This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The workflow includes the following steps: Documents (owner manuals) are uploaded to an Amazon Simple Storage Service (Amazon S3) bucket. The Lambda function runs the database query against the appropriate OpenSearch Service indexes, searching for exact matches or using fuzzy matching for partial information.
Before processing the request, a Lambda authorizer function associated with the API Gateway authenticates the incoming message. After it’s authenticated, the request is forwarded to another Lambda function that contains our core application logic. The code runs in a Lambda function. Implement your business logic in this file.
The solution consists of the following steps: Relevant documents are uploaded and stored in an Amazon Simple Storage Service (Amazon S3) bucket. The text extraction AWS Lambda function is invoked by the SQS queue, processing each queued file and using Amazon Textract to extract text from the documents.
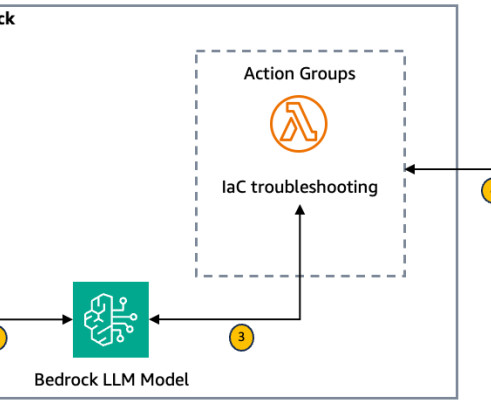
Error retrieval and context gathering The Amazon Bedrock agent forwards these details to an action group that invokes the first AWS Lambda function (see the following Lambda function code ). This contextual information is then sent back to the first Lambda function. Provide the troubleshooting steps to the user.
Because of this flexible, composable pattern, customers can construct efficient networks of interconnected agents that work seamlessly together. In the following sections, we demonstrate the step-by-step process of constructing this multi-agent system. import json import boto3 client = boto3.client('ses')
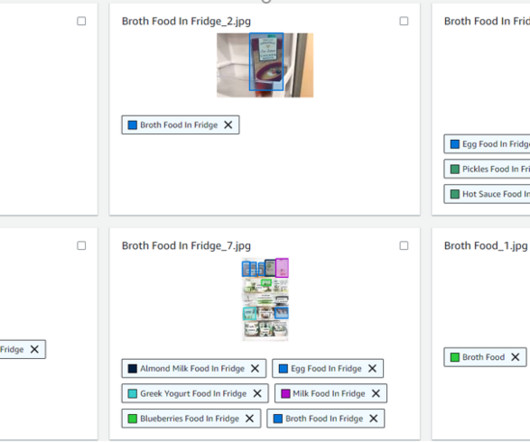
If an image is uploaded, it is stored in Amazon Simple Storage Service (Amazon S3) , and a custom AWS Lambda function will use a machine learning model deployed on Amazon SageMaker to analyze the image to extract a list of place names and the similarity score of each place name.
The workflow consists of the following steps: A user uploads multiple images into an Amazon Simple Storage Service (Amazon S3) bucket via a Streamlit web application. The DynamoDB update triggers an AWS Lambda function, which starts a Step Functions workflow. Constructs a request payload for the Amazon Bedrock InvokeModel API.
Scaling and State This is Part 9 of Learning Lambda, a tutorial series about engineering using AWS Lambda. So far in this series we’ve only been talking about processing a small number of events with Lambda, one after the other. Lambda will horizontally scale precisely when we need it to a massive extent.
Generative AI CDK Constructs , an open-source extension of AWS CDK, provides well-architected multi-service patterns to quickly and efficiently create repeatable infrastructure required for generative AI projects on AWS. Transcripts are then stored in the project’s S3 bucket under /transcriptions/TranscribeOutput/.
Solution overview The policy documents reside in Amazon Simple Storage Service (Amazon S3) storage. This action invokes an AWS Lambda function to retrieve the document embeddings from the OpenSearch Service database and present them to Anthropics Claude 3 Sonnet FM, which is accessed through Amazon Bedrock.
