This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Bigdata is a sham. There is just one problem with bigdata though: it’s honking huge. Processing petabytes of data to generate business insights is expensive and time consuming. Processing petabytes of data to generate business insights is expensive and time consuming. What should a company do?
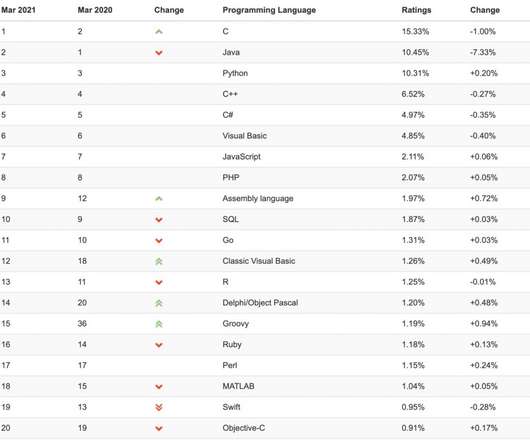
Python Python is a programming language used in several fields, including data analysis, web development, software programming, scientific computing, and for building AI and machine learning models. Job listings: 90,550 Year-over-year increase: 7% Total resumes: 32,773,163 3.
In the previous two parts, we walked through the code for training tokenization and part-of-speech models, running them on a benchmark data set, and evaluating the results. spaCy’s self-trained model and Spark-NLP perform similarly when trained using the same training data, at about 84% accuracy. Training scalability.
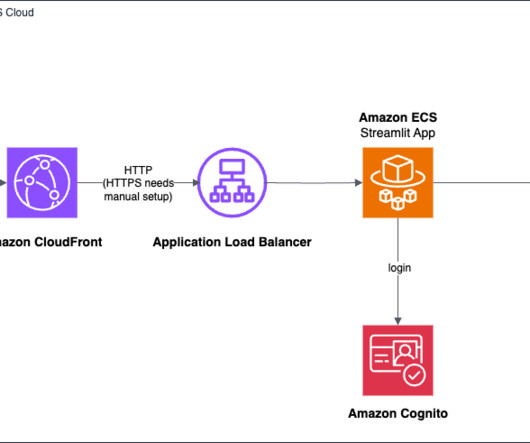
In today’s data-intensive business landscape, organizations face the challenge of extracting valuable insights from diverse data sources scattered across their infrastructure. The solution combines data from an Amazon Aurora MySQL-Compatible Edition database and data stored in an Amazon Simple Storage Service (Amazon S3) bucket.
Israeli startup Firebolt has been taking on Google’s BigQuery, Snowflake and others with a cloud data warehouse solution that it claims can run analytics on large datasets cheaper and faster than its competitors. Another sign of its growth is a big hire that the company is making. billion valuation.
Bigdata has become increasingly important in today's data-driven world. It refers to the massive amount of structured and unstructured data that is too large to be handled by traditional database systems. To efficiently process and analyze this vast amount of data, organizations need a robust and scalable architecture.
Data sovereignty and the development of local cloud infrastructure will remain top priorities in the region, driven by national strategies aimed at ensuring data security and compliance. The Internet of Things will also play a transformative role in shaping the regions smart city and infrastructure projects.
Read Alberto Pan’s article about how to solve the bigdata problem by migrating to cloud on Information Age : For many organizations, cloud computing is now a fact of life. Over the years, it’s established a reputation as the key to achieving maximum agility, flexibility, and scalability.
These devices are used to collect tons of various health and fitness-related data, such as daily activity, pulse, temperature, sleep patterns, and so on, all that in real time. But what happens to all the massive amounts of data from all these wearables and other medical and non-medical devices? Let’s see where it can come from.
Re-platforming to reduce friction Marsh McLennan had been running several strategic data centers globally, with some workloads on the cloud that had sprung up organically. Several co-location centers host the remainder of the firm’s workloads, and Marsh McLennans bigdata centers will go away once all the workloads are moved, Beswick says.
Fortunately Bedrock is here to drag that mapping process into the 21st century with its autonomous underwater vehicle and modern cloud-based data service. “We believe we’re the first cloud-native platform for seafloor data,” said Anthony DiMare, CEO and cofounder (with CTO Charlie Chiau) of Bedrock.
