This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
“DevOps engineers … face limitations such as discount program commitments and preset storage volume capacity, CPU and RAM, all of which cannot be continuously adjusted to suit changing demand,” Melamedov said in an email interview. He briefly worked together with Baikov at bigdata firm Feedvisor.
Cohesive, structured data is the fodder for sophisticated mathematical models that generates insights and recommendations for organizations to take decisions across the board, from operations to market trends. But with bigdata comes big responsibility, and in a digital-centric world, data is coveted by many players.
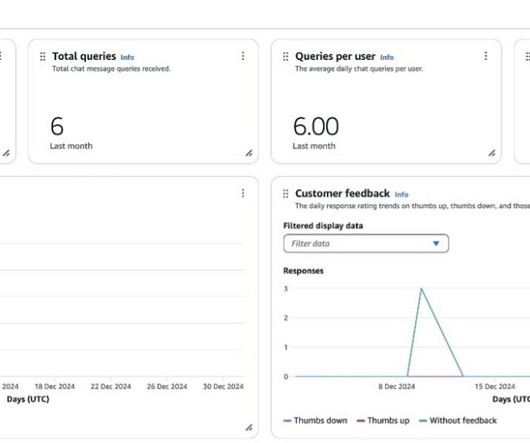
By monitoring utilization metrics, organizations can quantify the actual productivity gains achieved with Amazon Q Business. Tracking metrics such as time saved and number of queries resolved can provide tangible evidence of the services impact on overall workplace productivity.
Bigdata has almost always been primarily used to target clients using tailored products, targeted advertising. This has skewed the use of bigdata that often everyone simply assumes bigdata is for targeting the customer base. In turn, you’ll be able to address, production, packaging and storage issues.
BigData enjoys the hype around it and for a reason. But the understanding of the essence of BigData and ways to analyze it is still blurred. This post will draw a full picture of what BigData analytics is and how it works. BigData and its main characteristics. Key BigData characteristics.
He acknowledges that traditional bigdata warehousing works quite well for business intelligence and analytics use cases. But that’s not real-time and also involves moving a lot of data from where it’s generated to a centralized warehouse. That whole model is breaking down.” ” Image Credits: Edge Delta.
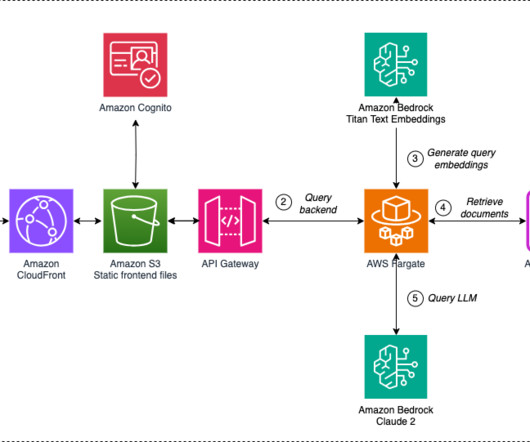
In this post, we demonstrate a few metrics for online LLM monitoring and their respective architecture for scale using AWS services such as Amazon CloudWatch and AWS Lambda. Overview of solution The first thing to consider is that different metrics require different computation considerations. The function invokes the modules.
Announcing a unique solution that works for HPC, BigData Analytics, or a hybrid environment. The enhancements reduce the ongoing administrative burden through proactive diagnostics based on Lustre-specific metrics and tests. The configuration and setup are easy.
It’s necessary to figure out how to get sales data from its dedicated database talk with inventory records kept in a SQL server , for instance. This creates the necessity for integrating data in unified storage where data is collected, reformatted, and ready for use – data warehouse. Data warehouse storage.
The potential use cases for BI extend beyond the typical business performance metrics of improved sales and reduced costs. BI focuses on descriptive analytics, data collection, datastorage, knowledge management, and data analysis to evaluate past business data and better understand currently known information.
That is why Bright added job-based metrics to their Bright Cluster Manager solutions. Users can now select a job that is currently running (or has recently run) and get metrics for both nodes and jobs. These screenshots illustrate the effectiveness in visualizing monitoring data on a device basis rather than a job basis: .
Digital companies have taken the lead in this next phase of data-driven decision-making, but it’s now extending across more kinds of organizations and more areas within organizations. Smart CTOs recognize the wealth of data trapped in silos across their business. More data will lead to better results for all stakeholders.
