This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Once an organization has extracted data from their security tools, Monad’s Security Data Platform enables them to centralize that data within a data warehouse of choice, and normalize and enrich the data so that security teams have the insights they need to secure their systems and data effectively.
This opens a web-based development environment where you can create and manage your Synapse resources, including data integration pipelines, SQL queries, Spark jobs, and more. Link External Data Sources: Connect your workspace to external data sources like Azure Blob Storage, Azure SQL Database, and more to enhance data integration.
Harnessing the power of bigdata has become increasingly critical for businesses looking to gain a competitive edge. However, managing the complex infrastructure required for bigdata workloads has traditionally been a significant challenge, often requiring specialized expertise.
Thomas Kurian, CEO of Google Cloud, introduced Traffic Director, the new global traffic management service for VMs and containers as well as Cloud Run, which allows you to run any container in a serverless environment. Cloud Data Fusion. Bigdata got some big news today as well. And there’s more to come!
Many companies are just beginning to address the interplay between their suite of AI, bigdata, and cloud technologies. I’ll also highlight some interesting uses cases and applications of data, analytics, and machine learning. Data Platforms. Data Integration and Data Pipelines. Model lifecycle management.
In the age of bigdata, where information is generated at an unprecedented rate, the ability to integrate and manage diverse data sources has become a critical business imperative. Traditional data integration methods are often cumbersome, time-consuming, and unable to keep up with the rapidly evolving data landscape.
Serverless architecture is another buzzword to hit the cloud-native space, but what is it, is it worthwhile and how can it work for you? Serverless architecture is on the rise and is rapidly gaining acceptance. What is Serverless Architecture? In serverless applications, a cloud provider manages the provision of servers.
The course will begin with the installation of a MySQL server, then cover common administrative tasks like creating databases and tables, inserting and viewing data, and running backups for recovery. We will also cover the different data types that are allowed in MySQL, and discuss user access and privileges. BigData Essentials.
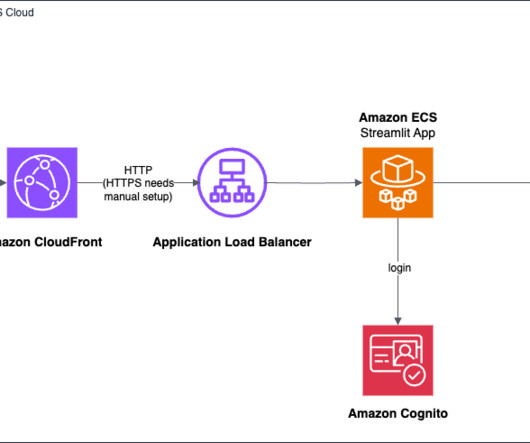
He enjoys supporting customers in their digital transformation journey, using bigdata, machine learning, and generative AI to help solve their business challenges. The AWS deployment architecture makes sure the Python application is hosted and accessible from the internet to authenticated users.
One such service is their serverless computing service , AWS Lambda. For the uninitiated, Lambda is an event-driven serverless computing platform that lets you run code without managing or provisioning servers and involves zero administration. What makes AWS Lambda, the most sought after serverless framework ? You may ask.
Performance optimization The serverless architecture used in this post provides a scalable solution out of the box. He enjoys supporting customers in their digital transformation journey, using bigdata, machine learning, and generative AI to help solve their business challenges.
Just a few years ago, MapR was considered one of the Unicorns (startups that were valued at a billion dollars or more) in the BigData Analytics market which is a booming market. MarketWatch estimates that the global bigdata market is expected to grow at a CAGR of 22.4%
These seemingly unrelated terms unite within the sphere of bigdata, representing a processing engine that is both enduring and powerfully effective — Apache Spark. Maintained by the Apache Software Foundation, Apache Spark is an open-source, unified engine designed for large-scale data analytics. Bigdata processing.
