This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Many organizations have launched dozens of AI proof-of-concept projects only to see a huge percentage fail, in part because CIOs don’t know whether the POCs are meeting key metrics, according to research firm IDC. Many POCs appear to lack clear objections and metrics, he says. The customer really liked the results,” he says.
” Long before the team had working hardware, though, the company focused on building its compiler to ensure that its solution could actually address its customers’ needs. While its competitors often emphasize throughput, the team believes that for edge solutions, latency is the more important metric.
With the paradigm shift from the on-premises datacenter to a decentralized edge infrastructure, companies are on a journey to build more flexible, scalable, distributed IT architectures, and they need experienced technology partners to support the transition.
Edge computing is a combination of networking, storage capabilities, and compute options that take place outside a centralized datacenter. With Edge Computing, IT infrastructures are brought closer to areas where data is created and subsequently used. Use Micro-dataCenters. Determine Your IoT Application Goals.
One of the top problems facing device manufacturers today is overheating hardware. Seshu Madhavapeddy and Surya Ganti hope to present a third option with hardware they’ve developed at their four-year-old startup, Frore Systems. AirJet, which sits above the hardware it’s meant to cool, is 2.8
One of the perennial problems of datacenters is monitoring server utilization to ensure right-sizing of resources. Nlyte's Predict tool can help with capacity planning, using capacity projections to predict future resource needs based on historical data, as well as planned changes to applications and infrastructure.
Net Zero Cloud uses data held within the Salesforce platform to help enterprises report on their carbon footprint and manage other social and governance metrics. Those include using cleaner energy — Salesforce sources 100% clean energy for its global operations, she said — and more efficient hardware in datacenters.
Retrain and fine-tune an existing model Retraining proprietary or open-source models on specific datasets creates smaller, more refined models that can produce accurate results with lower-cost cloud instances or local hardware. Retraining, refining, and optimizing create efficiency so you can run on less expensive hardware.
On their own, IT practitioners can no longer effectively manage ever-increasingly complex IT environments, which can span multiple clouds, locations on the edge, colocation service providers, and enterprise datacenters. The stack has become an intricate web of interdependencies, not all of which are well understood.
And there could be ancillary costs, such as the need for additional server hardware or data storage capacity. Here are some costs that will need to be included in your analysis: Hardware: Do I need to buy new hardware, or do I have capacity to run the software on existing servers and storage?
It feels as if traditional metrics of experience have been upended. This means transitioning to renewable energy sources, responsibly disposing of e-waste, and optimizing hardware to be more energy-efficient.” Hiring in tech has always been a rollercoaster,” Hruby says. “It
MSPs can also bundle in hardware, software, or cloud technology as part of their offerings. As long as the managed service provider meets those metrics, it doesn’t matter whether it uses dedicated staff, automation, or some other system to handle calls for that customer; the MSP decides.
Specifically, partners would be required to commit that their datacenters achieve zero carbon emissions by 2030, an effort that would require the use of 100% renewable energy. They are also becoming more and more aware that their datacenter operations are a very large contributor to their overall carbon footprint.
no hardware to write off). AWS examples include emissions related to datacenter construction, and the manufacture and transportation of IT hardware deployed in datacenters. Metric tons of carbon dioxide equivalents (MTCO2e): The unit of measurement for calculating impact.
Rehosting means you lift and shift your entire IT application landscape from an on-premise datacenter to a datacenter in the cloud. The logs and metrics of all your applications will automatically report to these systems, providing you with a comprehensive view of your applications and infrastructure.
These smaller distilled models can run on off-the-shelf hardware without expensive GPUs. Spending a little money on high-end hardware will bring response times down to the point where building and hosting custom models becomes a realistic option. The same model will run in the cloud at a reasonable cost without specialized servers.
If you have 50,000 Office 365 users, there are no metrics to help you make the calculation at this point.” IT leaders generally need to get numbers from suppliers in four different categories: hardware vendors, software vendors, professional service providers, and cloud providers.
Optimize internal technology Today, CIOs can influence everything from hardware procurement and the way developers write code for their company, to how IT gathers, processes, distributes and stores data—all of which impact a company’s carbon footprint.
Standout features: Track loads on machines to ensure rightsized instance allocation Build reports summarizing consumption to help developers rightsize hardware Flexera One The Flexera One cloud management suite tackles many cloud management tasks, such as tracking assets or organizing governance to orchestrate control.
One purpose of monitoring is to gain high availability by reducing the number of critical time-based metrics –. Development teams receive comprehensive diagnostic data about the problems through automatic monitoring when performance or further difficulties occur. That calls for detecting (TTD). Prometheus.
Progress in research has been made possible by the steady improvement in: (1) data sets, (2) hardware and software tools, and (3) a culture of sharing and openness through conferences and websites like arXiv. We see a lot of new companies working on specialized hardware. Today, the community is much larger.
As leaders in the HPC industry, we are worried about how to cool these datacenters. Many are looking at innovative datacenter designs including modular centers and colocation. Deployed successfully around the globe, liquid cooling is becoming essential to future proofing datacenters.
The number of servers that Amazon.com had to buy and rack in their data-centers in order to have enough capacity to serve the peak demand +15% spare buffer. And one of the results was this document explaining how to reduce the fine-grained coupling between applications and hardware. Typical Weekly Traffic to Amazon.com?—?
Resource utilization is the percentage of time occupied by the hardware components as compared to the total time that the component is available for use. Once the mobile app is installed, it is judged for various metrics like the speed, responsiveness, and stability which define the user experience and overall satisfaction.
