This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
What is a dataengineer? Dataengineers design, build, and optimize systems for data collection, storage, access, and analytics at scale. They create data pipelines that convert raw data into formats usable by data scientists, data-centric applications, and other data consumers.
What is a dataengineer? Dataengineers design, build, and optimize systems for data collection, storage, access, and analytics at scale. They create data pipelines used by data scientists, data-centric applications, and other data consumers. The dataengineer role.
Data and bigdata analytics are the lifeblood of any successful business. Getting the technology right can be challenging but building the right team with the right skills to undertake data initiatives can be even harder — a challenge reflected in the rising demand for bigdata and analytics skills and certifications.
The following is a review of the book Fundamentals of DataEngineering by Joe Reis and Matt Housley, published by O’Reilly in June of 2022, and some takeaway lessons. This book is as good for a project manager or any other non-technical role as it is for a computer science student or a dataengineer.
Currently, the demand for data scientists has increased 344% compared to 2013. hence, if you want to interpret and analyze bigdata using a fundamental understanding of machine learning and data structure. A cloud architect has a profound understanding of storage, servers, analytics, and many more.
If we look at the hierarchy of needs in data science implementations, we’ll see that the next step after gathering your data for analysis is dataengineering. This discipline is not to be underestimated, as it enables effective data storing and reliable data flow while taking charge of the infrastructure.
With the rise of bigdata and data science, storage and retrieval have become a critical pipeline component for data use and analysis. Recently, new datastorage technologies have emerged. Which one is best suited for dataengineering? But the question is: Which one should you choose?
Bigdata can be quite a confusing concept to grasp. What to consider bigdata and what is not so bigdata? Bigdata is still data, of course. But it requires a different engineering approach and not just because of its amount. Dataengineering vs bigdataengineering.
Azure Key Vault Secrets offers a centralized and secure storage alternative for API keys, passwords, certificates, and other sensitive statistics. Azure Key Vault is a cloud service that provides secure storage and access to confidential information such as passwords, API keys, and connection strings. What is Azure Key Vault Secret?
A few months ago, I wrote about the differences between dataengineers and data scientists. An interesting thing happened: the data scientists started pushing back, arguing that they are, in fact, as skilled as dataengineers at dataengineering. Dataengineering is not in the limelight.
Data security architect: The data security architect works closely with security teams and IT teams to design data security architectures. Bigdata architect: The bigdata architect designs and implements data architectures supporting the storage, processing, and analysis of large volumes of data.
I mentioned in an earlier blog titled, “Staffing your bigdata team, ” that dataengineers are critical to a successful data journey. That said, most companies that are early in their journey lack a dedicated engineering group. Image 1: DataEngineering Skillsets.
Hadoop and Spark are the two most popular platforms for BigData processing. They both enable you to deal with huge collections of data no matter its format — from Excel tables to user feedback on websites to images and video files. Which BigData tasks does Spark solve most effectively? How does it work?
If you’re an executive who has a hard time understanding the underlying processes of data science and get confused with terminology, keep reading. We will try to answer your questions and explain how two critical data jobs are different and where they overlap. Data science vs dataengineering.
BigData is a collection of data that is large in volume but still growing exponentially over time. It is so large in size and complexity that no traditional data management tools can store or manage it effectively. While BigData has come far, its use is still growing and being explored.
A summary of sessions at the first DataEngineering Open Forum at Netflix on April 18th, 2024 The DataEngineering Open Forum at Netflix on April 18th, 2024. At Netflix, we aspire to entertain the world, and our dataengineering teams play a crucial role in this mission by enabling data-driven decision-making at scale.
DataEngineers of Netflix?—?Interview Interview with Pallavi Phadnis This post is part of our “ DataEngineers of Netflix ” series, where our very own dataengineers talk about their journeys to DataEngineering @ Netflix. Pallavi Phadnis is a Senior Software Engineer at Netflix.
The startup was founded in Manchester (it now also has a base in Denver), and this makes it one of a handful of tech startups out of the city — others we’ve recently covered include The Hut Group, Peak AI and Fractory — now hitting the big leagues and helping to put it on the innovation map as an urban center to watch.
So, along with data scientists who create algorithms, there are dataengineers, the architects of data platforms. In this article we’ll explain what a dataengineer is, the field of their responsibilities, skill sets, and general role description. What is a dataengineer?
And as data workloads continue to grow in size and use, they continue to become ever more complex. On top of that, today there are a wide range of applications and platforms that a typical organization will use to manage source material, storage, usage and so on. Doing so manually can be time-consuming, if not impossible.
Kubernetes has emerged as go to container orchestration platform for dataengineering teams. In 2018, a widespread adaptation of Kubernetes for bigdata processing is anitcipated. Organisations are already using Kubernetes for a variety of workloads [1] [2] and data workloads are up next. Storage provisioning.
BigData enjoys the hype around it and for a reason. But the understanding of the essence of BigData and ways to analyze it is still blurred. This post will draw a full picture of what BigData analytics is and how it works. BigData and its main characteristics. Key BigData characteristics.
The shift to cloud has been accelerating, and with it, a push to modernize data pipelines that fuel key applications. That is why cloud native solutions which take advantage of the capabilities such as disaggregated storage & compute, elasticity, and containerization are more paramount than ever.