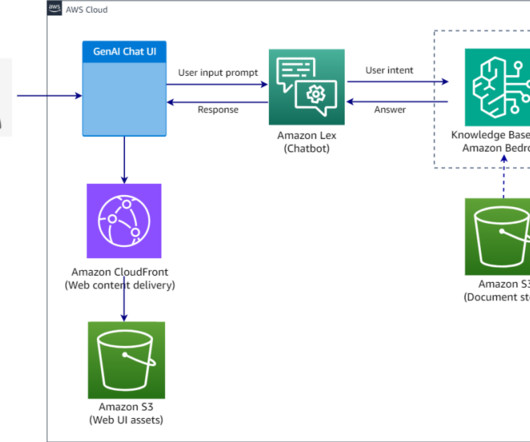
In this post, we demonstrate how you can build chatbots with QnAIntent that connects to a knowledge base in Amazon Bedrock (powered by Amazon OpenSearch Serverless as a vector database ) and build rich, self-service, conversational experiences for your customers. She is passionate about designing cloud-centered bigdata workloads.
Examples of such workloads are bigdata, containerized workloads, CI/CD, web servers, and high-performance computing (HPC). These case studies present some of the companies using serverless like Robot, FINRA, and Thomson Reuters. Rearchitecting. Relational Databases.
If you have built or are building a Data Lake on the Google Cloud Platform (GCP) and BigQuery you already know that BigQuery is a fully managed enterprise data warehouse that helps you manage and analyze your data with built-in features like machine learning, geospatial analysis, and business intelligence.
Thus, many developers will need to curate data, train models, and analyze the results of models. With that said, we are still in a highly empirical era for ML: we need bigdata, big models, and big compute. A typical data pipeline for machine learning. Source: O'Reilly.
Serverless APIs are the culmination of the cloud commoditizing the old hardware-based paradigm. This means making the hardware supply chain into a commodity if you make PCs, making PCs into commodities if you sell operating systems, and making servers a commodity by promoting serverless function execution if you sell cloud.
The 3rd generation data warehouses add more computing choices to MPP and offer different pricing models. By the level of back-end management involved: Serverlessdata warehouses get their functional building blocks with the help of serverless services, meaning they are fully-managed by third-party vendors. Architecture.
BigData Essentials – BigData Essentials is a comprehensive introduction to the world of BigData. Starting with the definition of BigData, we describe the various characteristics of BigData and its sources. No prior AWS experience is required.
Guillermo has developed a keen interest in serverless architectures and generative AI applications. Prior to his current role, he worked as a Software Engineer at AWS and other companies, focusing on sustainability technology, bigdata analytics, and cloud computing. Leo Mentis Raj Selvaraj is a Sr.
Serverless Concepts. Serverless has been gaining momentum as cloud technology continues to become more widespread. This course provides a high-level overview of the concept of Serverless computing without getting into deep technical details. BigData Essentials. AWS Essentials.
The Cloud-Native stack includes Serverless Computing , Containerization, and Orchestration Platforms. The Flexera 2020 State of the Cloud report named Serverless as one of the top five fastest-growing PaaS Cloud services. Another very significant Cloud-Native capability is Containerization.
Artificial Intelligence for BigData , April 15-16. Designing Serverless Architecture with AWS Lambda , April 15-16. Kubernetes Serverless with Knative , April 17. Serverless Architectures with Azure , April 23-24. Creating Serverless APIs with AWS Lambda and API Gateway , May 8.
Data science and data tools. Apache Hadoop, Spark, and BigData Foundations , January 15. Python Data Handling - A Deeper Dive , January 22. Practical Data Science with Python , January 22-23. Creating Serverless APIs with AWS Lambda and API Gateway , January 8.
Data science and data tools. Business Data Analytics Using Python , February 27. Designing and Implementing BigData Solutions with Azure , March 11-12. Cleaning Data at Scale , March 19. Practical Data Cleaning with Python , March 20-21. Kubernetes Serverless with Knative , March 15.
