This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Before processing the request, a Lambda authorizer function associated with the API Gateway authenticates the incoming message. After it’s authenticated, the request is forwarded to another Lambda function that contains our core application logic. The code runs in a Lambda function. Implement your business logic in this file.
One such service is their serverless computing service , AWS Lambda. For the uninitiated, Lambda is an event-driven serverless computing platform that lets you run code without managing or provisioning servers and involves zero administration. How does AWS Lambda Work. Why use AWS Lambda? Read on to know.
In the age of bigdata, where information is generated at an unprecedented rate, the ability to integrate and manage diverse data sources has become a critical business imperative. Traditional data integration methods are often cumbersome, time-consuming, and unable to keep up with the rapidly evolving data landscape.
Serverless architecture is another buzzword to hit the cloud-native space, but what is it, is it worthwhile and how can it work for you? Serverless architecture is on the rise and is rapidly gaining acceptance. What is Serverless Architecture? In serverless applications, a cloud provider manages the provision of servers.
The true power of the service is that you commit to compute resources (Amazon EC2, AWS Fargate, and AWS Lambda), and not to a specific EC2 instance type of family. Examples of such workloads are bigdata, containerized workloads, CI/CD, web servers, and high-performance computing (HPC). Rearchitecting. Relational Databases.
Data science and data tools. Apache Hadoop, Spark, and BigData Foundations , January 15. Python Data Handling - A Deeper Dive , January 22. Practical Data Science with Python , January 22-23. Programming with Java Lambdas and Streams , January 22. How to Give Great Presentations , February 7.
Data science and data tools. Business Data Analytics Using Python , February 27. Designing and Implementing BigData Solutions with Azure , March 11-12. Cleaning Data at Scale , March 19. Practical Data Cleaning with Python , March 20-21. Programming with Java Lambdas and Streams , March 5.
Artificial Intelligence for BigData , April 15-16. Beginner's Guide to Writing AWS Lambda Functions in Python , April 1. Designing Serverless Architecture with AWS Lambda , April 15-16. Kubernetes Serverless with Knative , April 17. Serverless Architectures with Azure , April 23-24.
Scaling ground truth generation with a pipeline To automate ground truth generation, we provide a serverless batch pipeline architecture, shown in the following figure. The serverless batch pipeline architecture we presented offers a scalable solution for automating this process across large enterprise knowledge bases.
A couple of years ago, I wrote a post called “ 116 Hands-On Labs and Counting ” and today we have over 750 Hands-On Labs across 10 content categories — Linux, AWS, Azure, BigData, Cloud, Containers, DevOps, Google Cloud, OpenStack, and Security. Building a Serverless Application Using Step Functions, API Gateway, Lambda, and S3.
Artificial Intelligence for BigData , February 26-27. Data science and data tools. Apache Hadoop, Spark, and BigData Foundations , January 15. Python Data Handling - A Deeper Dive , January 22. Practical Data Science with Python , January 22-23. SQL Fundamentals for Data , February 19-20.
Building a Full-Stack Serverless Application on AWS. Using SQL to Retrieve Data. Using SQL to Change Data. Provisioning a Gen 2 Azure Data Lake . Trigger an AWS Lambda Function from an S3 Event. Hiding Apache Data and Implementing Safeguards. Building a Full-Stack Serverless Application on AWS.
AWS offers an array of dynamic services such as virtual private cloud (VPC), elastic compute cloud (EC2), simple storage service (S3), relational database service, AWS Lambda and more. Access to a Diverse Range of Tools. Easy Training and Certifications. What Are the Advantages of Google Cloud? Database Services.
BigData Essentials – BigData Essentials is a comprehensive introduction to the world of BigData. Starting with the definition of BigData, we describe the various characteristics of BigData and its sources. No prior AWS experience is required.
Serverless Concepts. Serverless has been gaining momentum as cloud technology continues to become more widespread. This course provides a high-level overview of the concept of Serverless computing without getting into deep technical details. BigData Essentials. Google Cloud Concepts. AWS Essentials.
Understanding Data Science Algorithms in R: Scaling, Normalization and Clustering , August 14. Real-time Data Foundations: Spark , August 15. Visualization and Presentation of Data , August 15. Python Data Science Full Throttle with Paul Deitel: Introductory AI, BigData and Cloud Case Studies , September 24.
What you need is a quick hands-on lab that teaches you (and provides resources for) how to automate backing up DynamoDB with Lambda and CloudWatch events and teaches you the why, the when, and then the how. Looking under Related Courses , you can see that it comes from the “ Automating AWS with Lambda, Python and Boto3 ” course.
Spotlight on Data: Caching BigData for Machine Learning at Uber with Zhenxiao Luo , June 17. Data Analysis Paradigms in the Tidyverse , May 30. Data Visualization with Matplotlib and Seaborn , June 4. Apache Hadoop, Spark and BigData Foundations , June 5. Real-time Data Foundations: Kafka , June 11.
