This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The processing workflow begins when documents are detected in the Extracts Bucket, triggering a comparison against existing processed files to prevent redundant operations. Multiple specialized Amazon Simple Storage Service Buckets (Amazon S3 Bucket) store different types of outputs. Click here to open the AWS console and follow along.
The cloud offers excellent scalability, while graph databases offer the ability to display incredible amounts of data in a way that makes analytics efficient and effective. Who is Big DataEngineer? Big Data requires a unique engineering approach. Big DataEngineer vs Data Scientist.
A columnar storage format like parquet or DuckDB internal format would be more efficient to store this dataset. This is not a fair comparison, because Spark has already inspected the CSV while creating the temporary view. DuckDB will apply the CSV-sniffer to inspect the CSV schema and data types before it can query the data.
On HDInsight, we spun up 10 workers with the same node type as CDW for a like-for-like comparison. A TPC-DS 10TB dataset was generated in ACID ORC format and stored on the ADLS Gen 2 cloud storage. Figure 1 – Overall Runtime Comparison. Both CDW and HDInsight had all 10 nodes running LLAP daemons with SSD cache ON.
Snowflake, Redshift, BigQuery, and Others: Cloud Data Warehouse Tools Compared. From simple mechanisms for holding data like punch cards and paper tapes to real-time data processing systems like Hadoop, datastorage systems have come a long way to become what they are now. What is a data warehouse?
An overview of data warehouse types. Optionally, you may study some basic terminology on dataengineering or watch our short video on the topic: What is dataengineering. What is data pipeline. This could be a transactional database or any other storage we take data from.
Let’s break them down: A data source layer is where the raw data is stored. Those are any of your databases, cloud-storages, and separate files filled with unstructured data. These are both a unified storage for all the corporate data and tools performing Extraction, Transformation, and Loading (ETL).
Second, since IaaS deployments replicated the on-premises HDFS storage model, they resulted in the same data replication overhead in the cloud (typical 3x), something that could have mostly been avoided by leveraging modern object store. Storage costs. using list pricing of $0.72/hour hour using a r5d.4xlarge
ADF is a Microsoft Azure tool widely utilized for data ingestion and orchestration tasks. A typical scenario for ADF involves retrieving data from a database and storing it as files in an online blob storage, which applications can utilize downstream. An Azure Key Vault is created to store any secrets.
This includes Apache Hadoop , an open-source software that was initially created to continuously ingest data from different sources, no matter its type. Cloud data warehouses such as Snowflake, Redshift, and BigQuery also support ELT, as they separate storage and compute resources and are highly scalable.
In addition, data pipelines include more and more stages, thus making it difficult for dataengineers to compile, manage, and troubleshoot those analytical workloads. CRM platforms). Limited flexibility to use more complex hosting models (e.g., benchmarking study conducted by independent 3rd party ).
That’s why a lot of enterprises look for an experienced Big Dataengineer to add to their team. According to Businesswire , the global Big Data analytics market is expected to reach $105 billion by 2027. Benefits of Hiring a DataEngineer Freelance. Top Sites to Hire a Data Analyst Freelance.
Similar to humans companies generate and collect tons of data about the past. And this data can be used to support decision making. While our brain is both the processor and the storage, companies need multiple tools to work with data. And one of the most important ones is a data warehouse. Subject-oriented data.
What is Databricks Databricks is an analytics platform with a unified set of tools for dataengineering, data management , data science, and machine learning. It combines the best elements of a data warehouse, a centralized repository for structured data, and a data lake used to host large amounts of raw data.
We suggest drawing a detailed comparison of Azure vs AWS to answer these questions. Azure vs AWS comparison: other practical aspects. The side-by-side comparison of Azure vs AWS as top providers can serve as a helpful guide there. . List of the Content. Azure vs AWS market share. What is Microsoft Azure used for?
Key zones of an Enterprise Data Lake Architecture typically include ingestion zone, storage zone, processing zone, analytics zone, and governance zone. Ingestion zone is where data is collected from various sources and ingested into the data lake. Storage zone is where the raw data is stored in its original format.
In most digital spheres, especially in fintech, where all business processes are tied to data processing, a good big dataengineer is worth their weight in gold. In this article, we’ll discuss the role of an ETL engineer in data processing and why businesses need such experts nowadays. Who Is an ETL Engineer?
The data journey from different source systems to a warehouse commonly happens in two ways — ETL and ELT. The former extracts and transforms information before loading it into centralized storage while the latter allows for loading data prior to transformation. Each node has its own disk storage. Database storage layer.
As more and more enterprises drive value from container platforms, infrastructure-as-code solutions, software-defined networking, storage, continuous integration/delivery, and AI, they need people and skills on board with ever more niche expertise and deep technological understanding.
A growing number of companies now use this data to uncover meaningful insights and improve their decision-making, but they can’t store and process it by the means of traditional datastorage and processing units. Key Big Data characteristics. Datastorage and processing. Apache Spark.
The Cloudera Data Platform comprises a number of ‘data experiences’ each delivering a distinct analytical capability using one or more purposely-built Apache open source projects such as Apache Spark for DataEngineering and Apache HBase for Operational Database workloads.
