This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The following is a review of the book Fundamentals of DataEngineering by Joe Reis and Matt Housley, published by O’Reilly in June of 2022, and some takeaway lessons. The authors state that the target audience is technical people and, second, business people who work with technical people. Nevertheless, I strongly agree.
Once the province of the data warehouse team, data management has increasingly become a C-suite priority, with data quality seen as key for both customer experience and business performance. But along with siloed data and compliance concerns , poor data quality is holding back enterprise AI projects.
By integrating Azure Key Vault Secrets with Azure Synapse Analytics, organizations can securely access external data sources and manage credentials centrally. This integration not only improves security by ensuring that secrets in code or configuration files are never exposed but also improves compliance with regulatory standards.
diversity of sales channels, complex structure resulting in siloed data and lack of visibility. These challenges can be addressed by intelligent management supported by data analytics and businessintelligence (BI) that allow for getting insights from available data and making data-informed decisions to support company development.
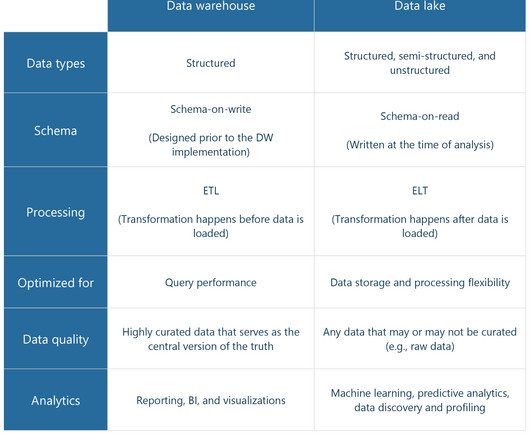
Traditionally, organizations have maintained two systems as part of their data strategies: a system of record on which to run their business and a system of insight such as a data warehouse from which to gather businessintelligence (BI). You can intuitively query the data from the data lake.
Finance: Data on accounts, credit and debit transactions, and similar financial data are vital to a functioning business. But for data scientists in the finance industry, security and compliance, including fraud detection, are also major concerns. Data scientist skills.
Building applications with RAG requires a portfolio of data (company financials, customer data, data purchased from other sources) that can be used to build queries, and data scientists know how to work with data at scale. Dataengineers build the infrastructure to collect, store, and analyze data.
It is built around a data lake called OneLake, and brings together new and existing components from Microsoft Power BI, Azure Synapse, and Azure Data Factory into a single integrated environment. In many ways, Fabric is Microsoft’s answer to Google Cloud Dataplex. As of this writing, Fabric is in preview.
From the late 1980s, when data warehouses came into view, and up to the mid-2000s, ETL was the main method used in creating data warehouses to support businessintelligence (BI). As data keeps growing in volumes and types, the use of ETL becomes quite ineffective, costly, and time-consuming. Compliance.
Today’s general availability announcement covers Iceberg running within key data services in the Cloudera Data Platform (CDP) — including Cloudera Data Warehousing ( CDW ), Cloudera DataEngineering ( CDE ), and Cloudera Machine Learning ( CML ). Read why the future of data lakehouses is open.
There are many articles that point to the explosion of data, but in order for that data that be useful for analytics and ML, it has to be collected, transported, cleaned, stored, and combined with other data sources. Data Platforms. Data Integration and Data Pipelines. Model lifecycle management.
It serves as a foundation for the entire data management strategy and consists of multiple components including data pipelines; , on-premises and cloud storage facilities – data lakes , data warehouses , data hubs ;, data streaming and Big Data analytics solutions ( Hadoop , Spark , Kafka , etc.);
Legacy data sharing involves proliferating copies of data, creating data management, and security challenges. Data quality issues deter trust and hinder accurate analytics. Disparate systems create issues with transparency and compliance. Lack of sharing hinders the elimination of fraud, waste, and abuse.
It provides a suite of tools for dataengineering, data science, businessintelligence, and analytics. Answering questions about a clinical encounters principal diagnosis, test ordered, or a research abstracts study design or main outcomes Example: Question answering Model De-identification E.
It is usually created and used primarily for data reporting and analysis purposes. Thanks to the capability of data warehouses to get all data in one place, they serve as a valuable businessintelligence (BI) tool, helping companies gain business insights and map out future strategies. Integrations.
External metrics can be implemented using BusinessIntelligence (BI) tools and shared with the clients to measure performance. They come in all flavors: different formats, templates, and from different legal processes, sizes, and quality. Internal metrics can be very technical, like hyperparameters, which can be tuned over time.
Tools like Apache Atlas and Collibra provide features to organize, catalog, and document data assets within the data lake. They help establish data lineage, enable data discovery, and enforce compliance with data governance policies.
Similar to how DevOps once reshaped the software development landscape, another evolving methodology, DataOps, is currently changing Big Data analytics — and for the better. DataOps is a relatively new methodology that knits together dataengineering, data analytics, and DevOps to deliver high-quality data products as fast as possible.
