This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
It has become much more feasible to run high-performancedata platforms directly inside Kubernetes. First off, if your data is on a specialized storage appliance of some kind that lives in your data center, you have a boat anchor that is going to make it hard to move into the cloud. Recent advances in Kubernetes.
The deployment of bigdata tools is being held back by the lack of standards in a number of growth areas. Technologies for streaming, storing, and querying bigdata have matured to the point where the computer industry can usefully establish standards. Storage engine interfaces. Storage engine interfaces.
Data and bigdata analytics are the lifeblood of any successful business. Getting the technology right can be challenging but building the right team with the right skills to undertake data initiatives can be even harder — a challenge reflected in the rising demand for bigdata and analytics skills and certifications.
He said that everywhere he went, he used logging software and it almost invariably resulted in a big bill, something he set out to change when he launched Dassana. Logging involves a lot of data related to application performance, operations and security. If you try to cut costs around logging, it generally.
Azure Key Vault Secrets offers a centralized and secure storage alternative for API keys, passwords, certificates, and other sensitive statistics. Azure Key Vault is a cloud service that provides secure storage and access to confidential information such as passwords, API keys, and connection strings. What is Azure Key Vault Secret?
A comparison of the accuracy and performance of Spark-NLP vs. spaCy, and some use case recommendations. In the previous two parts, we walked through the code for training tokenization and part-of-speech models, running them on a benchmark data set, and evaluating the results. Performance. Runtime performance comparison.
Equally, if not more important, is the need for enhanced datastorage and management to handle new applications. These applications require faster parallel processing of data in diverse formats. In his keynote speech, he noted, “We believe that datastorage will undergo major changes as digital transformation gathers pace.
Currently, the demand for data scientists has increased 344% compared to 2013. hence, if you want to interpret and analyze bigdata using a fundamental understanding of machine learning and data structure. A cloud architect has a profound understanding of storage, servers, analytics, and many more.
Hadoop and Spark are the two most popular platforms for BigData processing. They both enable you to deal with huge collections of data no matter its format — from Excel tables to user feedback on websites to images and video files. Which BigData tasks does Spark solve most effectively? How does it work?
“DevOps engineers … face limitations such as discount program commitments and preset storage volume capacity, CPU and RAM, all of which cannot be continuously adjusted to suit changing demand,” Melamedov said in an email interview. He briefly worked together with Baikov at bigdata firm Feedvisor.
As more enterprises migrate to cloud-based architectures, they are also taking on more applications (because they can) and, as a result of that, more complex workloads and storage needs. Firebolt raises $127M more for its new approach to cheaper and more efficient BigData analytics.
Re-Thinking the Storage Infrastructure for Business Intelligence. With digital transformation under way at most enterprises, IT management is pondering how to optimize storage infrastructure to best support the new bigdata analytics focus. Adriana Andronescu. Wed, 03/10/2021 - 12:42.
As enterprises mature their bigdata capabilities, they are increasingly finding it more difficult to extract value from their data. This is primarily due to two reasons: Organizational immaturity with regard to change management based on the findings of data science. Align data initiatives with business goals.
BigData Analysis for Customer Behaviour. Bigdata is a discipline that deals with methods of analyzing, collecting information systematically, or otherwise dealing with collections of data that are too large or too complex for conventional device data processing applications. . Data Warehousing.
But the data repository options that have been around for a while tend to fall short in their ability to serve as the foundation for bigdata analytics powered by AI. Traditional data warehouses, for example, support datasets from multiple sources but require a consistent data structure. Meet the data lakehouse.
2] Foundational considerations include compute power, memory architecture as well as data processing, storage, and security. It’s About the Data For companies that have succeeded in an AI and analytics deployment, data availability is a key performance indicator, according to a Harvard Business Review report. [3]
Apache Ozone is a distributed, scalable, and high-performance object store , available with Cloudera Data Platform (CDP), that can scale to billions of objects of varying sizes. Structured data (such as name, date, ID, and so on) will be stored in regular SQL databases like Hive or Impala databases. Diversity of workloads.
Bigdata can be quite a confusing concept to grasp. What to consider bigdata and what is not so bigdata? Bigdata is still data, of course. Bigdata is tons of mixed, unstructured information that keeps piling up at high speed. Data engineering vs bigdata engineering.
BigData enjoys the hype around it and for a reason. But the understanding of the essence of BigData and ways to analyze it is still blurred. This post will draw a full picture of what BigData analytics is and how it works. BigData and its main characteristics. Key BigData characteristics.
Webb’s gimbaled antenna assembly, which includes the telescope’s high-data-rate dish antenna, must transmit about a Blu-ray’s worth of science data — that’s 28.6 The telescope’s storage ability is limited — 65 gigabytes — which requires regular sending back of data to keep from filling up the hard drive.
“Google Maps has elegantly shown us how maps can be personalized and localized, so we used that as a jumping off point for how we wanted to approach the bigdata problem.” If we’re going to integrate with your GitHub and we have to provide some background functions or storage, then those are paid services.”.
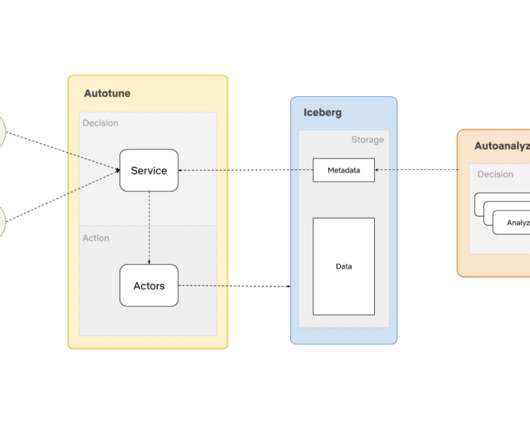
By Anupom Syam Background At Netflix, our current data warehouse contains hundreds of Petabytes of data stored in AWS S3 , and each day we ingest and create additional Petabytes. We built AutoOptimize to efficiently and transparently optimize the data and metadata storage layout while maximizing their cost and performance benefits.
