike.
In this last installment, we’ll discuss a demo application that uses PySpark.ML to make a classification model based off of training data stored in both Cloudera’s Operational Database (powered by Apache HBase) and Apache HDFS. In this demo, half of this training data is stored in HDFS and the other half is stored in an HBase table.
With App Studio, technical professionals such as IT project managers, dataengineers, enterprise architects, and solution architects can quickly develop applications tailored to their organizations needswithout requiring deep software development skills.
We are going to use an Operational Database COD instance and Apache Spark present in the Cloudera DataEngineering experience. . Ensure that you have a Cloudera DataEngineering experience instance already provisioned, and a virtual cluster is already created. Cloudera DataEngineering. Prerequisites .
You know the one, the mathematician / statistician / computer scientist / dataengineer / industry expert. Some companies are starting to segregate the responsibilities of the unicorn data scientist into multiple roles (dataengineer, ML engineer, ML architect, visualization developer, etc.),
Enrich – DataEngineering (Apache Spark and Apache Hive). Report – DataEngineering (Hive3), Data Mart (Apache Impala) and Real-Time Data Mart (Apache Impala with Apache Kudu) . Serve – Operational Database (Apache HBASE), Data Exploration (Apache Solr) . New Services.
This blog post focuses on how the Kafka ecosystem can help solve the impedance mismatch between data scientists, dataengineers and production engineers. Impedance mismatch between data scientists, dataengineers and production engineers. For now, we’ll focus on Kafka.
We've been focusing a lot on machine learning recently, in particular model inference — Stable Diffusion is obviously the coolest thing right now, but we also support a wide range of other things: Using OpenAI's Whisper model for transcription , Dreambooth , object detection (with a webcam demo!). I will be posting a lot more about it!
In this blog we will take you through a persona-based data adventure, with short demos attached, to show you the A-Z data worker workflow expedited and made easier through self-service, seamless integration, and cloud-native technologies. Data Catalog profilers have been run on existing databases in the Data Lake.
But is there more to generative AI than a fancy demo on Twitter? And how will it impact data? Maybe you’ve noticed the world has dumped the internet, mobile, social, cloud, and even crypto in favor of an obsession with generative AI.
Here at Kentik, we’ve applied many of the same concepts to Kentik DataEngine™ (KDE), a datastore optimized for querying IP flow records (NetFlow v5/9, sFlow, IPFIX) and related network data (GeoIP, BGP, SNMP). In this series, we’ll take a tour of KDE and also quantify some of its performance and scale characteristics.
You may recall from the previous blogs in this series that ECC is leveraging the Cloudera Data Platform (CDP) to cover all the stages of its data life cycle. Data Collection – streaming data. Data Enrichment – dataengineering. Reporting – data warehousing & dashboarding.
To address the second challenge, Belcorp hired new talent to bridge the knowledge gap among different teams and established a technology hub to recruit first-rate data scientists and dataengineers to aid with the project’s design and implementation.
Data scientists and dataengineers want full control over every aspect of their machine learning solutions and want coding interfaces so that they can use their favorite libraries and languages. At the same time, business and data analysts want to access intuitive, point-and-click tools that use automated best practices.
This includes high-demand roles like Full stack- Django/React, Full stack- Django/Angular, Full stack- Django/Spring/ React, Full stack- Django/Spring/Angular, Dataengineer, and DevOps engineer. We have 20 pre-defined roles available now, and we intend to add more to the stack. And that’s all.
Join the platform breakout session track to see an end-to-end product demo, dive deep into Continuous AI, learn how to create scalable AI projects, and understand how to manage governance and risk. In a robust virtual expo, visit with experts in dataengineering, machine learning, ML Ops, and AI-powered apps.
A Big Data Analytics pipeline– from ingestion of data to embedding analytics consists of three steps DataEngineering : The first step is flexible data on-boarding that accelerates time to value. This will require another product for data governance. This is colloquially called data wrangling.
Matt works at an accounting firm, as a dataengineer. I want Jackie’s front-page changes to be in the demo I’m about to do. He makes reports for people who don’t read said reports. Accounting firms specialize in different areas of accountancy, and Matt’s firm is a general firm with mid-size clients. Why is that so difficult?”
While Kubernetes and Kubeflow would seem to be an ideal way to address some of the obstacles, the steep learning curve can introduce complexities for data scientists and dataengineers who might not have the bandwidth or design to learn how to manage it.
It is also a good starting point for debugging data quality issues, because it offers an easy way to copy the actual compiled SQL that was executed for a given test. packages: - package: elementary-data/elementary version: 0.13.1 In case you do not have a packages.yml file yet, you can create one in the root of your dbt project.
