This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
What is a dataengineer? Dataengineers design, build, and optimize systems for data collection, storage, access, and analytics at scale. They create data pipelines that convert raw data into formats usable by data scientists, data-centric applications, and other data consumers.
What is a dataengineer? Dataengineers design, build, and optimize systems for data collection, storage, access, and analytics at scale. They create data pipelines used by data scientists, data-centric applications, and other data consumers. The dataengineer role.
But for engineering and team leaders without an ML background, this can also feel overwhelming and intimidating. I regularly meet smart, successful, highly competent and normally very confident leaders who struggle to navigate a constructive or effective conversation on ML — even though some of them lead teams that engineer it.
If we look at the hierarchy of needs in data science implementations, we’ll see that the next step after gathering your data for analysis is dataengineering. This discipline is not to be underestimated, as it enables effective data storing and reliable data flow while taking charge of the infrastructure.
Engineers are not only the ones bearing helmets and operating on construction sites. Explaining the difference, especially when they both work with something intangible such as data , is difficult. We will try to answer your questions and explain how two critical data jobs are different and where they overlap.
Upon entering the world of advanced software engineering , you have several career paths to choose from, the most popular of which are: Blockchain Engineer Security Engineer Embedded Systems EngineerDataEngineer Backend Engineer. What is Computer Science?
So, along with data scientists who create algorithms, there are dataengineers, the architects of data platforms. In this article we’ll explain what a dataengineer is, the field of their responsibilities, skill sets, and general role description. What is a dataengineer?
Digital technology, he explained, would remain a central focus of the construction-aggregates industry and would underpin customer-grade experiences increasingly expected from industry leaders. Vulcan, based in Birmingham, Ala., The success of the Vulcan Way of Selling brought the company to an inflection point.
“As organizations look for ways to harness data to make better business decisions, the market for cloud data integration and transformation is expanding,” said Chris Caulkin, managing director and head of Technology for EMEA at General Atlantic. “We
Not only should the data strategy be cognizant of what’s in the IT and business strategies, it should also be embedded within those strategies as well, helping them unlock even more business value for the organization.
Organizations need data scientists and analysts with expertise in techniques for analyzing data. Data scientists are the core of most data science teams, but moving from data to analysis to production value requires a range of skills and roles. Data science goals and deliverables.
In this detailed and personal account, the author shared his journey of building and evolving data pipelines in the rapidly transforming streaming media industry. In the last two decades, dataengineering has dramatically transformed industries.
The cloud offers excellent scalability, while graph databases offer the ability to display incredible amounts of data in a way that makes analytics efficient and effective. Who is Big DataEngineer? Big Data requires a unique engineering approach. Big DataEngineer vs Data Scientist.
When it comes to financial technology, dataengineers are the most important architects. As fintech continues to change the way standard financial services are done, the dataengineer’s job becomes more and more important in shaping the future of the industry.
Still, it’s possible to do it yourself, says Senthil Kumar, CTO and head of AI at Slate Technologies, a data analytics provider for construction and related industries. This would require organizations to have specialized expertise in machine learning, natural language processing, and dataengineering. “By
What Is AWS Redshift Data Sharing? As a dataengineer, most of my time will be spent constructingdata pipelines from source systems to data lakes , databases , and warehouses. One of the pain points is to have this data distributed to several teams in the organization.
Constructing SQL queries from natural language isn’t a simple task. Figure 2: High level database access using an LLM flow The challenge An LLM can construct SQL queries based on natural language. Figure 2: High level database access using an LLM flow The challenge An LLM can construct SQL queries based on natural language.
This creates a clean separation between upstream systems and consumers in Ads Engineering. This system was constructed using ad playback telemetry, which allowed us to gather essential metrics from these ad sessions. A significant decision in this plan was to position the ad sessionization process downstream of the raw adevents.
His role now encompasses responsibility for dataengineering, analytics development, and the vehicle inventory and statistics & pricing teams. The company was born as a series of print buying guides in 1966 and began making its data available via CD-ROM in the 1990s. We believe the same thing is happening right now with AI.
When we announced the GA of Cloudera DataEngineering back in September of last year, a key vision we had was to simplify the automation of data transformation pipelines at scale. The post Automating Data Pipelines in CDP with CDE Managed Airflow Service appeared first on Cloudera Blog.
Before we can understand how model lineage is managed and subsequently audited, we first need to understand some high-level constructs within CML. The highest level construct in CML is a workspace. We can think of model lineage as the specific combination of data and transformations on that data that create a model.
Of the organizations surveyed, 52 percent were seeking machine learning modelers and data scientists, 49 percent needed employees with a better understanding of business use cases, and 42 percent lacked people with dataengineering skills. Process Deficiencies. “AI Policy Faults.
Data obsession is all the rage today, as all businesses struggle to get data. But, unlike oil, data itself costs nothing, unless you can make sense of it. Dedicated fields of knowledge like dataengineering and data science became the gold miners bringing new methods to collect, process, and store data.
You can see that these distribution sort of center around , , and which is how we constructed them in the first place. I’m looking for dataengineers to join my team at Better ! distplot ( k_samples , label = 'k' ). distplot ( m_samples , label = 'm' ). distplot ( numpy. exp ( log_sigma_samples ), label = 'sigma' ). curves = [].