And as data workloads continue to grow in size and use, they continue to become ever more complex. On top of that, today there are a wide range of applications and platforms that a typical organization will use to manage source material, storage, usage and so on. Doing so manually can be time-consuming, if not impossible.
If you are into technology and government and want to find ways to enhance your ability to serve big missions you need to be at this event, 25 Feb at the Hilton McLean Tysons Corner. Bigdata and its effect on the transformative power of data analytics are undeniable. Enabling Business Results with BigData.
From NGA''s Press Release: NGA, DigitalGlobe application a boon to raster datastorage, processing. MapReduce Geo, or MrGeo , is a geospatial toolkit designed to provide raster-based geospatial capabilities performable at scale by leveraging the power and functionality of cloud-based architecture. January 13, 2015.
He acknowledges that traditional bigdata warehousing works quite well for business intelligence and analytics use cases. But that’s not real-time and also involves moving a lot of data from where it’s generated to a centralized warehouse. That whole model is breaking down.” ” Image Credits: Edge Delta.
This could provide both cost savings and performance improvements. Deletion vectors are a storage optimization feature that replaces physical deletion with soft deletion. With a soft delete, deletion vectors are marked rather than physically removed, which is a performance boost.
The solution combines data from an Amazon Aurora MySQL-Compatible Edition database and data stored in an Amazon Simple Storage Service (Amazon S3) bucket. Solution overview Amazon Q Business is a fully managed, generative AI-powered assistant that helps enterprises unlock the value of their data and knowledge.
Data analytics is a discipline focused on extracting insights from data. It comprises the processes, tools and techniques of data analysis and management, including the collection, organization, and storage of data. Data analysts and others who work with analytics use a range of tools to aid them in their roles.
Consider also expanding the assistant’s capabilities through function calling, to perform actions on behalf of users, such as scheduling meetings or initiating workflows. Performance optimization The serverless architecture used in this post provides a scalable solution out of the box.
Today’s enterprise data analytics teams are constantly looking to get the best out of their platforms. Storage plays one of the most important roles in the data platforms strategy, it provides the basis for all compute engines and applications to be built on top of it. Separates control and data plane enabling high performance.
This was thanks to many concerns surrounding security, performance, compliance and costs. For instance, AWS offers on-premise integration in the form of services like AWS RDS , EC2, EBS with snapshots , object storage using S3 etc. Higher Level of Control Over BigData Analytics. A Technology Safe Harbor.
The shift to cloud has been accelerating, and with it, a push to modernize data pipelines that fuel key applications. That is why cloud native solutions which take advantage of the capabilities such as disaggregated storage & compute, elasticity, and containerization are more paramount than ever. 4xlarge nodes was used.
NoSQL NoSQL is a type of distributed database design that enables users to store and query data without relying on traditional structures often found in relational databases. Because of this, NoSQL databases allow for rapid scalability and are well-suited for large and unstructured data sets.
Working with bigdata is a challenge that every company needs to overcome to see long-term success in increasingly tough markets. Dealing with bigdata isn’t just one issue, though. It is dealing with a series of challenges relating to everything from how to acquire data to what to do with data and even data security.
A data lakehouse is a unified platform that combines the scalability and flexibility of a data lake with the structure and performance of a data warehouse. Unified DataStorage Combines the scalability and flexibility of a data lake with the structured capabilities of a data warehouse.
It’s necessary to figure out how to get sales data from its dedicated database talk with inventory records kept in a SQL server , for instance. This creates the necessity for integrating data in unified storage where data is collected, reformatted, and ready for use – data warehouse. Data warehouse storage.
Decision support and site selection The CRFs and associated data can be further analyzed by the LLM to identify patterns, trends, and potential risks across multiple sites. This information can be used to support decision-making processes, such as site selection for future clinical trials, based on historical performance and compliance data.
The modern data stack consists of hundreds of tools for app development, data capture and integration, orchestration, analysis and storage. The two say that they saw an opportunity to create a platform that takes all the different bigdata workload granularities across an organization and presents them in a single pane of glass.
If you’re studying for the AWS Cloud Practitioner exam, there are a few Amazon S3 (Simple Storage Service) facts that you should know and understand. Amazon S3 is an object storage service that is built to be scalable, high available, secure, and performant. What to know about S3 Storage Classes. 99.99% object durability.
With over 1,400 global customers, the company's products are widely used in scale-out server environments such as electronic trading, high performance computing, cloud, virtualization and bigdata.
By harnessing the unique operational awareness of InfiniVerse, IT teams have streamlined storage oversight and management to unprecedented levels of set-it-and-forget-it simplicity at their local site and across the globe. Neural Cache ensures optimal performance is a given, rather than repeatedly and crudely tuned by IT staff.
These seemingly unrelated terms unite within the sphere of bigdata, representing a processing engine that is both enduring and powerfully effective — Apache Spark. Maintained by the Apache Software Foundation, Apache Spark is an open-source, unified engine designed for large-scale data analytics. Bigdata processing.
The potential use cases for BI extend beyond the typical business performance metrics of improved sales and reduced costs. BI focuses on descriptive analytics, data collection, datastorage, knowledge management, and data analysis to evaluate past business data and better understand currently known information.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















































Let's personalize your content