Data science and data tools. Apache Hadoop, Spark, and BigData Foundations , April 22. Data Structures in Java , May 1. Cleaning Data at Scale , May 13. BigData Modeling , May 13-14. Fundamentals of Data Architecture , May 20-21. Programming with Java Lambdas and Streams , May 16.
Using serverless computing services, such as AWS Lambda, take away the need for developers or other IT staff to configure or manage cloud instances. Deploying popular containers like Kubernetes and Docker offer various benefits such as efficiency, simplicity, maintainability, portability and multi-cloud platforms.
Understanding Data Science Algorithms in R: Scaling, Normalization and Clustering , August 14. Real-time Data Foundations: Spark , August 15. Visualization and Presentation of Data , August 15. Python Data Science Full Throttle with Paul Deitel: Introductory AI, BigData and Cloud Case Studies , September 24.
Microservices with AWS Lambdas. Serverless Architecture Using AWS. Habla Computing has a solid expertise in Scala, its ecosystem of libraries and tools, and functional programming. You can benefit from their expertise in any of the courses they offer: Introduction to Scala. Purely Functional Scala. Advanced Functional Scala.
Considering this, Mobilunity can connect you with seasoned specialists who can help you achieve the following: > Streamline data management Our company offers access to Java-focused developers proficient in handling bigdata, database optimization, and high-volume processing for industries requiring robust Java-driven solutions.
Due to authentication and encryption provided at all points of connection, IoT Core and devices never exchange unverified data. Another useful feature of IoT Core is Device Shadow which stores the current or desired state of every device.
Some of the key AWS tools and components which are used to build Microservices-based architecture include: Computing power – AWS EC2 Elastic Container Service and AWS LambdaServerless Computing. Storage – Secure Storage ( Amazon S3 ) and Amazon ElastiCache.
AWS Lambda and Azure Functions offer examples of this challenge. These serverless technologies build security into the functions and offer varying monitoring and alerting capabilities. Saviynt’s cloud-native platform uses BigData technologies like ElasticSearch and Hadoop architecturally.
Along with meeting customer needs for computing and storage, they continued extending services by presenting products dealing with analytics, BigData, and IoT. The next big step in advancing Azure was introducing the container strategy, as containers and microservices took the industry to a new level. Developers tools.
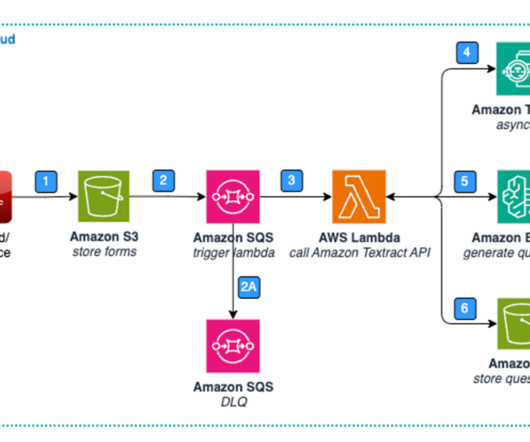
Amazon Bedrock offers a serverless experience, so you can get started quickly, privately customize FMs with your own data, and quickly integrate and deploy them into your applications using the AWS tools without having to manage the infrastructure. Lastly, the Lambda function stores the question list in Amazon S3.
Machine learning, artificial intelligence, data engineering, and architecture are driving the data space. The Strata Data Conferences helped chronicle the birth of bigdata, as well as the emergence of data science, streaming, and machine learning (ML) as disruptive phenomena. or—using Knative—in Kubernetes.
in 2008 and continuing with Java 8 in 2014, programming languages have added higher-order functions (lambdas) and other “functional” features. We’ll be working with microservices and serverless/functions-as-a-service in the cloud for a long time–and these are inherently concurrent systems. serverless, a.k.a. FaaS, a.k.a.
Enterprises are facing challenges in accessing their data assets scattered across various sources because of increasing complexities in managing vast amount of data. Traditional search methods often fail to provide comprehensive and contextual results, particularly for unstructured data or complex queries.
Amazon Bedrock is a fully managed, serverless generative AI offering from AWS that provides a range of high-performance FMs to support generative AI use cases. Multi-source data is initially received and stored in an Amazon Simple Storage Service (Amazon S3) data lake. AWS Lambda is then used to further enrich the data.
When a client email arrives through Microsoft Teams, the workflow invokes the following stages: The workflow initiates through Amazon API Gateway , taking the email and using an AWS Lambda function to extract the text contained in the email and store it in Amazon Simple Storage Service (Amazon S3).
Some key considerations include: Scalability and performance For handling large volumes of proposals and concurrent users, a serverless architecture using AWS Lambda , Amazon API Gateway , DynamoDB, and Amazon Simple Storage Service (Amazon S3) would provide improved scalability, availability, and reliability.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.








































Let's personalize your content