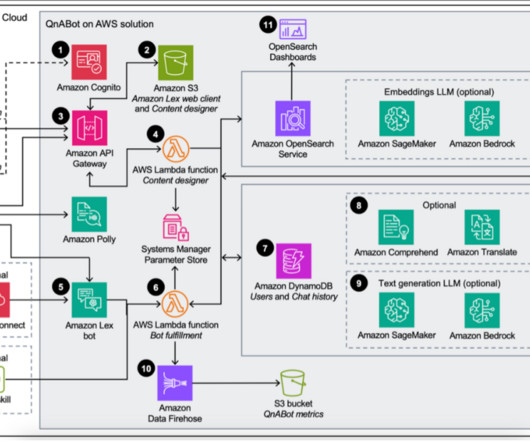
The Content Designer AWS Lambda function saves the input in Amazon OpenSearch Service in a questions bank index. Amazon Lex forwards requests to the Bot Fulfillment Lambda function. Users can also send requests to this Lambda function through Amazon Alexa devices.
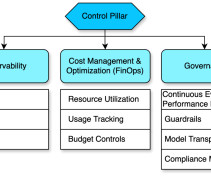
Additional Isolation Options – Supplementary isolation approaches focused on compute and data Storage considerations. Isolation vs. Authentication & Authorization Isolation is a fundamental choice in a SaaS architecture because security and reliability are not a single construct. Let’s take a closer look.
Scaling and State This is Part 9 of Learning Lambda, a tutorial series about engineering using AWS Lambda. So far in this series we’ve only been talking about processing a small number of events with Lambda, one after the other. Lambda will horizontally scale precisely when we need it to a massive extent.
Understanding the intrinsic value of data network effects, Vidmob constructed a product and operational system architecture designed to be the industry’s most comprehensive RLHF solution for marketing creatives. Dynamo DB stores the query and the session ID, which is then passed to a Lambda function as a DynamoDB event notification.
The CloudFormation template also provides the required AWS Identity and Access Management (IAM) access to set up the vector database, SageMaker resources, and AWS Lambda Acquire access to models hosted on Amazon Bedrock. Create and associate an action group with an API schema and a Lambda function. Delete the Lambda function.
eSentire has over 2 TB of signal data stored in their Amazon Simple Storage Service (Amazon S3) data lake. This system uses AWS Lambda and Amazon DynamoDB to orchestrate a series of LLM invocations. A foundation model (FM) is an LLM that has undergone unsupervised pre-training on a corpus of text.
For storage-intensive workloads, AWS Customers will have an opportunity to use smaller instance sizes and still meet EBS-optimized instance performance requirements, thereby saving costs. Analysts can use familiar SQL constructs to JOIN data across multiple data sources.
This data can come from multiple sources and doesn’t require any processing or transformation before storage. Next, the data is loaded, as-is, into the data lake or storage resource. You can also choose to construct a data lake that is customized to your needs by selecting and integrating services although this requires more expertise.
You can securely integrate and deploy generative AI capabilities into your applications using services such as AWS Lambda , enabling seamless data management, monitoring, and compliance (for more details, see Monitoring and observability ). You can enable invocation logging through either the AWS Management Console or the API.
Another example is accidentally provisioning premium instances or storage options that arent needed for your workload. Retailers, for example, often see higher traffic and thus compute and storage costs during holidays. EC2, S3, Lambda) that adapt to weekly and monthly patterns to minimize false positives.
While AWS Lambda is viewed as the specific technology that kicked off the movement, other vendors offer platforms for reducing operational overhead. Serverless offerings tend to fall into two types: Backends as a Service (BaaS) - BaaS provides serverless approaches to handle things like storage, authentication, and user management.
Solution overview You will construct a RAG QnA system on a SageMaker notebook using the Llama3-8B model and BGE Large embedding model. The following diagram illustrates the step-by-step architecture of this solution, which is described in the following sections.
load_data() Build the index: The key feature of LlamaIndex is its ability to construct organized indexes over data, which is represented as documents or nodes. tools = [ Tool( name="Pressrelease", func=lambda q: str(index.as_query_engine().query(q)), The indexing facilitates efficient querying over the data.
