This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
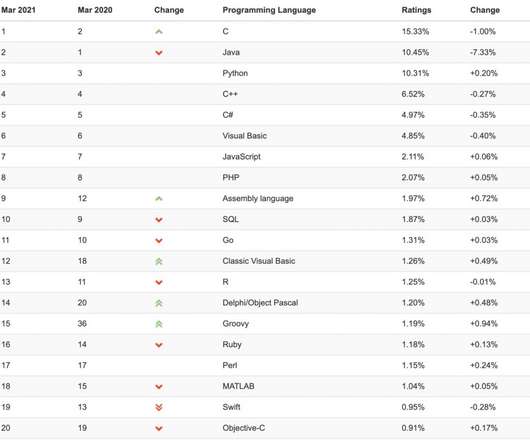
Java Java is a programming language used for core object-oriented programming (OOP) most often for developing scalable and platform-independent applications. Its a common skill for developers, software engineers, full-stack developers, DevOps engineers, cloud engineers, mobile app developers, backend developers, and bigdata engineers.
This is the third and final installment in this blog series comparing two leading opensource natural language processing software libraries: John Snow Labs’ NLP for Apache Spark and Explosion AI’s spaCy. Of course, this isn’t “bigdata” by any measure, but more realistic than a toy/debugging scenario. Scalability.
Average number of job openings (as per search on Indeed.com): 12,446 in US. It is a very versatile, platform independent and scalable language because of which it can be used across various platforms. It is frequently used in developing web applications, data science, machine learning, quality assurance, cyber security and devops.
If you are ready to enhance your skills with distributed platforms, scalable workflow tools and bigdata science please check out the info below from the Workflows for Data Science (WorDS) Center of Excellence , SDSC and National Biomedical Computation Resource (NBCR) : Scalable Bioinformatics Boot Camp.
By Bob Gourley Note: we have been tracking Cloudant in our special reporting on Analytical Tools , BigData Capabilities , and Cloud Computing. Cloudant will extend IBM’s BigData and Analytics , Cloud Computing and Mobile offerings by further helping clients take advantage of these key growth initiatives.
Portland, Oregon-based startup thatDot , which focuses on streaming event processing, today announced the launch of Quine , a new MIT-licensed opensource project for data engineers that combines event streaming with graph data to create what the company calls a “streaming graph.”
The 10/10-rated Log4Shell flaw in Log4j, an opensource logging software that’s found practically everywhere, from online games to enterprise software and cloud data centers, claimed numerous victims from Adobe and Cloudflare to Twitter and Minecraft due to its ubiquitous presence.
In this article, we will explain the concept and usage of BigData in the healthcare industry and talk about its sources, applications, and implementation challenges. What is BigData and its sources in healthcare? So, what is BigData, and what actually makes it Big?
Organizations are looking for AI platforms that drive efficiency, scalability, and best practices, trends that were very clear at BigData & AI Toronto. DataRobot Booth at BigData & AI Toronto 2022. Today, his team is using open-source packages without a standardized AI platform.
Today’s cloud building blocks empower any size team—even a lone engineer—to build bigdata solutions. Learn how to use open-source tools to create scalable architecture for your next project.
Hadoop and Spark are the two most popular platforms for BigData processing. They both enable you to deal with huge collections of data no matter its format — from Excel tables to user feedback on websites to images and video files. Which BigData tasks does Spark solve most effectively? scalability.
Handling this colossal data is tough; hence it requires NoSQL. These databases are more agile and provide scalable features; also, they are a better choice to handle the vast data of the customers and find crucial insights. Apache HBase Apache HBase is an open-source database, and it is a kind of Hadoop database.
Hortonworks'' Hadoop Data Platform (HDP) is now a supported feature on Google Cloud. This new feature will allow dynamic provisioning of HDP clusters on the Google Cloud Platform, providing scalability for enterprise-wide solutions employing HDP, as well as providing a means for rapidly setting up prototyping and development environments.
Free and open-source database tools are typically more appealing to the everyday small business and app creator, so we’ve outlined some of the best ones, according to user reviews on G2 Crowd. Oracle released the first fully functional one in 1979, but today there are hundreds of proprietary and open-source options available.
BigData enjoys the hype around it and for a reason. But the understanding of the essence of BigData and ways to analyze it is still blurred. This post will draw a full picture of what BigData analytics is and how it works. BigData and its main characteristics. Key BigData characteristics.
has announced the launch of the Cray® Urika®-GX system -- the first agile analytics platform that fuses supercomputing technologies with an open, enterprise-ready software framework for bigdata analytics. The Cray Urika-GX system is designed to eliminate challenges of bigdata analytics.
In the realm of distributed databases, Apache Cassandra has established itself as a robust, scalable, and highly available solution. Understanding Apache Cassandra Apache Cassandra is a free and open-source distributed database management system designed to handle large amounts of data across multiple commodity servers.
You know Spark, the free and opensource complement to Apache Hadoop that gives enterprises better ability to field fast, unified applications that combine multiple workloads, including streaming over all your data. They also launched a plan to train over a million data scientists and data engineers on Spark.
By Michael Johnson For enterprise technology decision-makers, functionality, interoperability, scalability security and agility are key factors in evaluating technologies. Pentaho has long been known for functionality, scalability, interoperability and agility. ” “Bigdata technologies are advancing at speeds like never before.
Aurora MySQL-Compatible is a fully managed, MySQL-compatible, relational database engine that combines the speed and reliability of high-end commercial databases with the simplicity and cost-effectiveness of open-source databases. She has experience across analytics, bigdata, ETL, cloud operations, and cloud infrastructure management.
