This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
It’s important to understand the differences between a dataengineer and a data scientist. Misunderstanding or not knowing these differences are making teams fail or underperform with big data. I think some of these misconceptions come from the diagrams that are used to describe data scientists and dataengineers.
Dataengineering is one of these new disciplines that has gone from buzzword to mission critical in just a few years. As data has exploded, so has their challenge of doing this key work, which is why a new set of tools has arrived to make dataengineering easier, faster and better than ever.
What is a dataengineer? Dataengineers design, build, and optimize systems for data collection, storage, access, and analytics at scale. They create data pipelines that convert raw data into formats usable by data scientists, data-centric applications, and other data consumers.
Prophecy , a low-code platform for dataengineering, today announced that it has raised a $25 million Series A round led by Insight Partners. “It will read their old data pipelines and automatically write these new data pipelines for the cloud and cloud technologies.
In an effort to be data-driven, many organizations are looking to democratize data. However, they often struggle with increasingly larger data volumes, reverting back to bottlenecking data access to manage large numbers of dataengineering requests and rising data warehousing costs.
What is a dataengineer? Dataengineers design, build, and optimize systems for data collection, storage, access, and analytics at scale. They create data pipelines used by data scientists, data-centric applications, and other data consumers. The dataengineer role.
It shows in his reluctance to run his own servers but it’s perhaps most obvious in his attitude to dataengineering, where he’s nearing the end of a five-year journey to automate or outsource much of the mundane maintenance work and focus internal resources on data analysis. It’s not a good use of our time either.”
As long-term partners, we are excited to double down on their goal to be the premier engineereddata solutions and AI provider for accelerating digital transformation for enterprises across industries,” said Anandamoy Roychowdhary, principal, Sequoia Southeast Asia, in a prepared statement.
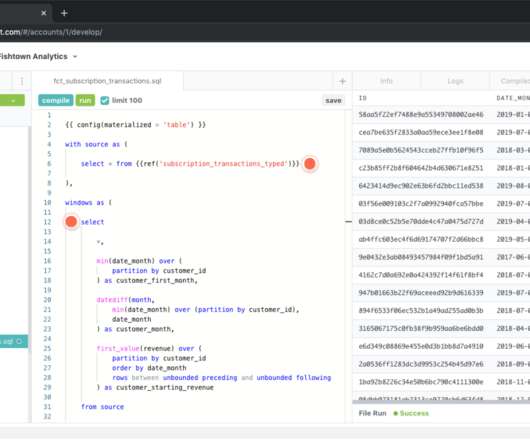
Fishtown Analytics , the Philadelphia-based company behind the dbt open-source dataengineering tool, today announced that it has raised a $29.5 The company is building a platform that allows data analysts to more easily create and disseminate organizational knowledge.
Speaker: Dave Mariani, Co-founder & Chief Technology Officer, AtScale; Bob Kelly, Director of Education and Enablement, AtScale
Workshop video modules include: Breaking down data silos. Integrating data from third-party sources. Developing a data-sharing culture. Combining data integration styles. Translating DevOps principles into your dataengineering process. Using data models to create a single source of truth.
This approach is repeatable, minimizes dependence on manual controls, harnesses technology and AI for data management and integrates seamlessly into the digital product development process. Operational errors because of manual management of data platforms can be extremely costly in the long run.
Dataengine on wheels’. To mine more data out of a dated infrastructure, Fazal first had to modernize NJ Transit’s stack from the ground up to be geared for business benefit. Today, NJ Transit is a “dataengine on wheels,” says the CIDO. “We have shown out value,” Fazal says of the transformation.
I'm an enthusiastic dataengineer who always looks out for various challenging problems and tries to solve them with a simple POC that everyone can relate to. Recently, I have thought about an issue that most dataengineers face daily. I have set alerts on all the batch and streaming data pipelines.
Gen AI-related job listings were particularly common in roles such as data scientists and dataengineers, and in software development. Were building a department of AI engineering, mostly by bringing in people from dataengineering and training them to work with gen AI and AI in general, says Daniel Avancini, Indiciums CDO.
Speaker: Mindy Chen, Director of Decision Science, Hudl
Mindy Chen, Director of Decision Science at Hudl, will take us on a journey through the challenges and opportunities she has seen when building a data team from scratch. Growing from 3 dataengineers to a robust team of 20, Hudl has been on a journey to establish their data capability.
There are three core roles involved in ML modeling, but each one has different motivations and incentives: Dataengineers: Trained engineers excel at gleaning data from multiple sources, cleaning it and storing it in the right formats so that analysis can be performed.
It addresses fundamental challenges in data quality, versioning and integration, facilitating the development and deployment of high-performance GenAI models. data lake for exploration, data warehouse for BI, separate ML platforms).
Dbt is a popular tool for transforming data in a data warehouse or data lake. It enables dataengineers and analysts to write modular SQL transformations, with built-in support for data testing and documentation. This makes dbt a natural choice for the Ducklake setup.
Data science is the sexy thing companies want. The dataengineering and operations teams don't get much love. The organizations don’t realize that data science stands on the shoulders of DataOps and dataengineering giants. Let's call these operational teams that focus on big data: DataOps teams.
In just two weeks since the launch of Business Data Cloud, a pipeline of $650 million has been formed, Klein said. We decided to collaborate after seeing that over 1,000 customers have already contacted us about utilizing the two companies data platforms together. This is an unprecedented level of customer interest.
Much of this work has been in organizing our data and building a secure platform for machine learning and other AI modeling. We also built an organization skilled in the dataengineering and data science required for AI. Well continue to need dataengineering and analytics, data science, and prompt engineering.
