This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
When speaking of machinelearning, we typically discuss data preparation or model building. Living in the shadow, this stage, according to the recent study , eats up 25 percent of data scientists time. MLOps lies at the confluence of ML, data engineering, and DevOps. More time for development of new models.
This opens a web-based development environment where you can create and manage your Synapse resources, including data integration pipelines, SQL queries, Spark jobs, and more. Link External Data Sources: Connect your workspace to external data sources like Azure Blob Storage, Azure SQL Database, and more to enhance data integration.
At the heart of this shift are AI (Artificial Intelligence), ML (MachineLearning), IoT, and other cloud-based technologies. Modern technical advancements in healthcare have made it possible to quickly handle critical medical data, medical records, pharmaceutical orders, and other data. It’s all about bigdata. .
Bigdatarefers to the set of techniques used to store and/or process large amounts of data. . Usually, bigdata applications are one of two types: data at rest and data in motion. For this article, we’ll focus mainly on data at rest applications and on the Hadoop ecosystem specifically.
Amazon DataZone makes it straightforward for engineers, data scientists, product managers, analysts, and business users to access data throughout an organization so they can discover, use, and collaborate to derive data-driven insights. For instructions to catalog the data, refer to Populating the AWS Glue Data Catalog.
Machinelearning and other artificial intelligence applications add even more complexity. This is an issue that extends to different aspects of enterprise IT: for example, Firebolt is building architecture and algorithms to reduce the bandwidth needed specifically for handling bigdata analytics.
From human genome mapping to BigData Analytics, Artificial Intelligence (AI),MachineLearning, Blockchain, Mobile digital Platforms (Digital Streets, towns and villages),Social Networks and Business, Virtual reality and so much more. What is MachineLearning? MachineLearning delivers on this need.
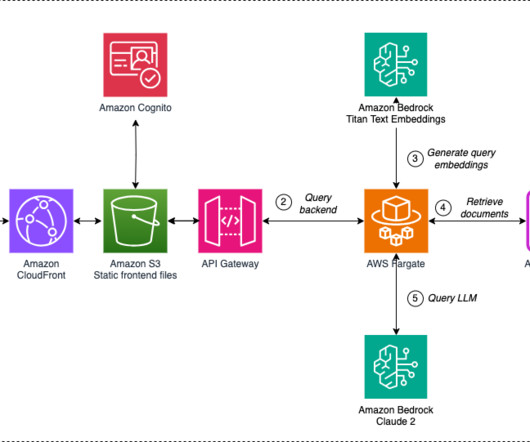
If you don’t have an AWS account, refer to How do I create and activate a new Amazon Web Services account? If you don’t have an existing knowledge base, refer to Create an Amazon Bedrock knowledge base. Additionally, Amazon API Gateway incurs charges based on the number of API calls and data transfer.
To evaluate the metadata quality, the team used reference-free LLM metrics, inspired by LangSmith. Tom Lauwers is a machinelearning engineer on the video personalization team for DPG Media. This flexibility allows them to tailor the metadata generation to evolving business requirements.
You may check out additional reference notebooks on aws-samples for how to use Meta’s Llama models hosted on Amazon Bedrock. The question in the preceding example doesn’t require a lot of complex analysis on the data returned from the ETF dataset. I will supply multiple instances with features and the corresponding label for reference.
It was not alive because the business knowledge required to turn data into value was confined to individuals minds, Excel sheets or lost in analog signals. We are now deciphering rules from patterns in data, embedding business knowledge into ML models, and soon, AI agents will leverage this data to make decisions on behalf of companies.
Bigdatarefers to the set of techniques used to store and/or process large amounts of data. . Usually, bigdata applications are one of two types: data at rest and data in motion. For this article, we’ll focus mainly on data at rest applications and on the Hadoop ecosystem specifically.
Machinelearning is now being used to solve many real-time problems. One big use case is with sensor data. Corporations now use this type of data to notify consumers and employees in real-time. In order to use this data, I built a very simple demo using the popular Flask framework for building web applications.
