This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
It stems from us seeing the explosive growth of the data warehouse space, both in terms of technology advancements as well as like accessibility and adoption. […] Our goal is to be seen as the company that makes the warehouse not just for analytics but for these operational use cases.” We’ll see if it sticks.
Given his background, it’s maybe no surprise that y42’s focus is on making life easier for dataengineers and, at the same time, putting the power of these platforms in the hands of business analysts. y42 is a powerful single source of truth for data experts and non-data experts alike.
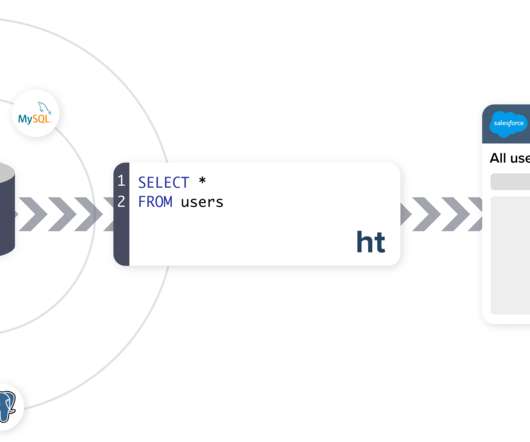
In this last installment, we’ll discuss a demo application that uses PySpark.ML to make a classification model based off of training data stored in both Cloudera’s Operational Database (powered by Apache HBase) and Apache HDFS. In this demo, half of this training data is stored in HDFS and the other half is stored in an HBase table.
Apache Spark is a very popular analytics engine used for large-scale data processing. It is widely used for many bigdata applications and use cases. We are going to use an Operational Database COD instance and Apache Spark present in the Cloudera DataEngineering experience. . Cloudera DataEngineering.
This blog post focuses on how the Kafka ecosystem can help solve the impedance mismatch between data scientists, dataengineers and production engineers. Impedance mismatch between data scientists, dataengineers and production engineers. For now, we’ll focus on Kafka.
A BigData Analytics pipeline– from ingestion of data to embedding analytics consists of three steps DataEngineering : The first step is flexible data on-boarding that accelerates time to value. This will require another product for data governance. This is colloquially called data wrangling.
Because “package tracking” in a large network is a bigdata problem, and traditional network management tools weren’t built for that volume of data. Act 3: BigData SaaS to the Rescue. Kentik offers an easy-to-use bigdata SaaS that’s purpose-built to deliver real-time network traffic intelligence.
Here at Kentik, we’ve applied many of the same concepts to Kentik DataEngine™ (KDE), a datastore optimized for querying IP flow records (NetFlow v5/9, sFlow, IPFIX) and related network data (GeoIP, BGP, SNMP). How big is big? Next, let’s look at capacity: how big is our “bigdata”?
Data Innovation Summit topics. Same as last year, the event offers six workshops (crash-course) themes, each dedicated to a unique domain area: Data-driven Strategy, Analytics & Visualisation, Machine Learning, IoT Analytics & Data Management, Data Management and DataEngineering.
What is Databricks Databricks is an analytics platform with a unified set of tools for dataengineering, data management , data science, and machine learning. It combines the best elements of a data warehouse, a centralized repository for structured data, and a data lake used to host large amounts of raw data.
In order to enable connected manufacturing and emerging IoT use cases, ECC needs a solution that can handle all types of diverse data structures and schemas from the edge, normalize the data, and then share it with any type of data consumer including BigData applications. . More Data Collection Resources.
Introduction For more than a decade now, the Hive table format has been a ubiquitous presence in the bigdata ecosystem, managing petabytes of data with remarkable efficiency and scale. Watch our webinar Supercharge Your Analytics with Open Data Lakehouse Powered by Apache Iceberg.
Given the advanced capabilities provided by cloud and bigdata technology, there’s no longer any justification for legacy monitoring appliances that summarize away all the details and force operators to swivel between siloed tools. ISPs can gain similar advantages by becoming far more data driven.
Enterprise data architects, dataengineers, and business leaders from around the globe gathered in New York last week for the 3-day Strata Data Conference , which featured new technologies, innovations, and many collaborative ideas.
And we retain network data unsummarized for 90 days (longer by arrangement). Enabled by a scale-out bigdata architecture that’s purpose-built for network operations, these capabilities are critical for effective visibility. And we retain network data unsummarized for 90 days (longer by arrangement).
Service providers of all stripes can benefit from bigdata-powered network insights in similar ways as KDDI, both in planning as well as operational realms. If you’d like to learn more, check out our products , read our Kentik DataEngine (KDE) white paper, and dig into why NFV needs advanced analytics.