All this raw information, patterns and details is collectively called BigData. BigData analytics,on the other hand, refers to using this huge amount of data to make informed business decisions. Let us have a look at BigData Analytics more in detail. What is BigData Analytics?
Bigdata exploded onto the scene in the mid-2000s and has continued to grow ever since. Today, the data is even bigger, and managing these massive volumes of data presents a new challenge for many organizations. Even if you live and breathe tech every day, it’s difficult to conceptualize how big “big” really is.
These seemingly unrelated terms unite within the sphere of bigdata, representing a processing engine that is both enduring and powerfully effective — Apache Spark. Maintained by the Apache Software Foundation, Apache Spark is an open-source, unified engine designed for large-scale data analytics. Bigdata processing.
BigData collection at scale is increasing across industries, presenting opportunities for companies to develop AI models and leverage insights from that data. DataStorage: Computer scientists and programmers assert that blockchain offers certain advantages for datastorage compared to alternatives.
Please submit your topics in accordance with the below (From: [link] ): Data Science Symposium 2014. It is set apart from related symposia by our emphasis on advancing data science technologies through: Benchmarking of complex data-intensive analytic systems and subcomponents. Major forms of analytics employed in data science.
With deterministic evaluation processes such as the Factual Knowledge and QA Accuracy metrics of FMEval , ground truth generation and evaluation metric implementation are tightly coupled. He collaborates closely with enterprise customers building modern data platforms, generative AI applications, and MLOps.
Cloud optimization helps: To maximize the efficiency of your servers, storage, and databases. Compress Data Before Storage – Compressing data reduces your storage requirements. Subsequently, reducing the cost of storage. To drive down costs across resources. In increasing uptime with high availability.
Informatica’s comprehensive suite of Data Engineering solutions is designed to run natively on Cloudera Data Platform — taking full advantage of the scalable computing platform. The presentation of data from Cloudera within proprietary database systems is also supported. Certified Kubernetes Shared Storage Partner.
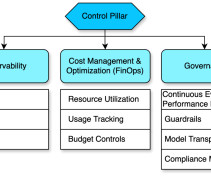
Provide control through transparency of models, guardrails, and costs using metrics, logs, and traces The control pillar of the generative AI framework focuses on observability, cost management, and governance, making sure enterprises can deploy and operate their generative AI solutions securely and efficiently.
Whether you are aggregating log files, system resource utilization metrics, or application data, Splunk is there to centralize your IT data for easy search and visualization. Students will learn by doing through installing and configuring containers, and thoughtfully selecting a persistent storage strategy.
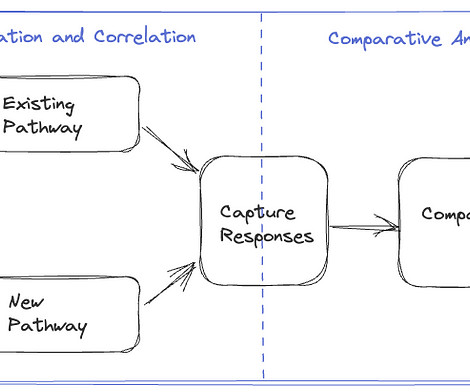
The second phase involves migrating the traffic over to the new systems in a manner that mitigates the risk of incidents while continually monitoring and confirming that we are meeting crucial metrics tracked at multiple levels. The batch job creates a high-level summary that captures some key comparison metrics.
Applicant Tracking Systems (ATS) Todays ATS systems allow for the effective storage, organization, and tracking of all candidate information. AI-Powered Analytics One benefit of employing these AI tools is that they can sift through bigdata to determine which candidates will likely perform well.
KDE handles over 10B flow records/day with a microservice architecture that's optimized using metrics. Here at Kentik, our Kentik Detect service is powered by a multi-tenant bigdata datastore called Kentik Data Engine. And that leads us to metrics. Workers are processes that run on our storage nodes.
The data sources may be PDF documents on a file system, data from a software as a service (SaaS) system like a CRM tool, or data from an existing wiki or knowledge base. He entered the bigdata space in 2013 and continues to explore that area. He also holds an MBA from Colorado State University.