While there seems to be a disconnect between business leader expectations and IT practitioner experiences, the hype around generative AI may finally give CIOs and other IT leaders the resources they need to address longstanding data problems, says TerrenPeterson, vice president of dataengineering at Capital One.
The team should be structured similarly to traditional IT or dataengineering teams. This team serves as the primary point of contact when issues arise with models—the go-to experts when something isn’t working.
Big DataEngineer. Another highest-paying job skill in the IT sector is big dataengineering. And as a big dataengineer, you need to work around the big data sets of the applications. Not only this, but you also need to use coding skills, data warehousing, and visualizing skills.
Today, Cloudera DataEngineering, a data service that streamlines and scales data pipeline development, is available with support for AWS Graviton processors. Cloudera DataEngineering is just the start. Give it a try today.
The challenges of integrating data with AI workflows When I speak with our customers, the challenges they talk about involve integrating their data and their enterprise AI workflows. The core of their problem is applying AI technology to the data they already have, whether in the cloud, on their premises, or more likely both.
Dataengineers have a big problem. Almost every team in their business needs access to analytics and other information that can be gleaned from their data warehouses, but only a few have technical backgrounds. The New York-based startup announced today that it has raised $7.6
The first is that it can be difficult to differentiate machine learning roles from more traditional job profiles (such as data analysts, dataengineers and data scientists) because there’s a heavy overlap between descriptions. Recruiting for ML comes with several challenges.
Big data architect: The big data architect designs and implements data architectures supporting the storage, processing, and analysis of large volumes of data. Data architect vs. dataengineer The data architect and dataengineer roles are closely related.
Organizations are finding they have outdated data or incomplete data sets. Companies tend to invest heavily in the data plane where data is stored, organized and managed. Now, they need to invest in dataengineering to prepare data for grounding and fine-tuning their AI models.
A significant share of organizations say to effectively develop and implement AIOps, they need additional skills, including: 45% AI development 44% security management 42% dataengineering 42% AI model training 41% data science AI and data science skills are extremely valuable today.
Data architecture roles Here are some of the most popular job titles related to data architecture, and the average salary for each position, according to data from Indeed : Data architect : $67,000-$173,000 Project manager : $57,000-$142,000 Dataengineer : $83,000-$195,000 Data analyst : $50,000-$128,000 Data scientist : $76,000-$195,000
DataOps (data operations) is an agile, process-oriented methodology for developing and delivering analytics. It brings together DevOps teams with dataengineers and data scientists to provide the tools, processes, and organizational structures to support the data-focused enterprise. What is DataOps?
MLOps, or Machine Learning Operations, is a set of practices that combine machine learning (ML), dataengineering, and DevOps to streamline and automate the end-to-end ML model lifecycle. MLOps is an essential aspect of the current data science workflows.
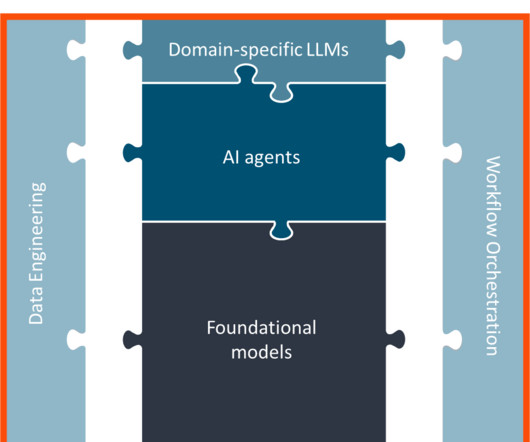
Choreographing data, AI, and enterprise workflows While vertical AI solves for the accuracy, speed, and cost-related challenges associated with large-scale GenAI implementation, it still does not solve for building an end-to-end workflow on its own.
For example, events such as Twitters rebranding to X, and PySparks rise in the dataengineering realm over Spark have all contributed to this decline. The initial excitement that once propelled the language into the limelight during the mid-2010s has diminished over the last 15 years.
It must be a joint effort involving everyone who uses the platform, from dataengineers and scientists to analysts and business stakeholders. Creating Awareness: Foster a culture where all users, from dataengineers to analysts, understand the financial impact of their actions.
The development- and operations world differ in various aspects: Development ML teams are focused on innovation and speed Dev ML teams have roles like Data Scientists, DataEngineers, Business owners. Data Scientists, Machine Learning Engineers, DataEngineers and such need to work together.
It must be a joint effort involving everyone who uses the platform, from dataengineers and scientists to analysts and business stakeholders. Creating Awareness: Foster a culture where all users, from dataengineers to analysts, understand the financial impact of their actions.
But building data pipelines to generate these features is hard, requires significant dataengineering manpower, and can add weeks or months to project delivery times,” Del Balso told TechCrunch in an email interview. Systems use features to make their predictions. “We are still in the early innings of MLOps.
It certainly makes some bold claims, saying, “Quantori’s dataengineering and data science platform for drug discovery and development aims to build a new data integration and high-performance computational environment for global and early-stage biopharma companies.
He built his own SQL-based tool to help understand exactly what resources he was using, based on dataengineering best practices. Pats believes that cloud infrastructure is locked in the past from a data standpoint, and he wanted to push it into the modern age with CloudQuery.
The new team needs dataengineers and scientists, and will look outside the company to hire them. To prepare for the future, Roberge created a new role — vice president of IT innovation and strategy — and very recently promoted somebody to do the job.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content