This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Data architecture definition Data architecture describes the structure of an organizations logical and physical data assets, and data management resources, according to The Open Group Architecture Framework (TOGAF). An organizations data architecture is the purview of data architects. Cloud storage.
Our Databricks Practice holds FinOps as a core architectural tenet, but sometimes compliance overrules cost savings. Deletion vectors are a storage optimization feature that replaces physical deletion with soft deletion. There is a catch once we consider data deletion within the context of regulatory compliance.
The following is a review of the book Fundamentals of DataEngineering by Joe Reis and Matt Housley, published by O’Reilly in June of 2022, and some takeaway lessons. This book is as good for a project manager or any other non-technical role as it is for a computer science student or a dataengineer.
Unity Catalog gives you centralized governance, meaning you get great features like access controls and data lineage to keep your tables secure, findable and traceable. Unity Catalog can thus bridge the gap in DuckDB setups, where governance and security are more limited, by adding a robust layer of management and compliance.
Azure Key Vault Secrets offers a centralized and secure storage alternative for API keys, passwords, certificates, and other sensitive statistics. Azure Key Vault is a cloud service that provides secure storage and access to confidential information such as passwords, API keys, and connection strings. What is Azure Key Vault Secret?
Since the release of Cloudera DataEngineering (CDE) more than a year ago , our number one goal was operationalizing Spark pipelines at scale with first class tooling designed to streamline automation and observability. Securing and scaling storage. Tooling.
How will organizations wield AI to seize greater opportunities, engage employees, and drive secure access without compromising data integrity and compliance? While it may sound simplistic, the first step towards managing high-quality data and right-sizing AI is defining the GenAI use cases for your business.
MaestroQA also offers a logic/keyword-based rules engine for classifying customer interactions based on other factors such as timing or process steps including metrics like Average Handle Time (AHT), compliance or process checks, and SLA adherence. Now, they are able to detect compliance risks with almost 100% accuracy.
A summary of sessions at the first DataEngineering Open Forum at Netflix on April 18th, 2024 The DataEngineering Open Forum at Netflix on April 18th, 2024. At Netflix, we aspire to entertain the world, and our dataengineering teams play a crucial role in this mission by enabling data-driven decision-making at scale.
Today’s data science and dataengineering teams work with a variety of machine learning libraries, data ingestion, and datastorage technologies. Risk and compliance considerations mean that the ability to reproduce machine learning workflows is essential to meet audits in certain application domains.
The solution had to adhere to compliance, privacy, and ethics regulations and brand standards and use existing compliance-approved responses without additional summarization. It was important for Principal to maintain fine-grained access controls and make sure all data and sources remained secure within its environment.
Prior to joining Lyft, Umare was a senior software engineer at Amazon and a principal engineer at Oracle, where he led development of a block storage product for an infrastructure-as-a-service and bare metal offering. “Data science is very academic, which directly affects machine learning.
Platform engineering teams work closely with both IT and business teams, fostering collaboration within the organization,” he says. AI is 100% disrupting platform engineering,” Srivastava says, so it’s important to have the skills in place to exploit that. “As Ignore security and compliance at your peril.
Everybody needs more data and more analytics, with so many different and sometimes often conflicting needs. Dataengineers need batch resources, while data scientists need to quickly onboard ephemeral users. Fundamental principles to be successful with Cloud data management. Or so they all claim.
Building applications with RAG requires a portfolio of data (company financials, customer data, data purchased from other sources) that can be used to build queries, and data scientists know how to work with data at scale. Dataengineers build the infrastructure to collect, store, and analyze data.
It is built around a data lake called OneLake, and brings together new and existing components from Microsoft Power BI, Azure Synapse, and Azure Data Factory into a single integrated environment. In many ways, Fabric is Microsoft’s answer to Google Cloud Dataplex. As of this writing, Fabric is in preview.
This includes Apache Hadoop , an open-source software that was initially created to continuously ingest data from different sources, no matter its type. Cloud data warehouses such as Snowflake, Redshift, and BigQuery also support ELT, as they separate storage and compute resources and are highly scalable. Compliance.
Snowflake, Redshift, BigQuery, and Others: Cloud Data Warehouse Tools Compared. From simple mechanisms for holding data like punch cards and paper tapes to real-time data processing systems like Hadoop, datastorage systems have come a long way to become what they are now. Is it still so? Scalability opportunities.
When our dataengineering team was enlisted to work on Tenable One, we knew we needed a strong partner. When Tenable’s product engineering team came to us in dataengineering asking how we could build a data platform to power the product, we knew we had an incredible opportunity to modernize our data stack.
And that some people in your company should be allowed to view that personal data, while others should not. And let’s say you have an employees table that looks like this: employee_id first_name yearly_income team_name 1 Marta 123.456 DataEngineers 2 Tim 98.765 Data Analysts You could provide access to this table in different ways.
Data architecture is the organization and design of how data is collected, transformed, integrated, stored, and used by a company. What is the main difference between a data architect and a dataengineer? By the way, we have a video dedicated to the dataengineering working principles.
Generally, if five LOB users use the data warehouse on a public cloud for eight hours a day for one month, you pay for the use of the service and the associated cloud hardware resources (compute and storage) for this period. 150 for storage use = $15 / TB / month x 10 TB. 150 for storage use = $15 / TB / month x 10 TB.
In the private sector, excluding highly regulated industries like financial services, the migration to the public cloud was the answer to most IT modernization woes, especially those around data, analytics, and storage. The source and availability of every material and part across each branch is an opportunity for risk.
