This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Today, just 15% of enterprises are using machinelearning, but double that number already have it on their roadmaps for the upcoming year. However, in talking with CEOs looking to implement machinelearning in their organizations, there seems to be a common problem in moving machinelearning from science to production.
Bigdata is often called one of the most important skill sets in the 21st century, and it’s experiencing enormous demand in the job market. Hiring data scientists and other bigdata professionals is a major challenge for large enterprises, leading many to shift their efforts to training existing staff. Statistics.
Data and bigdata analytics are the lifeblood of any successful business. Getting the technology right can be challenging but building the right team with the right skills to undertake data initiatives can be even harder — a challenge reflected in the rising demand for bigdata and analytics skills and certifications.
The deployment of bigdata tools is being held back by the lack of standards in a number of growth areas. Technologies for streaming, storing, and querying bigdata have matured to the point where the computer industry can usefully establish standards. The main standard with some applicability to bigdata is ANSI SQL.
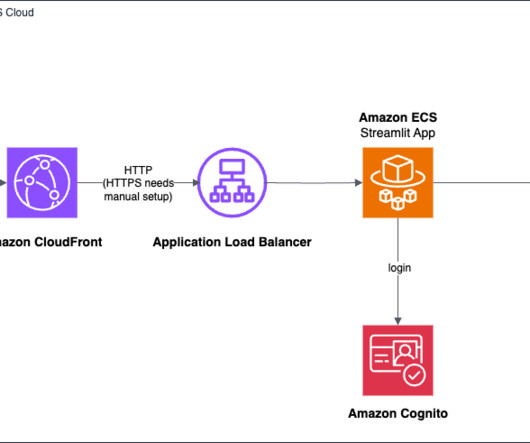
Traditionally, building frontend and backend applications has required knowledge of web development frameworks and infrastructure management, which can be daunting for those with expertise primarily in data science and machinelearning. Fortunately, you can run and test your application locally before deploying it to AWS.
In the rush to build, test and deploy AI systems, businesses often lack the resources and time to fully validate their systems and ensure they’re bug-free. In a 2018 report , Gartner predicted that 85% of AI projects will deliver erroneous outcomes due to bias in data, algorithms or the teams responsible for managing them.
In the previous blog post in this series, we walked through the steps for leveraging Deep Learning in your Cloudera MachineLearning (CML) projects. As a machinelearning problem, it is a classification task with tabular data, a perfect fit for RAPIDS. Ingest Data. Write Data. Introduction.
When speaking of machinelearning, we typically discuss data preparation or model building. Living in the shadow, this stage, according to the recent study , eats up 25 percent of data scientists time. MLOps lies at the confluence of ML, data engineering, and DevOps. More time for development of new models.
As tempting as it may be to think of a future where there is a machinelearning model for every business process, we do not need to tread that far right now. Data can enhance the operations of virtually any component within the organizational structure of any business. Importantly, point B does not have to be a data scientist.
At the heart of this shift are AI (Artificial Intelligence), ML (MachineLearning), IoT, and other cloud-based technologies. Modern technical advancements in healthcare have made it possible to quickly handle critical medical data, medical records, pharmaceutical orders, and other data. Twins in the Cloud.
Currently, the demand for data scientists has increased 344% compared to 2013. hence, if you want to interpret and analyze bigdata using a fundamental understanding of machinelearning and data structure. Because the salary for a data scientist can be over Rs5,50,000 to Rs17,50,000 per annum.
Building a scalable, reliable and performant machinelearning (ML) infrastructure is not easy. It takes much more effort than just building an analytic model with Python and your favorite machinelearning framework. Impedance mismatch between data scientists, data engineers and production engineers.
This opens a web-based development environment where you can create and manage your Synapse resources, including data integration pipelines, SQL queries, Spark jobs, and more. Link External Data Sources: Connect your workspace to external data sources like Azure Blob Storage, Azure SQL Database, and more to enhance data integration.
Companies successfully adopt machinelearning either by building on existing data products and services, or by modernizing existing models and algorithms. In this post, I share slides and notes from a keynote I gave at the Strata Data Conference in London earlier this year. Use ML to unlock new data types—e.g.,
Whether you’re looking to earn a certification from an accredited university, gain experience as a new grad, hone vendor-specific skills, or demonstrate your knowledge of data analytics, the following certifications (presented in alphabetical order) will work for you. Check out our list of top bigdata and data analytics certifications.)
