This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The following is a review of the book Fundamentals of DataEngineering by Joe Reis and Matt Housley, published by O’Reilly in June of 2022, and some takeaway lessons. The authors state that the target audience is technical people and, second, business people who work with technical people. Nevertheless, I strongly agree.
The dataengineering that precedes analytics was covered in our previous post, DataEngineering: The Heavy Lifting Behind IoT. Incontestably, industrial IoT’s claim to fame is the visibility it brings to previously inaccessible phenomena. […].
diversity of sales channels, complex structure resulting in siloed data and lack of visibility. These challenges can be addressed by intelligent management supported by data analytics and businessintelligence (BI) that allow for getting insights from available data and making data-informed decisions to support company development.
With the uprise of internet-of-things (IoT) devices, overall data volume increase, and engineering advancements in this field led to new ways of collecting, processing, and analysing data. As a result, it became possible to provide real-time analytics by processing streamed data. Batch processing.
BusinessIntelligence Analyst. A BI analyst has strong skills in database technology, analytics, and reporting tools and excellent knowledge and understanding of computer science, information systems or engineering. BI Analyst can also be described as BI Developers, BI Managers, and Big DataEngineer or Data Scientist.
Imagine you’re a dataengineer at a Fortune 1000 company. Your company has thousands of databases and 14,000 businessintelligence users. You use data virtualization to create data views, configure security, and share data. One: Streaming Data Virtualization. All this data is in motion.
These can be data science teams , data analysts, BI engineers, chief product officers , marketers, or any other specialists that rely on data in their work. The simplest illustration for a data pipeline. Data pipeline components. Data pipeline components. When do you need a data pipeline?
InsureApp is another company that contextualizes behavior and translates it into personalized insurance by combining and interpreting data from smartphone sensors and IoT devices. You can start investing in data infrastructure and analytical pipelines to automate data collection and analysis mechanisms.
Machine learning, artificial intelligence, dataengineering, and architecture are driving the data space. The Strata Data Conferences helped chronicle the birth of big data, as well as the emergence of data science, streaming, and machine learning (ML) as disruptive phenomena.
Data integration and interoperability: consolidating data into a single view. Specialist responsible for the area: data architect, dataengineer, ETL developer. Scattered across different storages in various formats, data values don’t talk to each other. Snowflake data management processes.
The Microsoft Fabric platform includes: Power BI : The Microsoft businessintelligence tool that’s a mainstay for many organizations, infused with a generative AI copilot for business analysts and business users. Data Factory : A data integration tool with 150+ connectors to cloud and on-premises data sources.
Neural networks are composed of interconnected processing nodes called neurons, which can learn to recognize patterns of input data. Businessintelligence. Businessintelligence involves using data analysis techniques to help businesses make better decisions about their operations and strategies.
To understand Big Data, you need to get acquainted with its attributes known as the four V’s: Volume is what hides in the “big” part of Big Data. This relates to terabytes to petabytes of information coming from a range of sources such as IoT devices, social media, text files, business transactions, etc.
Whether your goal is data analytics or machine learning , success relies on what data pipelines you build and how you do it. But even for experienced dataengineers, designing a new data pipeline is a unique journey each time. Dataengineering in 14 minutes. Data availability. ELT vs ETL.
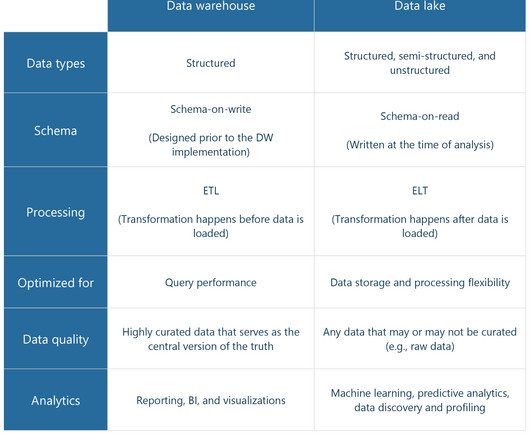
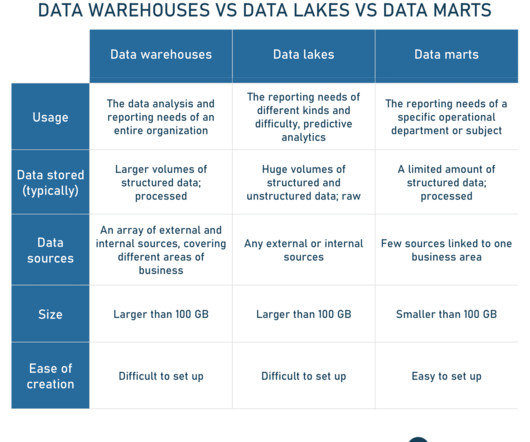
At the same time, it brings structure to data and empowers data management features similar to those in data warehouses by implementing the metadata layer on top of the store. Traditional data warehouse platform architecture. Data lake architecture example. Poor data quality, reliability, and integrity.