Second, since IaaS deployments replicated the on-premises HDFS storage model, they resulted in the same data replication overhead in the cloud (typical 3x), something that could have mostly been avoided by leveraging modern object store. Storage costs. using list pricing of $0.72/hour hour using a r5d.4xlarge
The cloud-native consumption model delivers lower cloud infrastructure TCO versus both on-premises and IaaS deployments of Apache HBase by employing a) elastic compute resources b) cloud-native design patterns for high-availability and c) cost efficient object storage as the primary storage layer. Elastic Compute.
It serves as a foundation for the entire data management strategy and consists of multiple components including data pipelines; , on-premises and cloud storage facilities – data lakes , data warehouses , data hubs ;, data streaming and BigData analytics solutions ( Hadoop , Spark , Kafka , etc.);
Diagnostic analytics identifies patterns and dependencies in available data, explaining why something happened. Predictive analytics creates probable forecasts of what will happen in the future, using machine learning techniques to operate bigdata volumes. Real-life applications: Finding dependencies and reasoning behind data.
For Data flow name , enter a name (for example, AssessingMentalHealthFlow ). SageMaker Data Wrangler will open. You can import data from multiple sources, ranging from AWS services, such as Amazon Simple Storage Service (Amazon S3) and Amazon Redshift, to third-party or partner services, including Snowflake or Databricks.
For example, one provider may specialize in datastorage and security, while another may excel in bigdata analytics. This approach enables businesses to select the most suitable services and multi-cloud solutions from providers, such as storage, networking, or data analytics.
When a mix of batch, interactive, and data serving workloads are added to the mix, the problem becomes nearly intractable. In a traditional cluster, Cloudera Manager co-locates compute and storage on the same physical infrastructure. Networking Implications. Cloudera Manager 6.2 Conclusion and future work.
Business intelligence (BI) comprises the strategies and technologies used by enterprises for the data analysis of business information. It has become a necessary tool in the era of bigdata. It is a suite of software and services to transform data into actionable intelligence and knowledge. Metric Insights.
It offers high throughput, low latency, and scalability that meets the requirements of BigData. The technology was written in Java and Scala in LinkedIn to solve the internal problem of managing continuous data flows. process data in real time and run streaming analytics. Kafka topic and partition.
This article delves into the realm of unstructured data, highlighting its importance, and providing practical guidance on extracting valuable insights from this often-overlooked resource. We will discuss the different data types, storage and management options, and various techniques and tools for unstructured data analysis.
From human genome mapping to BigData Analytics, Artificial Intelligence (AI),Machine Learning, Blockchain, Mobile digital Platforms (Digital Streets, towns and villages),Social Networks and Business, Virtual reality and so much more. The 21st century has seen the advent of some ingenious inventions and technology.
With the rise of bigdata, organizations are collecting and storing more data than ever before. This data can provide valuable insights into customer needs and assist in creating innovative products. Unfortunately, this also makes data valuable to hackers, seeking to infiltrate systems and exfiltrate information.
Mark Huselid and Dana Minbaeva in BigData and HRM call these measures the understanding of the workforce quality. People analytics is the analysis of employee-related data using tools and metrics. Dashboard with key metrics on recruiting, workforce composition, diversity, wellbeing, business impact, and learning.
The AWS Glue job calls Amazon Textract , an ML service that automatically extracts text, handwriting, layout elements, and data from scanned documents, to process the input PDF documents. About the authors Vicente Cruz Mínguez is the Head of Data & Advanced Analytics at Cepsa Química.
The data can be used with various purposes: to do analytics or create machine learning models. Any system dealing with data processing requires moving information between storages and transforming it in the process to be then used by people or machines. If the amount of data is small, any kind of database can be used.
Although less complex than the “4 Vs” of bigdata (velocity, veracity, volume, and variety), orienting to the variety and volume of a challenging puzzle is similar to what CIOs face with information management. Operationalizing data to drive revenue CIOs report that their roles are rising in importance and impact.
Object storage costs (almost identical unit costs across CSPs in all regions) and . The workload breakdown measured in estimated vCPU-hours (based on on-premises capacity and utilization metrics) by region and data lifecycle stage is summarized in the Shankey chart below: . Considerations in multi-cloud implementations.
Through instrumentation, integrations, automated analysis, visualizations, and a full suite of data management features, data platforms offer data managers and engineers a unique opportunity to interact with distributed data at a scale that would otherwise exist in siloed data infrastructures.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content