This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
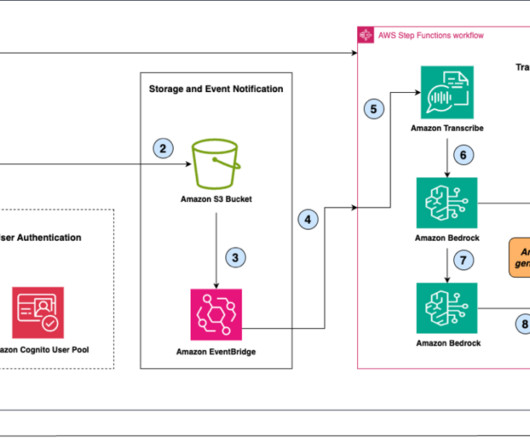
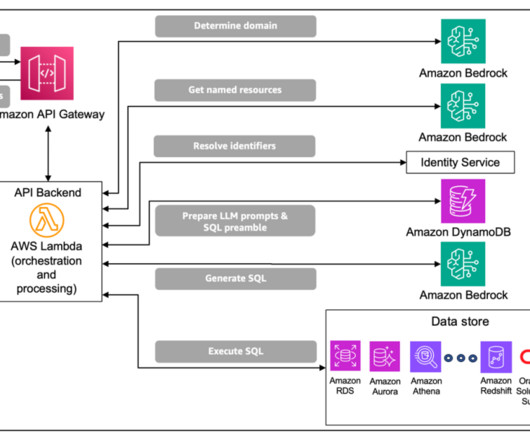
The solution presented in this post takes approximately 15–30 minutes to deploy and consists of the following key components: Amazon OpenSearch Service Serverless maintains three indexes : the inventory index, the compatible parts index, and the owner manuals index. The following diagram illustrates how it works.
Performance optimization The serverless architecture used in this post provides a scalable solution out of the box. AWS Lambda costs are based on the number of requests and compute time, and Amazon DynamoDB charges depend on read/write capacity units and storage used. For more details about pricing, refer to Amazon Bedrock pricing.
In the following sections, we walk you through constructing a scalable, serverless, end-to-end Public Speaking Mentor AI Assistant with Amazon Bedrock, Amazon Transcribe , and AWS Step Functions using provided sample code. Uploading audio files alone can optimize storage costs.
Get a basic understanding of serverless, then go deeper with recommended resources. Serverless is a trend in computing that decouples the execution of code, such as in web applications, from the need to maintain servers to run that code. Serverless also offers an innovative billing model and easier scalability.
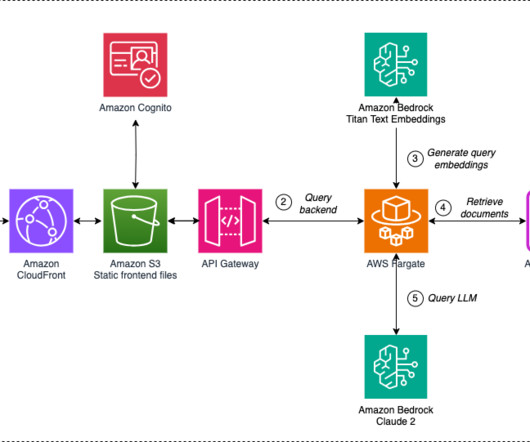
Solution overview The policy documents reside in Amazon Simple Storage Service (Amazon S3) storage. During the solution design process, Verisk also considered using Amazon Bedrock Knowledge Bases because its purpose built for creating and storing embeddings within Amazon OpenSearch Serverless.
From simple mechanisms for holding data like punch cards and paper tapes to real-time data processing systems like Hadoop, data storage systems have come a long way to become what they are now. Being relatively new, cloud warehouses more commonly consist of three layers such as compute, storage, and client (service). Is it still so?
eSentire has over 2 TB of signal data stored in their Amazon Simple Storage Service (Amazon S3) data lake. When a SageMaker endpoint is constructed, an S3 URI to the bucket containing the model artifact and Docker image is shared using Amazon ECR.