In 2010, a transformative concept took root in the realm of data storage and analytics — a data lake. The term was coined by James Dixon , Back-End Java, Data, and BusinessIntelligenceEngineer, and it started a new era in how organizations could store, manage, and analyze their data.
Such an approach requires a great deal of investment since a whole ecosystem has to be created, including IoT sensors installation, acquiring specialized software, creating and maintaining machine learning (ML) models, engaging IT and data science specialists , and so on. Collecting data from connected sensors and external sources.
With a data warehouse, an enterprise is able to manage huge data sets, without administering multiple databases. Such practice is a futureproof way of storing data for businessintelligence (BI) , which is a set of methods/technologies of transforming raw data into actionable insights. Subject-oriented data.
The technology was written in Java and Scala in LinkedIn to solve the internal problem of managing continuous data flows. In other words, Kafka can serve as a messaging system, commit log, data integration tool, and stream processing platform. A subscriber is a receiving program such as an end-user app or businessintelligence tool.
Decentralized data ownership by domain. Zhamak Dehghani divides the data into the “two planes”: The operational plane presents the data from the source systems where it originates — for example, front-desk apps, IoT systems , point of sales systems , etc. And it’s their job to guarantee data quality.
Today, companies want their business decisions to be driven by data. But here’s the thing — information required for businessintelligence (BI) and analytics processes often lives in a breadth of databases and applications. These systems can be hosted on-premises, in the cloud, and on IoT devices, etc.
Due to extensive usage of connected IoT devices and advanced processing technologies, SCCTs not only gather data and build operational reports but also create predictions, define the impact of various macro- and microeconomic factors on the supply chain, and run “what-if” scenarios to find the best course of action. Data siloes.
In addition to AI consulting, the company has expertise in delivering a wide range of AI development services , such as Generative AI services, Custom LLM development , AI App Development, DataEngineering, RAG As A Service , GPT Integration, and more. The platform helps with predictive maintenance and optimized asset management.
Data collection is a methodical practice aimed at acquiring meaningful information to build a consistent and complete dataset for a specific business purpose — such as decision-making, answering research questions, or strategic planning. For this task, you need a dedicated specialist — a dataengineer or ETL developer.
Its flexibility allows it to operate on single-node machines and large clusters, serving as a multi-language platform for executing dataengineering , data science , and machine learning tasks. Before diving into the world of Spark, we suggest you get acquainted with dataengineering in general. Stream processing.
TIBCO DQ will become the new data quality product family, through an evolution of our current data quality offerings, significantly enhancing current capabilities available throughout the TIBCO data fabric with built-in AI and ML to automate quality, detection, monitoring, and anomaly resolution.
Ronald van Loon has been recognized among the top 10 global influencers in Big Data, analytics, IoT, BI, and data science. As the director of Advertisement, he works to help data-driven businesses be more successful. Borba has been named a top Big Data and data science influencer and expert several times.
We will describe each level from the following perspectives: differences on the operational level; analytics tools companies use to manage and analyze data; businessintelligence applications in real life; challenges to overcome and key changes that lead to transition. Introducing dataengineering and data science expertise.
Case study: leveraging AgileEngine as a data solutions vendor 11. Key takeaways Any organization that operates online and collects data can benefit from a data analytics consultancy, from blockchain and IoT, to healthcare and financial services The market for data analytics globally was valued at $112.8
According to an IDG survey , companies now use an average of more than 400 different data sources for their businessintelligence and analytics processes. What’s more, 20 percent of these companies are using 1,000 or more sources, far too many to be properly managed by human dataengineers. Conclusion.
That’s why some MDS tools are commercial distributions designed to be low-code or even no-code, making them accessible to data practitioners with minimal technical expertise. This means that companies don’t necessarily need a large dataengineering team. Data democratization. Data sources component in a modern data stack.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






































Let's personalize your content