
AWS Disaster Recovery Strategies – PoC with Terraform
Xebia
DECEMBER 21, 2022
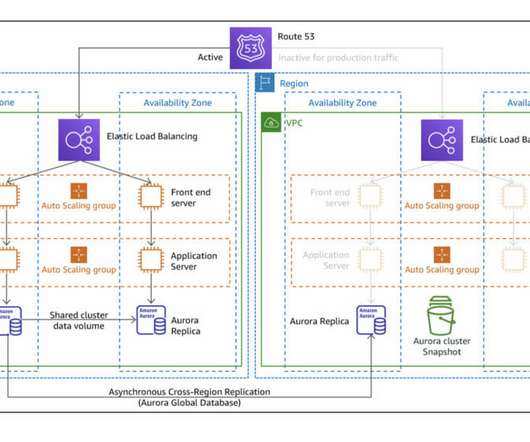
This post explores a proof-of-concept (PoC) written in Terraform , where one region is provisioned with a basic auto-scaled and load-balanced HTTP * basic service, and another recovery region is configured to serve as a plan B by using different strategies recommended by AWS. Backup service repository.














































Let's personalize your content