A couple of years ago, I wrote a post called “ 116 Hands-On Labs and Counting ” and today we have over 750 Hands-On Labs across 10 content categories — Linux, AWS, Azure, BigData, Cloud, Containers, DevOps, Google Cloud, OpenStack, and Security. Building a Serverless Application Using Step Functions, API Gateway, Lambda, and S3.
The conference covers approaches and technologies such as chaos engineering, serverless, and cloud, in addition to a range of leadership and business skills. Course titles include (among others) BigData for Managers, Hands-On Data Science with Python, and Building a ServerlessBigData Application on AWS.
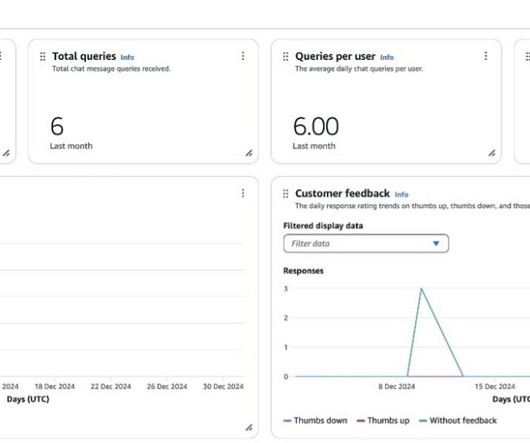
Scaling ground truth generation with a pipeline To automate ground truth generation, we provide a serverless batch pipeline architecture, shown in the following figure. The serverless batch pipeline architecture we presented offers a scalable solution for automating this process across large enterprise knowledge bases. 201% $12.2B
Knowledge Bases is completely serverless, so you don’t need to manage any infrastructure, and when using Knowledge Bases, you’re only charged for the models, vector databases and storage you use. RAG is a popular technique that combines the use of private data with large language models (LLMs). The OpenSearch Serverless collection.
Advanced technologies like BigData and Mobility have known to have fueled stronger growth in the cloud computing industry. Serverless computing is gaining popularity and will continue to achieve more prominence. The process of using data container will become simpler.
Artificial Intelligence for BigData , February 26-27. Data science and data tools. Apache Hadoop, Spark, and BigData Foundations , January 15. Python Data Handling - A Deeper Dive , January 22. Practical Data Science with Python , January 22-23. SQL Fundamentals for Data , February 19-20.
For example, for relational and NoSQL databases, data warehousing, BigData processing, and/or backup and recovery. Amazon Simple Storage Service (S3) – general purpose object store for user-generated content, active archive, serverless, etc. Use cases: Streaming workloads, bigdata, data warehouses, log processing.
Regardless of whether your data is coming from edge devices, on-premises datacenters, or cloud applications, you can integrate them with a self-managed Kafka cluster or with Confluent Cloud ([link] which provides serverless Kafka, mission-critical SLAs, consumption-based pricing, and zero efforts on your part to manage the cluster.
Understanding Data Science Algorithms in R: Scaling, Normalization and Clustering , August 14. Real-time Data Foundations: Spark , August 15. Visualization and Presentation of Data , August 15. Python Data Science Full Throttle with Paul Deitel: Introductory AI, BigData and Cloud Case Studies , September 24.
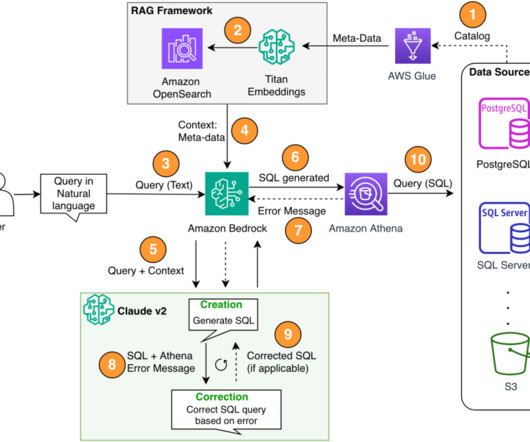
In this pattern, we use Retrieval Augmented Generation using vector embeddings stores, like Amazon Titan Embeddings or Cohere Embed , on Amazon Bedrock from a central data catalog, like AWS Glue Data Catalog , of databases within an organization. In entered the BigData space in 2013 and continues to explore that area.