Handling this colossal data is tough; hence it requires NoSQL. These databases are more agile and provide scalable features; also, they are a better choice to handle the vast data of the customers and find crucial insights. Apache HBase is an open-source database, and it is a kind of Hadoop database. Apache HBase.
BigData Analysis for Customer Behaviour. Bigdata is a discipline that deals with methods of analyzing, collecting information systematically, or otherwise dealing with collections of data that are too large or too complex for conventional device data processing applications. Silent Sound Technology.
Kubernetes has emerged as go to container orchestration platform for data engineering teams. In 2018, a widespread adaptation of Kubernetes for bigdata processing is anitcipated. Organisations are already using Kubernetes for a variety of workloads [1] [2] and data workloads are up next. Key challenges. Performance.
This can be attributed to the fact that Java is widely used in industries such as financial services, BigData, stock market, banking, retail, and Android. Pandas is a widely used tool, particularly in data munging and wrangling. It is available for everyone as an open-source, free-to-use project.
Many players delivered niche solutions for encrypting data, but not so long ago most solutions I saw introduced new weaknesses for each solution. Cloudera is continuing to invest broadly in the opensource community to support and accelerate security features into project Rhino—an opensource effort founded by Intel in early 2013.
February 1998 became one of the notable months in the software development community: The OpenSource Initiative (OSI) corporation was founded and the opensource label was introduced. The term represents a software development approach based on collaborative improvement and source code sharing. Well, it doesn’t.
All this raw information, patterns and details is collectively called BigData. BigData analytics,on the other hand, refers to using this huge amount of data to make informed business decisions. Let us have a look at BigData Analytics more in detail. What is BigData Analytics?
The enterprise data hub is the emerging and necessary center of enterprise data management, complementing existing infrastructure. The joint development work focuses on Apache Accumulo, the scalable, high performance distributed key/value store that is part of the Apache Software Foundation. About Cloudera. www.cloudera.com.
With the continuous development of advanced infrastructure based around Apache Hadoop there has been an incredible amount of innovation around enterprise “BigData” technologies, including in the analytical tool space. H2O by 0xdata brings better algorithms to bigdata. Mike really nailed it with that one.
Depending on how you measure it, the answer will be 11 million newspaper pages or… just one Hadoop cluster and one tech specialist who can move 4 terabytes of textual data to a new location in 24 hours. Developed in 2006 by Doug Cutting and Mike Cafarella to run the web crawler Apache Nutch, it has become a standard for BigData analytics.
Too often, though, legacy systems cannot deliver the needed speed and scalability to make these analytic defenses usable across disparate sources and systems. For many agencies, 80 percent of the work in support of anomaly detection and fraud prevention goes into routine tasks around data management.
Bigdata and data science are important parts of a business opportunity. How companies handle bigdata and data science is changing so they are beginning to rely on the services of specialized companies. User data collection is data about a user who is collected for market research purposes.
Today, I’m very excited to announce the next chapter in our company’s journey: Microsoft has acquired Citus Data. When we founded Citus Data eight years ago, the world was different. Clouds and bigdata were newfangled. This brought the rise of Hadoop and all the other NoSQL databases people were creating at the time.
Bigdata exploded onto the scene in the mid-2000s and has continued to grow ever since. Today, the data is even bigger, and managing these massive volumes of data presents a new challenge for many organizations. Even if you live and breathe tech every day, it’s difficult to conceptualize how big “big” really is.
However, as enterprises and service providers put their 2018 tech budgets into action, we’re here to point out one DIY networking trend where the fine print is worth reading: Opensource network flow analyzers. It’s much more doable now than ever with opensource building blocks readily available. Open API access.
There were thousands of attendees at the event – lining up for book signings and meetings with recruiters to fill the endless job openings for developers experienced with MapReduce and managing BigData. This was the gold rush of the 21st century, except the gold was data.
By Jeff Carpenter You might have heard of Apache Cassandra, the open-source NoSQL database. And you might know that some big, very successful companies rely on it, including LinkedIn, Netflix, The Home Depot, and Apple. Split the data among multiple machines and create a distributed system. Why Cassandra?
These seemingly unrelated terms unite within the sphere of bigdata, representing a processing engine that is both enduring and powerfully effective — Apache Spark. Maintained by the Apache Software Foundation, Apache Spark is an open-source, unified engine designed for large-scale data analytics.
With the rise of bigdata, organizations are collecting and storing more data than ever before. This data can provide valuable insights into customer needs and assist in creating innovative products. Unfortunately, this also makes data valuable to hackers, seeking to infiltrate systems and exfiltrate information.
In order to perform BigData operations, you need the right type of database. Hadoop is an opensource database for dealing with bigdata that CIOs are getting excited over. CEOs and those in the CIO position have become convinced that the future of IT involves BigData.
Storage plays one of the most important roles in the data platforms strategy, it provides the basis for all compute engines and applications to be built on top of it. Businesses are also looking to move to a scale-out storage model that provides dense storages along with reliability, scalability, and performance.
Since they consume a significant amount of time spent on most data science projects, we highlight these two main classes of data quality problems in this post: Data unification and integration. Data unification and integration. business and quality rules, policies, statistical signals in the data, etc.).
This can be attributed to the fact that Java is widely used in industries such as financial services, BigData, stock market, banking, retail, and Android. Pandas is a widely used tool, particularly in data munging and wrangling. It is available for everyone as an open-source, free-to-use project.
Data architect can also design collective storage for your data warehouse – multiple databases running in parallel. This will improve the warehouse’s scalability. Adding business context to data, metadata helps transform it into comprehensible knowledge. Metadata defines how data can be changed and processed.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content