Databricks Asset Bundles: How We’ll work on a demo use case to show the power of bundles. You must build a data ingestion app. In our demo it will contain the.whl files related to our Python wheel package being deployed. Alternatively, you could deploy manually, but that was error-prone and hard to maintain long-term.
Databricks Asset Bundles: How We’ll work on a demo use case to show the power of bundles. You must build a data ingestion app. In our demo it will contain the.whl files related to our Python wheel package being deployed. Alternatively, you could deploy manually, but that was error-prone and hard to maintain long-term.
The need for speed The Kentik Data Explorer is Kentik’s interface between you as an engineer, whether that’s network, systems, cloud, security, or SRE, and the database of information you’ve collected with the Kentik platform. But the real key here is that the Kentik Data Explorer was purpose-built for querying a massive database.
Data Innovation Summit topics. Same as last year, the event offers six workshops (crash-course) themes, each dedicated to a unique domain area: Data-driven Strategy, Analytics & Visualisation, Machine Learning, IoT Analytics & Data Management, Data Management and DataEngineering.
An AI pilot project, even one that sounds simple, probably won’t be something you can demo quickly. A demo, or even a first release, can be based on heuristics or simple models (linear regression, or even averages). Having something you can demo takes some of the pressure off your machine learning team.
Cortex XDR’s Third-Party DataEngine Now Delivers the Ability to Ingest, Normalize, Correlate, Query and Analyze Data from Virtually Any Source. An overview and demo of Cortex XDR 3.0 — See the new capabilities first-hand and discover how our third-generation XDR innovations equip defenders to level the playing field.
This enabled us to ingest data faster, more reliably, and in deeper detail, while saving on licenses. The solution was prototyped in Cloudera Data Science Workbench (CDSW) , and is built using Python and PySpark, which is scheduled using Cloudera DataEngineering.
DataOps team roles In a DataOps team, several key roles work together to ensure the data pipeline is efficient, reliable, and scalable. These roles include data specialists, dataengineers, and principal dataengineers. They work closely with dataengineers to ensure the pipeline is robust and scalable.
While these instructions are carried out for Cloudera Data Platform (CDP), Cloudera DataEngineering, and Cloudera Data Warehouse, one can extrapolate them easily to other services and other use cases as well. Watch our webinar Supercharge Your Analytics with Open Data Lakehouse Powered by Apache Iceberg.
I’ll keep the sizes as small as possible, since it is only for demo purposes. It provides a collaborative environment for teams to work together, accelerating the development and deployment of data-driven solutions. First, click on SQL Warehouses on the left bar, then Create SQL warehouse button. This will open a new window.
Value in “getting it right” include using data from any enterprise source thus breaking down data silos, using all data whether it be streaming or batch-oriented, and the ability to send that data to the right place producing the desired down stream insight. . More Data Collection Resources.
CDP’s components that support a data lakehouse architecture include: Apache Iceberg table format that is integrated into CDP to provide structure to the massive amounts of structured, unstructured data in your data lake. The post Educating ChatGPT on Data Lakehouse appeared first on Cloudera Blog.
However, different departments or user groups may have access to different subsets of data, making it difficult to join and analyze data between them and limiting collaboration between different teams (such as for workflows requiring dataengineers, data scientists, and SQL users).
What is Databricks Databricks is an analytics platform with a unified set of tools for dataengineering, data management , data science, and machine learning. It combines the best elements of a data warehouse, a centralized repository for structured data, and a data lake used to host large amounts of raw data.
An information-packed set of sessions that explained everything from the fundamentals of Flink to the most advanced concepts and some hands-on demos. We also wrote a white paper comparing the different stream processing engines in the market today and this was much appreciated by our customers.
Founding AI ecosystem partners | NVIDIA, AWS, Pinecone NVIDIA | Specialized Hardware Highlights: Currently, NVIDIA GPUs are already available in Cloudera Data Platform (CDP), allowing Cloudera customers to get eight times the performance on dataengineering workloads at less than 50 percent incremental cost relative to modern CPU-only alternatives.
Enterprise data architects, dataengineers, and business leaders from around the globe gathered in New York last week for the 3-day Strata Data Conference , which featured new technologies, innovations, and many collaborative ideas.
Service providers of all stripes can benefit from big data-powered network insights in similar ways as KDDI, both in planning as well as operational realms. If you’d like to learn more, check out our products , read our Kentik DataEngine (KDE) white paper, and dig into why NFV needs advanced analytics.
It outperforms other data warehouses on all sizes and types of data, including structured and unstructured, while scaling cost-effectively past petabytes. Running on CDW is fully integrated with streaming, dataengineering, and machine learning analytics. To learn more about CDP & the Smart Data Transition Toolkit: .
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content