In a world fueled by disruptive technologies, no wonder businesses heavily rely on machinelearning. Google, in turn, uses the Google Neural Machine Translation (GNMT) system, powered by ML, reducing error rates by up to 60 percent. The role of a machinelearning engineer in the data science team.
Standard development best practices and effective cloud operating models, like AWS Well-Architected and the AWS Cloud Adoption Framework for Artificial Intelligence, MachineLearning, and Generative AI , are key to enabling teams to spend most of their time on tasks with high business value, rather than on recurrent, manual operations.
To successfully integrate AI and machinelearning technologies, companies need to take a more holistic approach toward training their workforce. Implementing and incorporating AI and machinelearning technologies will require retraining across an organization, not just technical teams.
Bigdata refers to the set of techniques used to store and/or process large amounts of data. . Usually, bigdata applications are one of two types: data at rest and data in motion. For this article, we’ll focus mainly on data at rest applications and on the Hadoop ecosystem specifically.
It is the base of Android programming, used to develop mobile applications, and also preferred for automated testing owing to its platform independence property. It is frequently used in developing web applications, data science, machinelearning, quality assurance, cyber security and devops.
To evaluate the transcription accuracy quality, the team compared the results against ground truth subtitles on a large test set, using the following metrics: Word error rate (WER) – This metric measures the percentage of words that are incorrectly transcribed compared to the ground truth. A lower WER indicates a more accurate transcription.
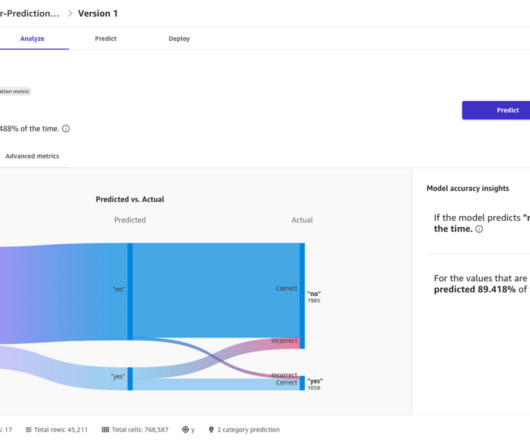
Amazon DataZone makes it straightforward for engineers, data scientists, product managers, analysts, and business users to access data throughout an organization so they can discover, use, and collaborate to derive data-driven insights. You can review the model status and test the model on the Predict tab.
With COVID-19 outbreaks happening globally, each time a test for COVID-19 is processed in a lab, live genetic samples of the virus get collected. Taken together, these millions of tests represent a goldmine of information about the coronavirus and how it is mutating, and when and where it is doing so. .”
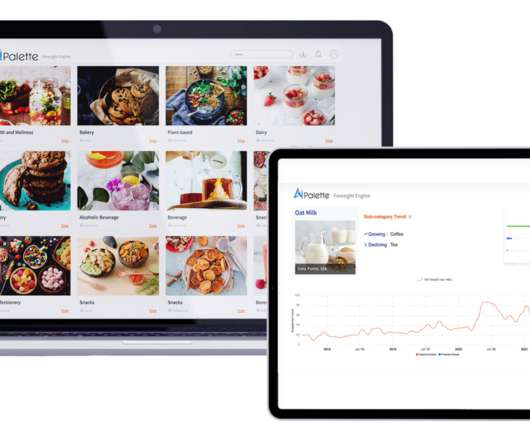
Developing new packaged foods and consumer goods can take a couple years as companies research, prototype and test products. Founded in 2018, Ai Palette uses machinelearning to help companies spot trends in real time and get them retail-ready, often within a few months. 5 predictions for the future of e-commerce.
He then covered the new focus on cloud security with an emphasis on access log transparency, data loss prevention, and VPC service controls such as Policy Intelligence, a machinelearning-based service that targets access that may be too broad. Cloud Data Fusion. Bigdata got some big news today as well.
Going from a prototype to production is perilous when it comes to machinelearning: most initiatives fail , and for the few models that are ever deployed, it takes many months to do so. As little as 5% of the code of production machinelearning systems is the model itself. Adapted from Sculley et al.