And software-based network management tools silo flow data, imposing severe constraints on analytics methods that require network data correlation across many network locations. This leads us to a bigdata approach to capture and report on this unstructured IoT data. Kentik’s Scalable and Flexible IoT Analytics.
It outperforms other data warehouses on all sizes and types of data, including structured and unstructured, while scaling cost-effectively past petabytes. Running on CDW is fully integrated with streaming, dataengineering, and machine learning analytics. Migration of historical data from EDW Platform. Demo Video.
Needless to say, the little straw hut of sparse, summarized data was no match for the huffing and puffing of real-world use cases. When the big bad wolf came to the door, the system collapsed. Traditional BigData Wood House The second organization chose to build using a traditional, Hadoop-style bigdata system.
BigData Stats Reveal Industry Trends. That’s how much flow data is ingested by Kentik DataEngine (KDE), the distributed bigdata backend that powers Kentik Detect®. Are you ready to see what kinds of interesting data points are hiding in your network traffic?
BigData, Big Benefits. The key is to recognize that flow data plus BGP data makes BigData. And the key to better understanding is to recognize that flow data plus BGP data makes BigData. Only a bigdata solution can handle the required data at the required scale.
IDC’s recognition of Kentik was two-fold, based not only on the fact that we’re SaaS/cloud-based (in fact, we also can deploy our bigdata solution on an on-premises cluster) but also on the deep capabilities of our Kentik Detect product. Sign up today for a free trial , or contact us for a demo. Why Kentik? Siloes Be Gone!
But more often than not data is scattered across a myriad of disparate platforms, databases, and file systems. What’s more, that data comes in different forms and its volumes keep growing rapidly every day — hence the name of BigData. Oracle Data Integrator, IBM InfoSphere, Snaplogic, Xplenty, and. Source: Oracle.
Clustered computing for real-time BigData analytics. It has since gone on to become a key technology for running many web-scale services and products, and has also landed in traditional enterprise and government IT organizations for solving bigdata problems in finance, demographics, intelligence, and more.
But before you dive in, we recommend you reviewing our more beginner-friendly articles on data transformation: Complete Guide to Business Intelligence and Analytics: Strategy, Steps, Processes, and Tools. What is DataEngineering: Explaining the Data Pipeline, Data Warehouse, and DataEngineer Role.
It’s high time to move away from this legacy paradigm to a unified, scalable, real-time solution built on the power of bigdata. Kentik’s founders, who ran large network operations at Akamai, Netflix, YouTube, and Cloudflare, well understand the challenges faced by teams working with siloed legacy tools and fragmented data sets.
To use this powerful feature you must be running BGP between at least one device in your network and the Kentik DataEngine (KDE). You will also want to have 3-4 days worth of flow data stored in the Kentik DataEngine (KDE) for Peering Analytics to return useful information.
As traffic passes through the router on its way from the generator to the target, the router collects flow records and sends them to Kentik Detect, our bigdata network visibility solution. In the meantime you can learn more about how Kentik Detect helps you see and optimize your network traffic by visiting our website at kentik.com.
This information is turned into flow data and sent over an SSL encrypted channel to the Kentik DataEngine (KDE), from which it is queryable in Kentik Detect. Once we have the data in our distributed bigdata database there are all kinds of powerful things we can do with it, including custom query-based Dashboards.
Given that Kentik was founded primarily by network engineers, it’s easy to think of our raison d’etre in terms of addressing the day-to-day challenges of network operations. While that’s a key aspect of our mission, our unique bigdata platform for capturing, unifying, and analyzing network data actually supports a broader scope.
You can hardly compare dataengineering toil with something as easy as breathing or as fast as the wind. The platform went live in 2015 at Airbnb, the biggest home-sharing and vacation rental site, as an orchestrator for increasingly complex data pipelines. How dataengineering works. What is Apache Airflow?
A quick look at bigram usage (word pairs) doesn’t really distinguish between “data science,” “dataengineering,” “data analysis,” and other terms; the most common word pair with “data” is “data governance,” followed by “data science.” Some are genuinely exciting; others are rebrandings of older ideas.
Many enterprises have heterogeneous data platforms and technology stacks across different business units or data domains. For decades, they have been struggling with scale, speed, and correctness required to derive timely, meaningful, and actionable insights from vast and diverse bigdata environments.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.







































Let's personalize your content