Today’s general availability announcement covers Iceberg running within key data services in the Cloudera Data Platform (CDP) — including Cloudera Data Warehousing ( CDW ), Cloudera DataEngineering ( CDE ), and Cloudera Machine Learning ( CML ). Read why the future of data lakehouses is open.
Data curation will be a focus to understand the meaning of the data as well as the technologies that are applied to the data so that dataengineers can move and transform the essential data that data consumers need to power the organization.
In this article, well look at how you can use Prisma Cloud DSPM to add another layer of security to your Databricks operations, understand what sensitive data Databricks handles and enable you to quickly address misconfigurations and vulnerabilities in the storage layer. managed and unmanaged).
With CDP, customers can deploy storage, compute, and access, all with the freedom offered by the cloud, avoiding vendor lock-in and taking advantage of best-of-breed solutions. This enables a range of data stewardship and regulatory compliance use cases. Read why the future of data lakehouses is open.
eSentire has over 2 TB of signal data stored in their Amazon Simple Storage Service (Amazon S3) data lake. This further step updates the FM by training with data labeled by security experts (such as Q&A pairs and investigation conclusions).
Agencies are plagued by a wide range of data formats and storage environments—legacy systems, databases, on-premises applications, citizen access portals, innumerable sensors and devices, and more—that all contribute to a siloed ecosystem and the data management challenge. . That’s just the tip of the iceberg.
There is a clear consensus that data teams should express their goals and results in business value terms and not in technical, tactical descriptions, such as “improving dataengineering” and “better master data management.” . A large component of their role is data management related to regulatory compliance.
Taking action to leverage your data is a multi-step journey, outlined below: First, you have to recognize that sticking to the status quo is not an option. Your data demands, like your data itself, are outpacing your dataengineering methods and teams.
In general, a data infrastructure is a system of hardware and software tools used to collect, store, transfer, prepare, analyze, and visualize data. Check our article on dataengineering to get a detailed understanding of the data pipeline and its components. Big data infrastructure in a nutshell.
Data analysis and databases Dataengineering was by far the most heavily used topic in this category; it showed a 3.6% Dataengineering deals with the problem of storing data at scale and delivering that data to applications. Interest in data warehouses saw an 18% drop from 2022 to 2023.
Finally, it is critical to understand and plan for compliance with data regulations such as GDPR, especially for global operations. In our healthcare example, a multidisciplinary team might be necessary, encompassing data scientists and medical professionals for domain expertise and bioinformaticians for dataengineering.
Hybrid clouds must bond together the two clouds through fundamental technology, which will enable the transfer of data and applications. Data scientists, DevOps engineers, big data consultants, cloud architects, AppDev engineers, and many more – all of them smart and collaborative.
In most digital spheres, especially in fintech, where all business processes are tied to data processing, a good big dataengineer is worth their weight in gold. In this article, we’ll discuss the role of an ETL engineer in data processing and why businesses need such experts nowadays. Who Is an ETL Engineer?
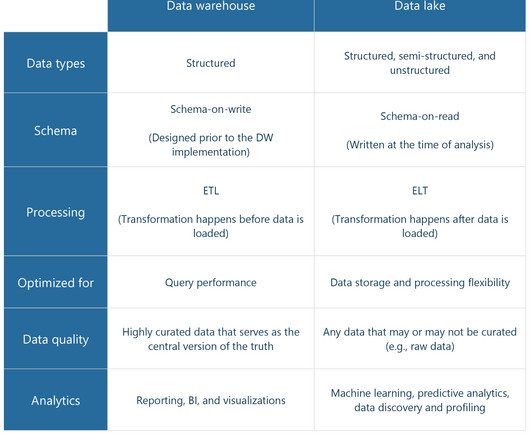
In this article, I will share practical insights and technologies utilized in building and harnessing the potential of data lakes. Demystifying Data Lakes Data lakes serve as flexible storage repositories, enabling organizations to store raw and diverse data types, breaking away from the constraints of traditional data warehouses.
While this “data tsunami” may pose a new set of challenges, it also opens up opportunities for a wide variety of high value business intelligence (BI) and other analytics use cases that most companies are eager to deploy. . Traditional data warehouse vendors may have maturity in datastorage, modeling, and high-performance analysis.
Next you need to understand your data , cataloging enterprise data into business and compliance terms. The most relevant use cases are those that use or integrate data, including publicly available data, and you combine that with your internal data.
“They combine the best of both worlds: flexibility, cost effectiveness of data lakes and performance, and reliability of data warehouses.”. It allows users to rapidly ingest data and run self-service analytics and machine learning. Make sure you have encryption for data in motion as well as at rest.
Similar to how DevOps once reshaped the software development landscape, another evolving methodology, DataOps, is currently changing Big Data analytics — and for the better. DataOps is a relatively new methodology that knits together dataengineering, data analytics, and DevOps to deliver high-quality data products as fast as possible.
Three types of data migration tools. Automation scripts can be written by dataengineers or ETL developers in charge of your migration project. This makes sense when you move a relatively small amount of data and deal with simple requirements. Phases of the data migration process. Data sources and destinations.
In 2010, a transformative concept took root in the realm of datastorage and analytics — a data lake. The term was coined by James Dixon , Back-End Java, Data, and Business Intelligence Engineer, and it started a new era in how organizations could store, manage, and analyze their data.
A data lakehouse , as the name suggests, is a new data architecture that merges data warehouse and data lake into a single whole, aiming at addressing each one’s limitations. In a nutshell, the lakehouse system leverages low-cost storage to keep large volumes of data in its raw formats just like data lakes.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















































Let's personalize your content