This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Considering dataengineering and data science, Astro and Apache Airflow rise to the top as important tools used in the management of these data workflows. This article compares Astro and Apache Airflow, explaining their architecture, features, scalability, usability, community support, and integration capabilities.
In legacy analytical systems such as enterprise data warehouses, the scalability challenges of a system were primarily associated with computational scalability, i.e., the ability of a data platform to handle larger volumes of data in an agile and cost-efficient way. CRM platforms).
The edtech veteran is right: the next-generation of edtech is still looking for ways to balance motivation and behavior change, offered at an accessible price point in a scalable format. For comparison, a single course on Maven – perhaps this one on founder finance – can cost $2,000. “We’re
Technologies that have expanded Big Data possibilities even further are cloud computing and graph databases. The cloud offers excellent scalability, while graph databases offer the ability to display incredible amounts of data in a way that makes analytics efficient and effective. Who is Big DataEngineer?
In this article, we will compare Databricks Streaming and Apache Flink to understand the underlying architecture, performance, scalability, latency and fault tolerance characteristics as well as programming model differences between them.
but have you really examined the stream processing engines out there in a side-by-side comparison to make sure? Our Choose the Right Stream Processing Engine for Your Data Needs whitepaper makes those comparisons for you, so you can quickly and confidently determine which engine best meets your key business requirements.
This form of understanding could possibly be enabled using popular data exploration and visualization approaches, like hierarchical clustering and dimensionality reduction techniques. model comparison and performance evaluation. Model comparison using Skater between different types of supervised predictive models. interpreter.
Before jumping into the comparison of available products right away, it will be a good idea to get acquainted with the data warehousing basics first. What is a data warehouse? The variety of data explodes and on-premises options fail to handle it. Scalability opportunities. Scalability. Scalability.
This includes Apache Hadoop , an open-source software that was initially created to continuously ingest data from different sources, no matter its type. Cloud data warehouses such as Snowflake, Redshift, and BigQuery also support ELT, as they separate storage and compute resources and are highly scalable.
The Cloudera Data Platform comprises a number of ‘data experiences’ each delivering a distinct analytical capability using one or more purposely-built Apache open source projects such as Apache Spark for DataEngineering and Apache HBase for Operational Database workloads.
The framework that I built for that comparison includes three dimensions: Technology cost rationalization by converting a fixed, cost structure associated with Cloudera subscription costs per node into a variable cost model based on actual consumption. data streaming, dataengineering, data warehousing etc.),
Three types of data migration tools. Automation scripts can be written by dataengineers or ETL developers in charge of your migration project. This makes sense when you move a relatively small amount of data and deal with simple requirements. Use cases: moving data from on-premises to cloud or between cloud environments.
This comparison will help you make an informed decision and ensure that your data flows smoothly. Airbyte, a leading open-source data integration platform, boasts over 35,000 deployments across open-source users and Airbyte Cloud subscribers. Incremental Syncs: Reduce data transfer costs with incremental data updates.
A parameter is a named entity that defines values that can be reused across various components within your data factory. Parameters can be utilized to make your data factory more dynamic, flexible, easier to maintain, and scalable. An Azure Key Vault is created to store any secrets.
What is Databricks Databricks is an analytics platform with a unified set of tools for dataengineering, data management , data science, and machine learning. It combines the best elements of a data warehouse, a centralized repository for structured data, and a data lake used to host large amounts of raw data.
On top of that, new technologies are constantly being developed to store and process Big Data allowing dataengineers to discover more efficient ways to integrate and use that data. You may also want to watch our video about dataengineering: A short video explaining how dataengineering works.
We suggest drawing a detailed comparison of Azure vs AWS to answer these questions. Azure vs AWS comparison: other practical aspects. The side-by-side comparison of Azure vs AWS as top providers can serve as a helpful guide there. . List of the Content. Azure vs AWS market share. What is Microsoft Azure used for?
Еnterprise data lake services can help transform raw data into a structured format that is easier to analyze. Data Security. With enterprise data lake services, you can keep your data secure. Scalability. Analytics Data lake design services can provide tools for data analysts and data scientists.
Data integration and interoperability: consolidating data into a single view. Specialist responsible for the area: data architect, dataengineer, ETL developer. MDM activities include accumulating, cleansing of data, its comparison, consolidation, quality control. Cloudera Data Platform capabilities.
Not to mention that they require a decent level of expertise to develop, deploy, and maintain data integration flows. Now that you have a general picture of what data integration tools are, let’s move to the comparison of popular vendors. How to choose data integration software: key comparison criteria.
This approach demands significant investments in software, equipment, and human resources to create advanced data architecture, but the resulting accuracy and visibility are worth paying for. Comparison between traditional and machine learning approaches to demand forecasting. Deployment type is another big decision to make.
With the consistent rise in data volume, variety, and velocity, organizations started seeking special solutions to store and process the information tsunami. This demand gave birth to cloud data warehouses that offer flexibility, scalability, and high performance. Great performance and scalability.
Whether your goal is data analytics or machine learning , success relies on what data pipelines you build and how you do it. But even for experienced dataengineers, designing a new data pipeline is a unique journey each time. Dataengineering in 14 minutes. Scalability. ELT use cases.