This intricate setup makes sure that the application’s backend data sources are seamlessly integrated, thereby providing tailored responses to customer inquiries. When a SageMaker endpoint is constructed, an S3 URI to the bucket containing the model artifact and Docker image is shared using Amazon ECR.
This limited usage of Spark at security-conscious customers, as they were unable to leverage its rich APIs such as SparkSQL and Dataframe constructs to build complex and scalable pipelines. . Fine grained access control (FGAC) with Spark. Introducing Spark Secure Access Mode. Starting with CDP 7.1.7 For those eager to get started, CDP 7.1.7
Conclusion In this post, we illustrated how to use generative AI to significantly enhance the efficiency of data analysts. By using LookML as metadata for our data lake, we constructed vector stores for views (tables) and models (relationships). She enjoys to travel and explore new places, foods, and culture.
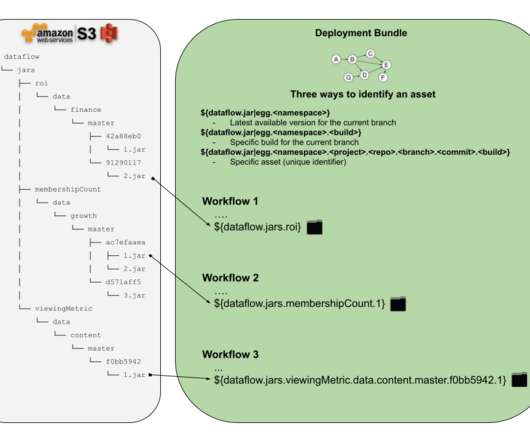
Let’s define some requirements that we are interested in delivering to the Netflix dataengineers or anyone who would like to schedule a workflow with some external assets in it. Manually constructed continuous delivery system. In Figure 2, we show a variation of the typical manually constructed deployment pipeline.
In addition, data pipelines include more and more stages, thus making it difficult for dataengineers to compile, manage, and troubleshoot those analytical workloads. different analytical frameworks) for complex use cases that span different stages across the data lifecycle? CRM platforms).
Traditional data warehouse architecture. Traditional or on-premise data warehouses have three standard approaches to constructing their architecture layers: single-tier, two-tier, and three-tier architectures. In the storage layers, data is organized in partitions to be further optimized and compressed.
Pentaho unlocked mapR to enable data science and enabled business users to operationalize data through self-service. This also enabled the data science team, which included IT, dataengineers and business analysts with the tools for data preparation and operationalize algorithms.
Whether you’re fetching data, updating records, or performing complex queries, efficient database operations are crucial for application performance. One powerful tool at your disposal for constructing dynamic queries is the Criteria API, which allows you to build queries programmatically and dynamically based on various criteria.
In our healthcare example, a multidisciplinary team might be necessary, encompassing data scientists and medical professionals for domain expertise and bioinformaticians for dataengineering. Adaptability is vital, so prepare to refine your approach based on fresh insights and constructive feedback as your project evolves.
At Netflix, our data scientists span many areas of technical specialization, including experimentation, causal inference, machine learning, NLP, modeling, and optimization. Together with data analytics and dataengineering, we comprise the larger, centralized Data Science and Engineering group.
There are shadow IT teams of developers or dataengineers that spring up in areas like operations or marketing because the captive IT function is slow, if not outright incapable, of responding to internal customer demand. IT shadows appear in a lot of different forms.
Introduction As someone who has hands-on experience in constructing and leveraging data lakes, I can attest to the transformative power these repositories hold for organizations grappling with vast amounts of data. These systems ensure high availability and facilitate the storage of massive data volumes.
For example, a company has a data mart containing all the financial data. The company may wish to model an OLAP cube to summarize this data by different dimensions: by time, by product, or by city, to name a few. Watch our video about dataengineering to learn more about how data gets from sources to BI tools.
Infrastructure Environment: The infrastructure (including private cloud, public cloud or a combination of both) that hosts application logic and data. Data Auditing: In addition to data lineage, Data Stewards and Information Security analysts should be able to track all interactions of Data Consumers with data assets / data products.
In order to scale responsible AI, organizations should implement these fundamental building blocks of data literacy: The data science and machine learning workflow: Learning about the steps required to create predictions from raw data helps stakeholders develop an understanding of AI project implementation.
The Data Innovation Summit 2022 is constructed so it equally addresses all the elements of data-driven and AI-ready business: data, people, processes and technology. Presentations by some of the leading experts, researchers and practitioners in the area.
This leads to a great environment where I am constantly challenged, learning, and receiving constructive feedback on how I can do better! Chris] I think a big part of our jobs is continuously thinking about how data can benefit our stakeholders.
Kubernetes has emerged as go to container orchestration platform for dataengineering teams. In 2018, a widespread adaptation of Kubernetes for big data processing is anitcipated. Organisations are already using Kubernetes for a variety of workloads [1] [2] and data workloads are up next.
The following sections will walk you through the steps to get data indexed using the Crunch Indexer Tool that comes out of the box with DDE. In HUE there is an index designer; however, as long as DDE is in Tech Preview it will be somewhat under re-construction and is not recommended at this point.
Generative artificial intelligence (AI) provides the ability to take relevant information from a data source such as ServiceNow and provide well-constructed answers back to the user. With over 20 years of professional experience, Prabhakar was a dataengineer and a program leader in the financial services space prior to joining AWS.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















































Let's personalize your content