Even a span event may make too much noise and cost too much in storage! These often come from the settings of your service, or perhaps the event to your Lambda function. If you’ve written code to construct the attribute name, you’ve probably done the wrong thing. cloud.region , tenant.id , user.id ). i-00feb7d6aa65a8706.instance.name
So we constructed a survey and ran it earlier this year: from January 9th through January 31st, 2020. Interestingly, multi-cloud, or the use of multiple cloud computing and storage services in a single homogeneous network architecture, had the fewest users (24% of the respondents). All told, we received 1,283 responses.
For example, a data science OU could be limited to read-only access to Athena and specific S3 buckets. { "Effect": "Allow", "Action": [ "athena:GetQueryResults", "athena:StartQueryExecution", "s3:GetObject" ], "Resource": "*" } This keeps experimentation isolated to analytics tools without opening write access to infrastructure or storage.
In addition to flexible and quickly available computing and storage infrastructure, the cloud promises a wide range of services that make it easy to set up and operate digital business processes. However, to accommodate the ever-increasing amounts of data, the project team is integrating AWS S3 and Azure Blob Storage.
The picture taken by the user is stored in an Amazon Simple Storage Service (Amazon S3) This S3 bucket should be configured with a lifecycle policy that deletes the image after use. To learn more about S3 lifecycle policies, see Managing your storage lifecycle.
The workflow to populate the knowledge base consists of the following steps, as noted in the architecture diagram: The user uploads company- and domain-specific information, like policy manuals, to an Amazon Simple Storage (Amazon S3) bucket. Amazon S3 invokes an AWS Lambda function to synchronize the data source with the knowledge base.
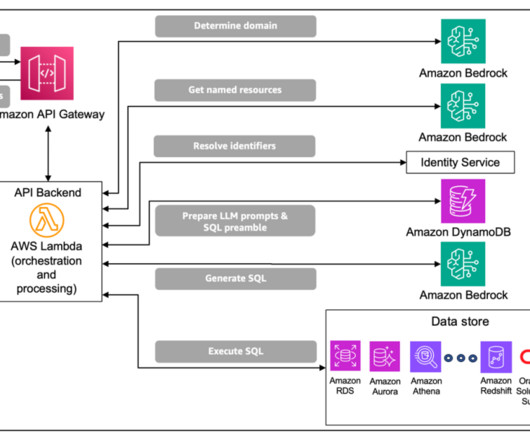
Enterprise-scale data presents specific challenges for NL2SQL, including the following: Complex schemas optimized for storage (and not retrieval) Enterprise databases are often distributed in nature and optimized for storage and not for retrieval. The solution uses the data domain to construct prompt inputs for the generative LLM.
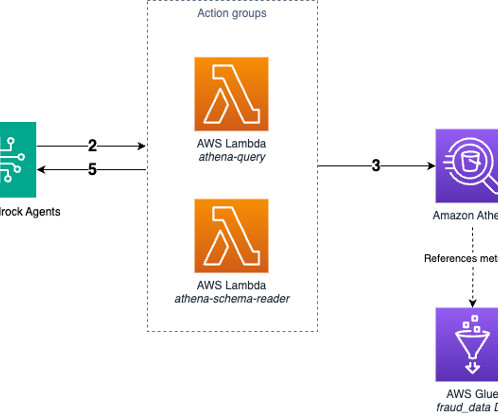
If a query execution fails, the agent can analyze the error messages returned by AWS Lambda and automatically retries the modified query when appropriate. The Lambda function sends the query to Athena to execute. The Lambda function retrieves and processes the results.
Core components of the RAG system Amazon Simple Storage Service (Amazon S3): Amazon S3 serves as the primary storage for source data. AWS Lambda : Provides the serverless compute environment for running backend operations without provisioning or managing servers, which scales automatically with the application’s demands.
Players can choose from the following list of opponents: Generative AI models available on Amazon Bedrock Custom fine-tuned models deployed to Amazon Bedrock Chess engines Human opponents Random moves An infrastructure as code (IaC) approach was taken when constructing this project.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





































Let's personalize your content