Azure Key Vault Secrets integration with Azure Synapse Analytics enhances protection by securely storing and dealing with connection strings and credentials, permitting Azure Synapse to enter external data resources without exposing sensitive statistics. Data Lake Storage (Gen2): Select or create a Data Lake Storage Gen2 account.
Applying artificial intelligence (AI) to data analytics for deeper, better insights and automation is a growing enterprise IT priority. But the data repository options that have been around for a while tend to fall short in their ability to serve as the foundation for bigdata analytics powered by AI.
As enterprises mature their bigdata capabilities, they are increasingly finding it more difficult to extract value from their data. This is primarily due to two reasons: Organizational immaturity with regard to change management based on the findings of data science.
Data governance definition Data governance is a system for defining who within an organization has authority and control over data assets and how those data assets may be used. It encompasses the people, processes, and technologies required to manage and protect data assets.
Re-platforming to reduce friction Marsh McLellan had been running several strategic data centers globally, with some workloads on the cloud that had sprung up organically. Several co-location centers host the remainder of the firm’s workloads, and Marsh McLellan’s bigdata centers will go away once all the workloads are moved, Beswick says.
Hadoop and Spark are the two most popular platforms for BigData processing. They both enable you to deal with huge collections of data no matter its format — from Excel tables to user feedback on websites to images and video files. Which BigData tasks does Spark solve most effectively? scalability.
Based on this data, we shall explore some of the top results in this article. It is a very versatile, platform independent and scalable language because of which it can be used across various platforms. It is frequently used in developing web applications, data science, machine learning, quality assurance, cyber security and devops.
Organizations are looking for AI platforms that drive efficiency, scalability, and best practices, trends that were very clear at BigData & AI Toronto. DataRobot Booth at BigData & AI Toronto 2022. Monitoring and Managing AI Projects with Model Observability.
In the age of bigdata, where information is generated at an unprecedented rate, the ability to integrate and manage diverse data sources has become a critical business imperative. Traditional data integration methods are often cumbersome, time-consuming, and unable to keep up with the rapidly evolving data landscape.
Today’s cloud building blocks empower any size team—even a lone engineer—to build bigdata solutions. Learn how to use open-source tools to create scalable architecture for your next project.
As businesses digitally transform and leverage technology such as artificial intelligence, the volume of data they rely on is increasing at an unprecedented pace. Analysts IDC [1] predict that the amount of global data will more than double between now and 2026.
The fundraising perhaps reflects the growing demand for platforms that enable flexible data storage and processing. One increasingly popular application is bigdata analytics, or the process of examining data to uncover patterns, correlations and trends (e.g., customer preferences).
There has been continuous innovation in this field of technology as it converges with various technology stacks associated with BigData and Artificial Intelligence. Simultaneously, the number of connected IoT devices is also increasing rapidly, posing the need to improve one of the most important aspects of IoT - scalability.
BigData enjoys the hype around it and for a reason. But the understanding of the essence of BigData and ways to analyze it is still blurred. This post will draw a full picture of what BigData analytics is and how it works. BigData and its main characteristics. Key BigData characteristics.
By George Trujillo, Principal Data Strategist, DataStax Increased operational efficiencies at airports. To succeed with real-time AI, data ecosystems need to excel at handling fast-moving streams of events, operational data, and machine learning models to leverage insights and automate decision-making.
Astera Labs , a fabless semiconductor company that builds connectivity solutions that help remove bottlenecks around high-bandwidth applications and help better allocate resources around enterprise data, has raised $50 million. Firebolt raises $127M more for its new approach to cheaper and more efficient BigData analytics.
As DPG Media grows, they need a more scalable way of capturing metadata that enhances the consumer experience on online video services and aids in understanding key content characteristics. Data aggregation – Metadata needs to be available at the top-level asset (program or movie) and must be reliably aggregated across different seasons.
Across industries like manufacturing, energy, life sciences, and retail, data drives decisions on durability, resilience, and sustainability. A significant share of this critical data resides in SAP systems , which is why so many business have invested i SAP Datasphere. What is SAP Datasphere? What is Databricks?