So we constructed a survey and ran it earlier this year: from January 9th through January 31st, 2020. Interestingly, multi-cloud, or the use of multiple cloud computing and storage services in a single homogeneous network architecture, had the fewest users (24% of the respondents). Serverless Stagnant.
If an image is uploaded, it is stored in Amazon Simple Storage Service (Amazon S3) , and a custom AWS Lambda function will use a machine learning model deployed on Amazon SageMaker to analyze the image to extract a list of place names and the similarity score of each place name. _validate_tools(tools) _output_parser = output_parser or cls._get_default_output_parser()
Additional Isolation Options – Supplementary isolation approaches focused on compute and data Storage considerations. Isolation vs. Authentication & Authorization Isolation is a fundamental choice in a SaaS architecture because security and reliability are not a single construct. Let’s take a closer look.
When thinking about billing events, the challenge is to construct a set of value events that provides your customers a choice of price points. Not all SaaS platforms have the freedom to start fresh with cloud-native constructs like containers, serverless, and microservices.
Client profiles – We have three business clients in the construction, manufacturing, and mining industries, which are mid-to-enterprise companies. Pre-Construction Services - Feasibility Studies - Site Selection and Evaluation. Pre-Construction Services - Feasibility Studies - Site Selection and Evaluation.
It can automatically connect to over 40 different data sources, including Amazon Simple Storage Service (Amazon S3), Microsoft SharePoint, Salesforce, Atlassian Confluence, Slack, and Jira Cloud. OpenSearch Serverless is a fully managed option that allows you to run petabyte-scale workloads without managing clusters.
We partnered with Keepler , a cloud-centered data services consulting company specialized in the design, construction, deployment, and operation of advanced public cloud analytics custom-made solutions for large organizations, in the creation of the first generative AI solution for one of our corporate teams.
The workflow consists of the following steps: A user uploads multiple images into an Amazon Simple Storage Service (Amazon S3) bucket via a Streamlit web application. Constructs a request payload for the Amazon Bedrock InvokeModel API. Upon submission, the Streamlit web application updates an Amazon DynamoDB table with image details.
In this post, we walk you through a step-by-step process to create a social media content generator app using vision, language, and embedding models (Anthropic’s Claude 3, Amazon Titan Image Generator, and Amazon Titan Multimodal Embeddings) through Amazon Bedrock API and Amazon OpenSearch Serverless. Go to SageMaker Studio.
Solution overview In this post, we demonstrate the use of Mixtral-8x7B Instruct text generation combined with the BGE Large En embedding model to efficiently construct a RAG QnA system on an Amazon SageMaker notebook using the parent document retriever tool and contextual compression technique.
Knowledge Bases for Amazon Bedrock currently supports four vector stores: Amazon OpenSearch Serverless , Amazon Aurora PostgreSQL-Compatible Edition , Pinecone , and Redis Enterprise Cloud. As of this writing, the hybrid search feature is available for OpenSearch Serverless, with support for other vector stores coming soon.
In the third step, you can use extracted text and data to construct meaningful enhancements for these documents. Raghavarao Sodabathina is a Principal Solutions Architect at AWS, focusing on Data Analytics, AI/ML, and Serverless Platform. In the second step, you extract information accurately from your documents.
If the Northwind DB Knowledge Base search function result did not contain enough information to construct a full query try to construct a query to the best of your ability based on the Northwind database schema.
Understanding the intrinsic value of data network effects, Vidmob constructed a product and operational system architecture designed to be the industry’s most comprehensive RLHF solution for marketing creatives. Solution overview The AWS team worked with Vidmob to build a serverless architecture for handling incoming questions from customers.
Another example is accidentally provisioning premium instances or storage options that arent needed for your workload. Retailers, for example, often see higher traffic and thus compute and storage costs during holidays. Regular configuration reviews and automated checks can help detect and resolve these issues.