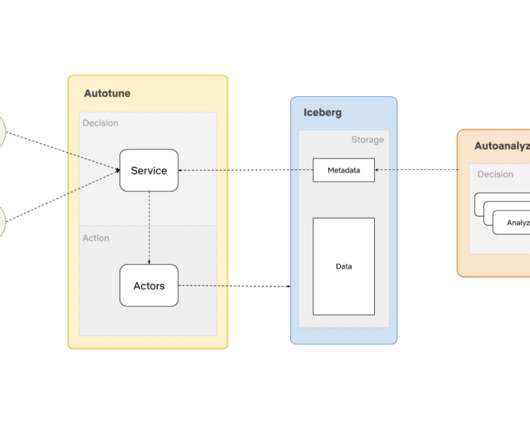
At this scale, we can gain a significant amount of performance and cost benefits by optimizing the storage layout (records, objects, partitions) as the data lands into our warehouse. We built AutoOptimize to efficiently and transparently optimize the data and metadata storage layout while maximizing their cost and performance benefits.
The solution combines data from an Amazon Aurora MySQL-Compatible Edition database and data stored in an Amazon Simple Storage Service (Amazon S3) bucket. Solution overview Amazon Q Business is a fully managed, generative AI-powered assistant that helps enterprises unlock the value of their data and knowledge.
It is built around a data lake called OneLake, and brings together new and existing components from Microsoft Power BI, Azure Synapse, and Azure Data Factory into a single integrated environment. In many ways, Fabric is Microsoft’s answer to Google Cloud Dataplex.
Whether you’re looking to earn a certification from an accredited university, gain experience as a new grad, hone vendor-specific skills, or demonstrate your knowledge of data analytics, the following certifications (presented in alphabetical order) will work for you. Check out our list of top bigdata and data analytics certifications.)
Data analytics is a discipline focused on extracting insights from data. It comprises the processes, tools and techniques of data analysis and management, including the collection, organization, and storage of data. Data analysts and others who work with analytics use a range of tools to aid them in their roles.
Deletion vectors are a storage optimization feature that replaces physical deletion with soft deletion. Data privacy regulations such as GDPR , HIPAA , and CCPA impose strict requirements on organizations handling personally identifiable information (PII) and protected health information (PHI).
Are you a dataengineer or seeking to become one? This is the first entry of a series of articles about skills you’ll need in your everyday life as a dataengineer. With SQL, you can also work with complex data types like arrays and JSON objects. This blog post is for you. CTE (Common Table Expression).
Today’s enterprise data analytics teams are constantly looking to get the best out of their platforms. Storage plays one of the most important roles in the data platforms strategy, it provides the basis for all compute engines and applications to be built on top of it. Supports Disaggregation of compute and storage.
Bigdata and data science are important parts of a business opportunity. How companies handle bigdata and data science is changing so they are beginning to rely on the services of specialized companies. User data collection is data about a user who is collected for market research purposes.
It serves as a foundation for the entire data management strategy and consists of multiple components including data pipelines; , on-premises and cloud storage facilities – data lakes , data warehouses , data hubs ;, data streaming and BigData analytics solutions ( Hadoop , Spark , Kafka , etc.);
These seemingly unrelated terms unite within the sphere of bigdata, representing a processing engine that is both enduring and powerfully effective — Apache Spark. Maintained by the Apache Software Foundation, Apache Spark is an open-source, unified engine designed for large-scale data analytics.
Few Data Management Frameworks are Business Focused Data management has been around since the beginning of IT, and a lot of technology has been focused on bigdata deployments, governance, best practices, tools, etc. However, large data hubs over the last 25 years (e.g., What has changed since then?
Bigdata exploded onto the scene in the mid-2000s and has continued to grow ever since. Today, the data is even bigger, and managing these massive volumes of data presents a new challenge for many organizations. Even if you live and breathe tech every day, it’s difficult to conceptualize how big “big” really is.
Organizations have balanced competing needs to make more efficient data-driven decisions and to build the technical infrastructure to support that goal. The features can be raw data that has been processed or analyzed or derived. The ML workflow for creating these features is referred to as feature engineering.
An overview of data warehouse types. Optionally, you may study some basic terminology on dataengineering or watch our short video on the topic: What is dataengineering. What is data pipeline. This could be a transactional database or any other storage we take data from. Data extraction.
Informatica’s comprehensive suite of DataEngineering solutions is designed to run natively on Cloudera Data Platform — taking full advantage of the scalable computing platform. The presentation of data from Cloudera within proprietary database systems is also supported. Certified Kubernetes Shared Storage Partner.
As data keeps growing in volumes and types, the use of ETL becomes quite ineffective, costly, and time-consuming. Basically, ELT inverts the last two stages of the ETL process, meaning that after being extracted from databases data is loaded straight into a central repository where all transformations occur. Data size and type.
Snowflake, Redshift, BigQuery, and Others: Cloud Data Warehouse Tools Compared. From simple mechanisms for holding data like punch cards and paper tapes to real-time data processing systems like Hadoop, datastorage systems have come a long way to become what they are now. Is it still so? Scalability opportunities.
Second, since IaaS deployments replicated the on-premises HDFS storage model, they resulted in the same data replication overhead in the cloud (typical 3x), something that could have mostly been avoided by leveraging modern object store. Storage costs. using list pricing of $0.72/hour hour using a r5d.4xlarge
Harnessing the power of bigdata has become increasingly critical for businesses looking to gain a competitive edge. However, managing the complex infrastructure required for bigdata workloads has traditionally been a significant challenge, often requiring specialized expertise.
Data obsession is all the rage today, as all businesses struggle to get data. But, unlike oil, data itself costs nothing, unless you can make sense of it. Dedicated fields of knowledge like dataengineering and data science became the gold miners bringing new methods to collect, process, and store data.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















































Let's personalize your content