Portland, Oregon-based startup thatDot , which focuses on streaming event processing, today announced the launch of Quine , a new MIT-licensed open source project for data engineers that combines event streaming with graph data to create what the company calls a “streaming graph.”
Being at the top of data science capabilities, machine learning and artificial intelligence are buzzing technologies many organizations are eager to adopt. However, they often forget about the fundamental work – data literacy, collection, and infrastructure – that must be done prior to building intelligent data products.
Location data is absolutely critical to such strategies, enabling leading enterprises to not only mitigate challenges, but unlock previously unseen opportunities. Throughout the COVID-19 recovery era, location data is set to be a core ingredient for driving business intelligence and building sustainable consumer loyalty.
BigData Analysis for Customer Behaviour. Bigdata is a discipline that deals with methods of analyzing, collecting information systematically, or otherwise dealing with collections of data that are too large or too complex for conventional device data processing applications. Data Warehousing.
However, as exciting as these advancements are, data scientists often face challenges when it comes to developing UIs and to prototyping and interacting with their business users. Streamlit allows data scientists to create interactive web applications using Python, using their existing skills and knowledge.
The following is a review of the book Fundamentals of Data Engineering by Joe Reis and Matt Housley, published by O’Reilly in June of 2022, and some takeaway lessons. This book is as good for a project manager or any other non-technical role as it is for a computer science student or a data engineer.
Having a distributed and scalable graph database system is highly sought after in many enterprise scenarios. Do Not Be Misled Designing and implementing a scalable graph database system has never been a trivial task.
The 10/10-rated Log4Shell flaw in Log4j, an open source logging software that’s found practically everywhere, from online games to enterprise software and cloud data centers, claimed numerous victims from Adobe and Cloudflare to Twitter and Minecraft due to its ubiquitous presence.
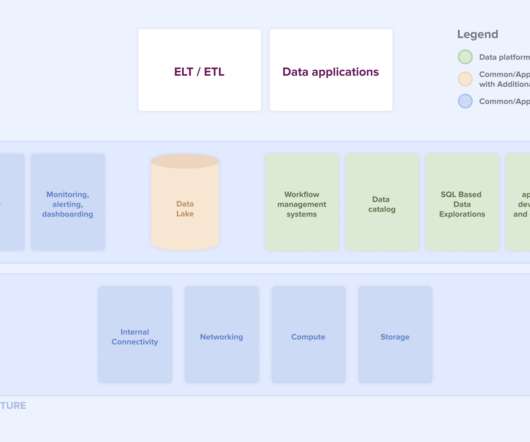
A data-platform is nothing more than a normal (cloud) platform with some additional functionality on top to make it specific to the requirements of the data domain. Instead of the applications that run on a “normal” platform like (web)services and front-ends it runs ELTs/ETLs and data applications.
These 10 strategies cover every critical aspect, from data integrity and development speed, to team expertise and executive buy-in. Data done right Neglect data quality and you’re doomed. It’s simple: your AI is only as good as the data it learns from. Bigdata is seductive, but more isn’t better if it’s garbage.
All this raw information, patterns and details is collectively called BigData. BigData analytics,on the other hand, refers to using this huge amount of data to make informed business decisions. Let us have a look at BigData Analytics more in detail. What is BigData Analytics?
Data from the Dice 2024 Tech Salary Report shows that, for certain IT skills, organizations are willing to pay more to hire experts than IT pros with strong competence. NoSQL NoSQL is a type of distributed database design that enables users to store and query data without relying on traditional structures often found in relational databases.
Today’s enterprise data analytics teams are constantly looking to get the best out of their platforms. Storage plays one of the most important roles in the data platforms strategy, it provides the basis for all compute engines and applications to be built on top of it. Separates control and data plane enabling high performance.
Furthermore, the same tools that empower cybercrime can drive fraudulent use of public-sector data as well as fraudulent access to government systems. In financial services, another highly regulated, data-intensive industry, some 80 percent of industry experts say artificial intelligence is helping to reduce fraud. Technology can help.
We live in a hybrid data world. In the past decade, the amount of structured data created, captured, copied, and consumed globally has grown from less than 1 ZB in 2011 to nearly 14 ZB in 2020. Impressive, but dwarfed by the amount of unstructured data, cloud data, and machine data – another 50 ZB.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content