Machinelearning (ML) history can be traced back to the 1950s, when the first neural networks and ML algorithms appeared. Analysis of more than 16.000 papers on data science by MIT technologies shows the exponential growth of machinelearning during the last 20 years pumped by bigdata and deep learning advancements.
This includes tools related to the web personalization industry, retargeting, remarketing, and BigData manipulation, which are, in fact, a massive part of this statement. . Python scripts are gathering bigdata from specific landing pages, which are then stored into a Javascript (generally) container.
Hadoop and Spark are the two most popular platforms for BigData processing. They both enable you to deal with huge collections of data no matter its format — from Excel tables to user feedback on websites to images and video files. Which BigData tasks does Spark solve most effectively? How does it work?
According to the survey, 28% of respondents said they have hired data scientists to support generative AI, while 30% said they have plans to hire candidates. This role is responsible for training, developing, deploying, scheduling, monitoring, and improving scalable machinelearning solutions in the enterprise.
Information/data governance architect: These individuals establish and enforce data governance policies and procedures. Analytics/data science architect: These data architects design and implement data architecture supporting advanced analytics and data science applications, including machinelearning and artificial intelligence.
Data science is an interdisciplinary field that uses a blend of data inference and algorithm development to solve complex analytical problems. An ideal candidate has skills in the 3 fields: mathematics/ statistics/ machinelearning/ programming and business/ domain knowledge. . MachineLearning and Programming.
Refer to Steps 1 and 2 in Configuring Amazon VPC support for Amazon Q Business connectors to configure your VPC so that you have a private subnet to host an Aurora MySQL database along with a security group for your database. For instructions, refer to Access an AWS service using an interface VPC endpoint. Data Engineer at Amazon Ads.
For more information about detecting sentiment and toxicity with Amazon Comprehend, refer to Build a robust text-based toxicity predictor and Flag harmful content using Amazon Comprehend toxicity detection. Refer to the Python documentation for an example. He helps customers implement bigdata and analytics solutions.
Software-based advanced analytics — including bigdata, machinelearning, behavior analytics, deep learning and, eventually, artificial intelligence. First, let me define what I mean by prevention, starting with understanding the basic cyberattack process, sometimes referred to as the cyber threat lifecycle.
Harnessing the power of bigdata has become increasingly critical for businesses looking to gain a competitive edge. However, managing the complex infrastructure required for bigdata workloads has traditionally been a significant challenge, often requiring specialized expertise.
Ground truth data in AI refers to data that is known to be factual, representing the expected use case outcome for the system being modeled. By providing an expected outcome to measure against, ground truth data unlocks the ability to deterministically evaluate system quality. .
Access to large troves of data has become critical for machinelearning teams, and real data is often not up to the task, for different reasons. This is the gap that synthetic data startups are hoping to fill. There are two main contexts in which these startups focus: structured data and unstructured data.
It examines one of the hottest of MachineLearning techniques, Deep Learning, and provides a list of free resources for leanring and using Deep Learning-bg. Deep Learning is a very hot area of MachineLearning Research, with many remarkable recent successes, such as 97.5%
At the core of this capability are native data source connectors that seamlessly integrate and index content from multiple data sources like Salesforce, Jira, and SharePoint into a unified index. Refer to Monitoring Amazon Q Business and Q Apps for more details. These logs are then queryable using Amazon Athena.
To compete, insurance companies revolutionize the industry using AI, IoT, and bigdata. But it does need more advanced approaches that mimic human perception and judgment like AI, MachineLearning, and ML-based Robotic Process Automation. Hire machinelearning specialists on the team. Of course, not.
The term “digital transformation” refers to integrating digital technology into all aspects of an organization, which results in a fundamental shift in how the business operates and provides an enhanced experience to its consumers. Data has been used by financial institutions for a long time to help them make business decisions.
BigData enjoys the hype around it and for a reason. But the understanding of the essence of BigData and ways to analyze it is still blurred. This post will draw a full picture of what BigData analytics is and how it works. BigData and its main characteristics. Key BigData characteristics.