Announcing the ISA-6000 Hardware Appliance. The ISA-6000 hardware appliance features massive performance improvements across the board, with throughput speeds for SSL and ESP traffic showing a 3X to 4X improvement in lab testing. (SSL Performance metrics are measured in a lab environment using industry-standard performance tools.
There’s also exciting news on the hardware front. Last year we began tracking startups building specialized hardware for deep learning and AI for training and inference as well as for use in edge devices and in datacenters. Thus, both RL users and RL researchers are already benefiting from using RLlib.
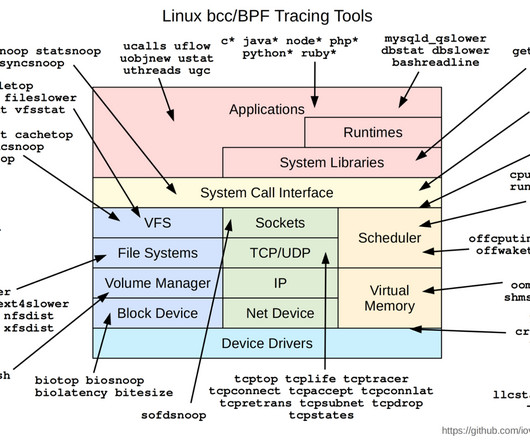
Since the kernel is basically the software layer between the applications you’re running and the underlying hardware, eBPF operates just about as close as you can get to the line-rate activity of a host. Using a synthetic test, we can capture the metrics for each component of that interaction from layer 3 to the application layer itself.
Only after these actions can you analyze data with dedicated software (a so-called online analytical processing or OLAP system). But how do you move data? You need to have infrastructure, hardware and/or software, that will allow you to do that. You need an efficient data pipeline. What is a data pipeline?
There is a lot of confusion regarding the two primary data sets in network management: SNMP and flow. SNMP is used to collect metadata and metrics about a network device. Aside from general metadata, you can also collect numerical data. This post will help define both and provide more context on where and why to use each.
There is a lot of confusion regarding the two primary data sets in network management: SNMP and flow. SNMP is used to collect metadata and metrics about a network device. Aside from general metadata, you can also collect numerical data. This post will help define both and provide more context on where and why to use each.
Avoiding expensive investments in hardware. They know the best methodologies to study the Source On-prem Datacenter either by installing the tools like TSO Logic or by analyzing the past metrics of each individual servers. Study your on-premises datacenter before you select a cloud strategy. Migrating virtual machines.
For lack of similar capabilities, some of our competitors began implying that we would no longer be focused on the innovative data infrastructure, storage and compute solutions that were the hallmark of Hitachi Data Systems. A REST API is built directly into our VSP storage controllers. 2019 will provide even more proof points.
When considering which FEC to choose for a new specification, you need to consider some key metrics, including the following: Coding overhead rate— The ratio of the number of redundant bits to information bits. Other considerations include hardware complexity, latency, and power consumption.
Security teams can access vital information, such as metrics and response times, from one location and reduce manual data sorting for security analysts. Our next generation cybersecurity platforms provide end-to-end security from the datacenter, to the cloud, to your SOC. cybersecurity tools on average.
Green Software Foundation defines “green software” as a new field that combines climate science, hardware, software, electricity markets, and datacenter design to create carbon-efficient software that emits the least amount of carbon possible.
Going from petabytes (PB) to exabytes (EB) of data is no small feat, requiring significant investments in hardware, software, and human resources. Before you can even think about analyzing exabytes worth of data, ensure you have the infrastructure to store more than 1000 petabytes! Much larger.
For example, Microsoft is planning to become carbon negative by 2030, and 70% of its massive datacenters will run on renewable energy by 2023. These are levied on internal business units for the carbon emissions associated with the company’s global operations for datacenters, offices, labs, manufacturing, and business air travel.
When evaluating solutions, whether to internal problems or those of our customers, I like to keep the core metrics fairly simple: will this reduce costs, increase performance, or improve the network’s reliability? No matter how you slice it, additional instances, hardware, etc., Costs Redundancy isn’t cheap.
Aside from using this traffic data, Kentik also collects information from the network devices using SNMP. This data is used to profile the devices and determine the configuration of the hardware and software. We also collect interface details and metrics using SNMP. This keeps employees safe at home.
With the massive amount of data being generated every minute, it gets tough to maintain the databases and costs associated with it. Costs can include licensing, hardware, storage, and personnel headcount (DBAs)—these costs are necessary to ensure databases are running optimally for higher productivity.
One axes represents the architectural layers of modern systems and applications from the underlying hardware all the way through to the end-user experience. The other axis represents data generated all the way through data consumption. This is common in traditional datacenters as well as in private clouds.
This series of guest posts has concentrated on the numerous challenges facing enterprise IT managers as businesses embrace digital transformation and migrate IT applications from private datacenters into the cloud. In this post, I would like to finally expand on this theme.
This requires robust infrastructure—including a massive storage and networking capacity hosted in on-premise datacenters or cloud computing resources—and the ability to handle unexpected situations through incident responses. Service Intelligence helps resolvers gain insights into the root cause of incidents and incident metrics.
This requires robust infrastructure—including a massive storage and networking capacity hosted in on-premise datacenters or cloud computing resources—and the ability to handle unexpected situations through incident responses. Service Intelligence helps resolvers gain insights into the root cause of incidents and incident metrics.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content