Data science is an interdisciplinary field that uses a blend of data inference and algorithm development to solve complex analytical problems. An ideal candidate has skills in the 3 fields: mathematics/ statistics/ machinelearning/ programming and business/ domain knowledge. . MachineLearning and Programming.
Machinelearning (ML) history can be traced back to the 1950s, when the first neural networks and ML algorithms appeared. Analysis of more than 16.000 papers on data science by MIT technologies shows the exponential growth of machinelearning during the last 20 years pumped by bigdata and deep learning advancements.
You’ve found an awesome data set that you think will allow you to train a machinelearning (ML) model that will accomplish the project goals; the only problem is the data is too big to fit in the compute environment that you’re using. <end code block> Launching workers in Cloudera MachineLearning.
For media outlets, Dable offers two bigdata and machinelearning-based products: Dable News to make personalized recommendations of content, including articles, to visitors, and Dable Native Ad, which draws on ad networks including Google, MSN and Kakao.
Predictive analytics applies techniques such as statistical modeling, forecasting, and machinelearning to the output of descriptive and diagnostic analytics to make predictions about future outcomes. In business, predictive analytics uses machinelearning, business rules, and algorithms.
Although researchers can recruit “citizen scientists” to help look at images through crowdsourcing ventures such as Zooniverse , astronomy is turning to artificial intelligence (AI) to find the right data as quickly as possible. This e-learning allows lots of folks to assist with the AI. GI, AI, and ML for all.
Fujitsu, in collaboration with NVIDIA and NetApp launched AI Test Drive to help address this specific problem and assist data scientists in validating business cases for investment. AI Test Drive functions as an effective AI-as-a-Service solution, and it is already demonstrating strong results. Artificial Intelligence
It was not alive because the business knowledge required to turn data into value was confined to individuals minds, Excel sheets or lost in analog signals. We are now deciphering rules from patterns in data, embedding business knowledge into ML models, and soon, AI agents will leverage this data to make decisions on behalf of companies.
Bigdata refers to the set of techniques used to store and/or process large amounts of data. . Usually, bigdata applications are one of two types: data at rest and data in motion. For this article, we’ll focus mainly on data at rest applications and on the Hadoop ecosystem specifically.
Providing recommendations for follow-up assessments, diagnostic tests, or specialist consultations. During these visits, various assessments were conducted, including blood tests, physical exams, ECGs, and evaluation of patient-reported outcomes like pain levels (Transcripts 1 and 3). Choose Test. Run the test event.
Hadoop and Spark are the two most popular platforms for BigData processing. They both enable you to deal with huge collections of data no matter its format — from Excel tables to user feedback on websites to images and video files. Which BigData tasks does Spark solve most effectively? How does it work?
According to the survey, 28% of respondents said they have hired data scientists to support generative AI, while 30% said they have plans to hire candidates. This role is responsible for training, developing, deploying, scheduling, monitoring, and improving scalable machinelearning solutions in the enterprise.
Dataiku — which sells tools to help customers build, test and deploy AI and analytics applications — has managed to avoid major layoffs, unlike competitors such as DataRobot. ” Dataiku, which launched in Paris in 2013, competes with a number of companies for dominance in the AI and bigdata analytics space.
To help companies unlock the full potential of personalized marketing, propensity models should use the power of machinelearning technologies. Alphonso – the US-based TV data company – proves this statement. You will also learn how propensity models are built and where is the best place to start.
When it’s complete, you can go to Google Chat and test your new business logic. You could also use Amazon Bedrock Prompt Flows to accelerate the creation, testing, and deployment of workflows through an intuitive visual builder. The following screenshot shows an example chat.
Recent advances in AI have been helped by three factors: Access to bigdata generated from e-commerce, businesses, governments, science, wearables, and social media. Improvement in machinelearning (ML) algorithms—due to the availability of large amounts of data. Applications of AI. Conclusion.
The adoption of systems based on Artificial Intelligence (AI) and MachineLearning (ML) has seen an exponential rise in the past few years and is expected to continue to do so. With the sporadic growth in these applications, the QA practices and testing strategies for AI/ML applications models also need to keep pace.
Set up an Aurora MySQL database Complete the following steps to create an Aurora MySQL database to host the structured sales data: On the Amazon RDS console, choose Databases in the navigation pane. For Templates , choose Production or Dev/test. The following screenshot shows the database table schema and the sample data in the table.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content