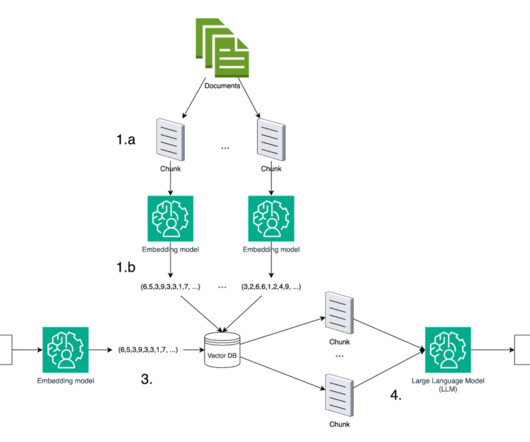
This clearly isn’t a scalable approach though, we were only able to do this because our document set is small enough (<1k tokens per document) to easily fit within the 100k token context length. The results from asking our test set of questions was impressive, it got them all completely correct!
Its flexibility allows it to operate on single-node machines and large clusters, serving as a multi-language platform for executing dataengineering , data science , and machine learning tasks. Before diving into the world of Spark, we suggest you get acquainted with dataengineering in general.
And this is what makes a data warehouse different from a Data Lake. Data Lakes are used to store unstructured data for analytical purposes. But unlike warehouses, data lakes are used more by dataengineers/scientists to work with big sets of raw data. Subject-oriented data.
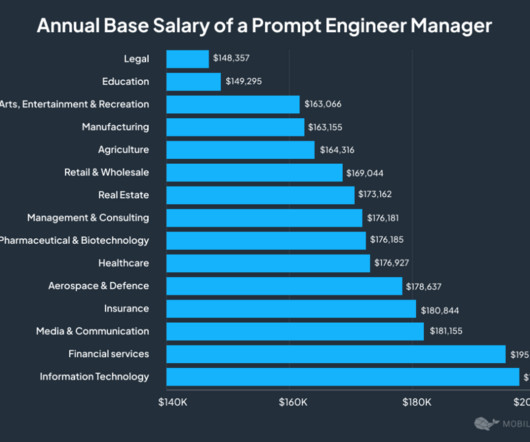
Mastery of the emerging tools (Hugging Face, LangChain) requires programming, dataengineering, and traditional AI skills that increase the earning potential of prompt engineers. Platform-specific expertise. Industry and location.
Typical roles you’ll find on dedicated teams include: Application developers Quality assurance experts and software testers UI/UX designers AI and dataengineers Project managers Other specialized experts tailored to your project’s specific needs When are dedicated teams a good idea for your company?
In this primer we’ll show how to use FDWs to front-end your own datastores, and to allow JOINs with native PG data and data stored in other FDW-accessible systems. We use FDWs this way at Kentik as part of the Kentik DataEngine (KDE) that powers Kentik Detect, the massively scalable big data-based SaaS for network visibility.
Although independent contractors integration and long-term availability cannot match hiring full-time employees they offer a range of unique advantages of hiring (for example, hiring speed, lower cost of hiring, scalability) compared to in-house employees. Below is a detailed comparison to help your business weigh the options effectively.
“The fine art of dataengineering lies in maintaining the balance between data availability and system performance.” Even more perplexing: DuckDB , a lightweight single-node engine, outpaced Databricks on smaller subsets. Choosing between flexibility or performance is a classic dataengineering dilemma.
Tech companies use data science to enhance user experience, create personalized recommendation systems, develop innovative solutions, and more. Data science in agriculture can help businesses develop data pipelines specifically for automation and fast scalability. Agriculture. Netherlands.
While you definitely saw the Docker vs Kubernetes comparison, these two systems cannot be compared directly. Scalability. Containers are highly scalable and can be expanded relatively easily. Container environments can be operated on local computers on-premises or provided via private and public clouds.
Year-over-year comparisons are based on the same period in 2023. The data in each graph is based on OReillys units viewed metric, which measures the actual use of each item on the platform. Therefore, its not surprising that DataEngineering skills showed a solid 29% increase from 2023 to 2024.
This post was co-written with Vishal Singh, DataEngineering Leader at Data & Analytics team of GoDaddy Generative AI solutions have the potential to transform businesses by boosting productivity and improving customer experiences, and using large language models (LLMs) in these solutions has become increasingly popular.
Depending on the type of logical connection and data itself, visualization can be done in a suitable format. So it’s dead simple, any analytical report contains examples of data interpretations like pie charts, comparison bars, demographic maps, and many more. Data visualization tools and libraries.
A popular choice, since it’s a fully-managed data warehouse that’s highly scalable and offers top-tier data analytics capabilities , alongside robust access control. Tip 2: Implement Table Comparison Tools When migrating business logic from SAS to Snowflake, validation is crucial. So not a bad choice.
We also examine how centralized, hybrid and decentralized data architectures support scalable, trustworthy ecosystems. As data-centric AI, automated metadata management and privacy-aware data sharing mature, the opportunity to embed data quality into the enterprises core has never been more significant.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content