Oracle Cloud Infrastructure Data Integration is a next generation, fully managed, multi-tenant, serverless, native cloud ETL service. Serverless execution, pay-as you go pricing model . Load the data into object storage and create high-quality models more quickly using OCI data science. Oracle Managed. License needed.
SageMaker Pipelines is a serverless workflow orchestration service purpose-built for foundation model operations (FMOps). The Model (output) section automatically populates the default Amazon Simple Storage Service (Amazon S3) You can update the S3 URI to change the location where the model artifacts will be stored. Failed to register.
load_data() Build the index: The key feature of LlamaIndex is its ability to construct organized indexes over data, which is represented as documents or nodes. For more details, refer to Vector Engine for Amazon OpenSearch Serverless. The indexing facilitates efficient querying over the data.
However one of the joys of Lambda, and Serverless in general, is the automatic and vast scaling capabilities it gives us. Lambda’s scaling model has a large impact on how we consider state, so I also talk about Lambda’s instantiation and threading model, followed by a discussion on Application State & Data Storage, and Caching.
The cloud is made of servers, software and data storage centers that are accessed over the Internet, providing many benefits that include cost reduction, scalability, data security, work force and data mobility. After all, how could a business possibly run smoothly without traditional hardware or an onsite server? About The Company.
So this remedy is also wrong: Rather than trying to construct rules that kept the referee honest even when they played on one of the teams, they ordered the companies to choose one role – either you were the ref, or you were a player, but you couldn't referee a match where you were also in the competition.
However one of the joys of Lambda, and Serverless in general, is the automatic and vast scaling capabilities it gives us. Lambda’s scaling model has a large impact on how we consider state, so I also talk about Lambda’s instantiation and threading model, followed by a discussion on Application State & Data Storage, and Caching.
These services may include disaster recovery, the Internet of Things, serverless computing, and so on so forth. Active Directory was incorporated into the Microsoft Server product line later, enhancing Microsoft Server storage capabilities. In the case of the previous example, they’d receive incoming requests to process them.
Stream processors are used for constructing the flow from other streams in various patterns, either executing and reacting to logic or splitting, merging and maintaining materialized views, such that when they are all combined (fan in), they represent a domain model in the form of a digital nervous system. Interested in more?
In addition to flexible and quickly available computing and storage infrastructure, the cloud promises a wide range of services that make it easy to set up and operate digital business processes. However, to accommodate the ever-increasing amounts of data, the project team is integrating AWS S3 and Azure Blob Storage.
The workflow to populate the knowledge base consists of the following steps, as noted in the architecture diagram: The user uploads company- and domain-specific information, like policy manuals, to an Amazon Simple Storage (Amazon S3) bucket. This bucket is designated as the knowledge base data source. Anthropic’s Claude Sonnet 3.5
Enterprise-scale data presents specific challenges for NL2SQL, including the following: Complex schemas optimized for storage (and not retrieval) Enterprise databases are often distributed in nature and optimized for storage and not for retrieval. The solution uses the data domain to construct prompt inputs for the generative LLM.
The architecture is centered around a native AWS serverless backend, which ensures minimal maintenance and high availability together with fast development. Core components of the RAG system Amazon Simple Storage Service (Amazon S3): Amazon S3 serves as the primary storage for source data.
With the Custom Model Import feature, you can now seamlessly deploy your customized chess models fine-tuned on specific gameplay styles or historical matches, eliminating the need to manage infrastructure while enabling serverless, on-demand inference. model_id – This is the SageMaker JumpStart model ID for the LLM that you need to fine-tune.
The picture taken by the user is stored in an Amazon Simple Storage Service (Amazon S3) This S3 bucket should be configured with a lifecycle policy that deletes the image after use. To learn more about S3 lifecycle policies, see Managing your storage lifecycle. client('s3') dynamodb = boto3.resource('dynamodb')
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









































Let's personalize your content