By handling large amounts of data to analyze and benchmark lines of business, BI promises to help identify, develop, and otherwise create new revenue opportunities. The bigdata and business analytics market could be worth $684 billion by 2030, according to Valuates Reports, if such outrageously high estimates are to be believed.
To succeed with real-time AI, data ecosystems need to excel at handling fast-moving streams of events, operational data, and machinelearning models to leverage insights and automate decision-making. report they have established a data culture 26.5% report they have a data-driven organization 39.7%
And what does machinelearning have to do with it? In this article, we’re taking you down the road of machinelearning-based personalization. You’ll learn about the types of recommender systems, their differences, strengths, weaknesses, and real-life examples. Content-based filtering strengths. Model-based.
also known as the Fourth Industrial Revolution, refers to the current trend of automation and data exchange in manufacturing technologies. It encompasses technologies such as the Internet of Things (IoT), artificial intelligence (AI), cloud computing , and bigdata analytics & insights to optimize the entire production process.
Adrian specializes in mapping the Database Management System (DBMS), BigData and NoSQL product landscapes and opportunities. Ronald van Loon has been recognized among the top 10 global influencers in BigData, analytics, IoT, BI, and data science. Ben Lorica is the Chief Data Scientist at O’Reilly Media.
Companies increasingly work with bigdata to improve performance and dominate markets. These processes are so important that companies devote whole departments just to managing the data that they have. To help your company grow, here is what you need to know about the types of bigdata analytics.
There are still many inefficiencies in managing M&A, but technologies such as artificial intelligence, especially machinelearning, are helping to make the process faster and easier. Squarespace’s reference price has been set at $50 per share. So, let’s explore the data. Image Credits: gremlin / Getty Images.
Snowplow has its origins in Dean’s and Yali Sassoon’s (Snowplow’s co-founder) consulting work, which often involved helping companies to use behavioral data from mobile apps and websites to inform their business strategies.
There were thousands of attendees at the event – lining up for book signings and meetings with recruiters to fill the endless job openings for developers experienced with MapReduce and managing BigData. This was the gold rush of the 21st century, except the gold was data.
The last two decades of technology development has led to several major innovations, including machinelearning and data science breakthroughs. Machinelearning and data science are distinct disciplines that can work together but should be treated as their own focus areas in business.
BI tools access and analyze data sets and present analytical findings in reports, summaries, dashboards, graphs, charts, and maps to provide users with detailed intelligence about the state of the business. Whereas BI studies historical data to guide business decision-making, business analytics is about looking forward.
Overview of AI in the Manufacturing Industry AI technologies, such as machinelearning and robotic process automation, can enhance manufacturing operations by increasing efficiency, improving quality control, and reducing costs. AI-powered robots can perform repetitive and dangerous tasks, minimizing human intervention.
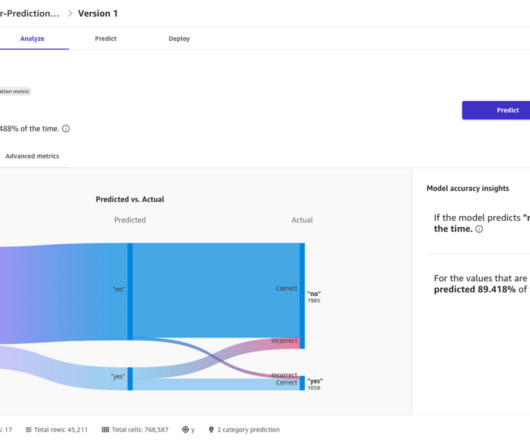
You are presented with the generated report, which details any high priority warnings, data issues, and other insights to be aware of as you add data transformations and move along the model building process. In this specific dataset, we can see that there are 27 features of different types, very little missing data, and no duplicates.
Generative AI empowers organizations to combine their data with the power of machinelearning (ML) algorithms to generate human-like content, streamline processes, and unlock innovation. About the authors Vicente Cruz Mínguez is the Head of Data & Advanced Analytics at Cepsa Química. 2 Medium 9.25
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















































Let's personalize your content