Change is inevitable, and as programming languages continue to lean in to optimization for new trends in the cloud, microservices, bigdata, and machine learning, each language and its ecosystem will continue to adapt in its own unique way. ” What lies ahead? ” What lies ahead?
Bigdata is an older fashionable term that, when combined with agile methodology, AI and ML and analytics, has become a powerful trend once again in data operations (DataOps). If you’re a systems architect, it pays to understand the philosophies, benefits and tools to power DataOps and improve your data-driven applications.
Momentum grows in serverless computing. That seems to be the question people are asking about serverless computing and 2019 may well provide the answer one way or another. Serverless computing shifts the cost away from the developer and onto the cloud provider. Fad or future? 2019 and beyond.
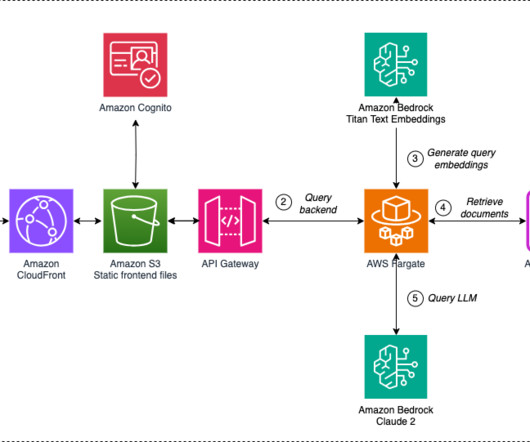
The backend is implemented by an LLM chain service running on AWS Fargate , a serverless, pay-as-you-go compute engine that lets you focus on building applications without managing servers. About the authors Vicente Cruz Mínguez is the Head of Data & Advanced Analytics at Cepsa Química.
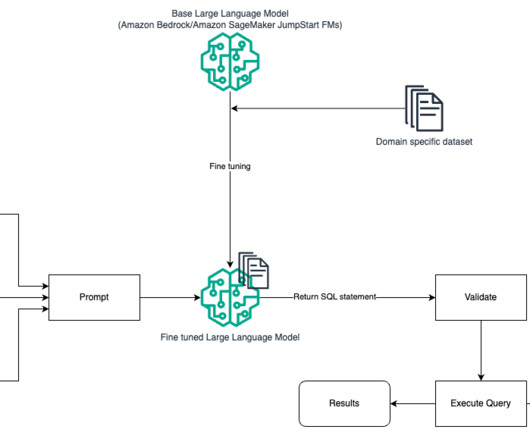
The process flow includes the following steps: Create the AWS Glue Data Catalog using an AWS Glue crawler (or a different method). Create the AWS Glue Data Catalog using an AWS Glue crawler (or a different method). medium instance with the Python 3 (Data Science) kernel. Steps 7–9 represent a correction loop, if applicable.
Designing Consistent Security for Microservices, APIs, and Serverless – Consistent security implementation should prevail. Microservices, APIs and Serverless require the most consistent security focus. Checking your Code Dependencies – Understanding that open-source use is the key to wider adoption of DevSecOps practices.
Who should take this course: We suggest you take our BigData Essentials and Linux Essentials courses before taking this course. You’ll even install some of the more popular database systems, including MongoDB and Couchbase, that are available on Linux and see how to work with data in those systems. Serverless Concepts.
Here are some of them: Function-as-a-Service (FaaS) or Serverless Computing: FaaS provides a platform that allows users to execute code in response to specific events without managing the complex infrastructure typically associated with building and launching microservices applications.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content