Data is a valuable source that needs management. If your business generates tons of data and you’re looking for ways to organize it for storage and further use, you’re at the right place. Read the article to learn what components data management consists of and how to implement a data management strategy in your business.
Its flexibility allows it to operate on single-node machines and large clusters, serving as a multi-language platform for executing dataengineering , data science , and machine learning tasks. Before diving into the world of Spark, we suggest you get acquainted with dataengineering in general.
Three types of data migration tools. Automation scripts can be written by dataengineers or ETL developers in charge of your migration project. This makes sense when you move a relatively small amount of data and deal with simple requirements. Phases of the data migration process. Data sources and destinations.
But before you dive in, we recommend you reviewing our more beginner-friendly articles on data transformation: Complete Guide to Business Intelligence and Analytics: Strategy, Steps, Processes, and Tools. What is DataEngineering: Explaining the Data Pipeline, Data Warehouse, and DataEngineer Role.
Data integration process. On the enterprise level, data integration may cover a wider array of data management tasks including. application integration — the process of enabling individual applications to communicate with one another by exchanging data. How to choose data integration software: key comparison criteria.
There are several pillar data sets you have to consider in the first place. Important hotel data sets and overlaps between them. Booking and property data. The main storage of hotel booking information is your property management system (PMS). Data processing in a nutshell and ETL steps outline.
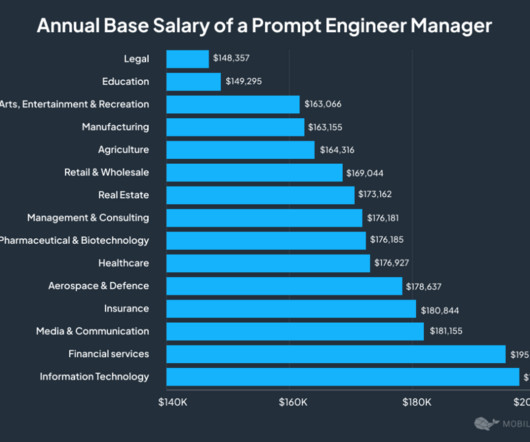
Mastery of the emerging tools (Hugging Face, LangChain) requires programming, dataengineering, and traditional AI skills that increase the earning potential of prompt engineers. Platform-specific expertise. Industry and location.
It’s easier to get this information from the aforementioned providers that gather data from a system of sensors, diverse third-party sources, or make use of GPS probe data. Other platforms such as Otonomo use an innovative Vehicle to Everything (V2X) technology to collect so-called connected car data from embedded modems.
About Foreign Data Wrappers. Relational databases like PostgreSQL (PG) have long been dominant for datastorage and access, but sometimes you need access from your application to data that’s either in a different database format, in a non-relational database, or not in a database at all. Setting the Environment.
Power BI Desktop is a free, downloadable app that’s included in all Office 365 Plans, so all you need to do is sign up, connect to data sources, and start creating your interactive, customizable reports using a drag-and-drop canvas and hundreds of data visuals. You get 10GB of cloud storage and can upload 1GB of data at a time.
“The fine art of dataengineering lies in maintaining the balance between data availability and system performance.” Semi-Structured Storage : Measurement values have varying types (e.g., Choosing between flexibility or performance is a classic dataengineering dilemma. HT2 lot_002 FAILED 1.5
While you definitely saw the Docker vs Kubernetes comparison, these two systems cannot be compared directly. A container engine acts as an interface between the containers and a host operating system and allocates the required resources. Solutions such as Kubernetes are used to orchestrate container environments.
This post was co-written with Vishal Singh, DataEngineering Leader at Data & Analytics team of GoDaddy Generative AI solutions have the potential to transform businesses by boosting productivity and improving customer experiences, and using large language models (LLMs) in these solutions has become increasingly popular.
Year-over-year comparisons are based on the same period in 2023. The data in each graph is based on OReillys units viewed metric, which measures the actual use of each item on the platform. Therefore, its not surprising that DataEngineering skills showed a solid 29% increase from 2023 to 2024. Finally, ETL grew 102%.
Analyzing business information to facilitate data-driven decision making is what we call business intelligence or BI. In plain language, BI is a set of tools and methods to extract raw data from its source, transform it, load into a unified storage, and present to the user. Source: skylinetechnologies.com. Thanks, Depeche Mode!
Those gains only look small in comparison to the triple- and quadruple-digit gains we’re seeing in natural language processing. This is solid, substantial growth that only looks small in comparison with topics like generative AI. Dataengineering deals with the problem of storing data at scale and delivering that data to applications.
We used data from the first nine months (January through September) of 2021. When doing year-over-year comparisons, we used the first nine months of 2020. Data analysis” and “dataengineering” are far down in the list—possibly indicating that, while pundits are making much of the distinction, our platform users aren’t.
Whether centralized or distributed, architecture shapes how data flows, how easily it can be trusted and how responsive systems are to change. As data volumes and use cases scale especially with AI and real-time analytics trust must be an architectural principle, not an afterthought. Exploratory analytics, raw and diverse data types.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content