Here, we introduce you to ETL testing – checking that the data safely traveled from its source to its destination and guaranteeing its high quality before it enters your BusinessIntelligence reports. What is DataEngineering: Explaining the Data Pipeline, Data Warehouse, and DataEngineer Role.
Some data warehousing solutions such as appliances and engineered systems have attempted to overcome these problems, but with limited success. . Recently, cloud-native data warehouses changed the data warehousing and businessintelligence landscape.
That data may be used in ways that don’t comply with appropriate security and governance policies. That data may be hard to discover for other users and other applications. That data may be hard to track for audit and compliance purposes. There is a better way.
Today, modern data warehousing has evolved to meet the intensive demands of the newest analytics required for a business to be data driven. Traditional data warehouse vendors may have maturity in data storage, modeling, and high-performance analysis.
“They combine the best of both worlds: flexibility, cost effectiveness of data lakes and performance, and reliability of data warehouses.”. It allows users to rapidly ingest data and run self-service analytics and machine learning. Compliance monitoring and incident response. Data loss prevention.
Whether a new or existing contract, it has to be thoroughly reviewed to ensure clear, unambiguous phrasing of all clauses and variations, compliance to current regulations, absence of hidden risks, pitfalls, or fees, and so on. Compliance evaluation. Invoice and payment analytics to detect errors, compliance issues, and fraud.
At the same time, it brings structure to data and empowers data management features similar to those in data warehouses by implementing the metadata layer on top of the store. Traditional data warehouse platform architecture. Data lake architecture example. Poor data quality, reliability, and integrity.
Openxcell is always ready to understand your project needs and use AI’s full potential to deliver a solution that propels your business forward. The company offers a wide range of AI Development services, such as Generative AI services, Custom LLM development , AI App Development , DataEngineering , GPT Integration , and more.
The demand for specialists who know how to process and structure data is growing exponentially. In most digital spheres, especially in fintech, where all business processes are tied to data processing, a good big dataengineer is worth their weight in gold. Who Is an ETL Engineer?
It’s often used by internal apps managing business processes — ERPs, accounting software, and medical practice management systems , to name just a few. The analytical plane embraces data that is collected and transformed for analytical purposes such as enterprise reporting, businessintelligence , data science , etc.
Data has to be easy to find, understand, access, and use for everyone in the chain: dataengineers, analysts, data scientists, and business users. It makes the data more accessible and understandable to everyone, especially less-skilled data consumers.
In many cases we see that customers prefer to have their data stored and managed locally in their home region, both for reasons of regulatory compliance and also business preference. A mart is a group of aggregated tables (e.g.,
In 2010, a transformative concept took root in the realm of data storage and analytics — a data lake. The term was coined by James Dixon , Back-End Java, Data, and BusinessIntelligenceEngineer, and it started a new era in how organizations could store, manage, and analyze their data.
Data stewards – provide oversight of data sets to maintain data integrity and ensure implementation of policies from the committee and end-user compliance with the policies. Others – data modelers, dataengineers, data architects, and data quality analysts also contribute to the DG process.
Efficient metadata management ensures data integrity , consistency, trustworthiness, and compliance. To ensure metadata quality as well as correct application of metadata policies and proper compliance to requirements and standards, audits have to be regularly conducted by data stewards. Risk management and compliance.
TIBCO DQ will become the new data quality product family, through an evolution of our current data quality offerings, significantly enhancing current capabilities available throughout the TIBCO data fabric with built-in AI and ML to automate quality, detection, monitoring, and anomaly resolution.
Amazon Q can also help employees do more with the vast troves of data and information contained in their company’s documents, systems, and applications by answering questions, providing summaries, generating businessintelligence (BI) dashboards and reports, and even generating applications that automate key tasks.
Introduction With the growing availability of cloud and AI, the data collected by organizations is now worth its weight in gold. Large-scale, granular, and actionable data analytics is more accessible than ever, but it still comes with numerous challenges. That’s where data analytics consultancies come into play.
What is Databricks Databricks is an analytics platform with a unified set of tools for dataengineering, data management , data science, and machine learning. It combines the best elements of a data warehouse, a centralized repository for structured data, and a data lake used to host large amounts of raw data.
That’s why some MDS tools are commercial distributions designed to be low-code or even no-code, making them accessible to data practitioners with minimal technical expertise. This means that companies don’t necessarily need a large dataengineering team. Data democratization. Data use component in a modern data stack.
However, in the typical enterprise, only a small team has the core skills needed to gain access and create value from streams of data. This dataengineering skillset typically consists of Java or Scala programming skills mated with deep DevOps acumen. A rare breed. What do you mean by democratizing?
Embracing generative AI with Amazon Bedrock The company has identified several use cases where generative AI can significantly impact operations, particularly in analytics and businessintelligence (BI). This tool democratizes data access across the organization, enabling even nontechnical users to gain valuable insights.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content