This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
When evaluating solutions, whether to internal problems or those of our customers, I like to keep the core metrics fairly simple: will this reduce costs, increase performance, or improve the network’s reliability? It’s often taken for granted by network specialists that there is a trade-off among these three facets. Resiliency.
Loadbalancing – you can use this to distribute a load of incoming traffic on your virtual machine. OS guest diagnostics – You can turn this on to get the metrics per minute. Backup – To protect our virtual machine from accidental deletion or corruption of disks, you can turn this on. Management.
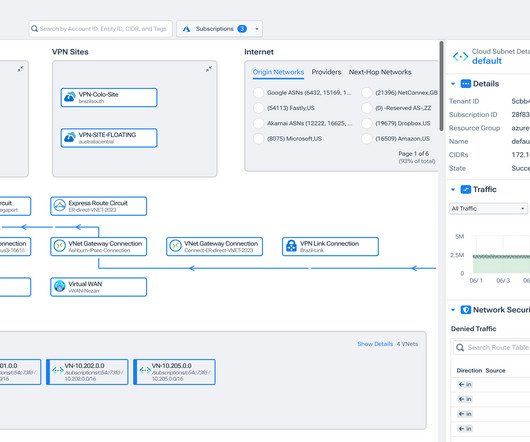
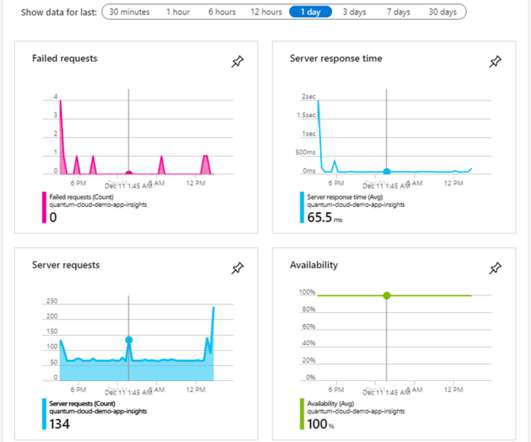
It includes rich metrics for understanding the volume, path, business context, and performance of flows traveling through Azure network infrastructure. For example, Express Route metrics include data about inbound and outbound dropped packets.
They must track key metrics, analyze user feedback, and evolve the platform to meet customer expectations. Measuring your success with key metrics A great variety of metrics helps your team measure product outcomes and pursue continuous growth strategies. It usually focuses on some testing scenarios that automation could miss.
Get the latest on the Hive RaaS threat; the importance of metrics and risk analysis; cloud security’s top threats; supply chain security advice for software buyers; and more! . Maintain offline data backups, and ensure all backup data is encrypted, immutable and comprehensive. Ghost backup attack. MFA bypass. Stalkerware.
Decompose these into quantifiable KPIs to direct the project, utilizing metrics like migration duration, savings on costs, and enhancements in performance. Configure loadbalancers, establish auto-scaling policies, and perform tests to verify functionality. lowering costs, enhancing scalability). How to prevent it?
Once the decommissioning process is finished, stop the Cassandra service on the node: Restart the Cassandra service on the remaining nodes in the cluster to ensure data redistribution and replication: LoadBalancing Cassandra employs a token-based partitioning strategy, where data is distributed across nodes based on a token value.
Tools such as Amazon Relational Database Service (RDS) can help users effectively manage PeopleSoft databases using solutions such as scalability, high availability, and automated backups. Implement Elastic LoadBalancing Implementing elastic loadbalancing (ELB) is a crucial best practice for maximizing PeopleSoft performance on AWS.
Availability ECE provides features such as automatic failover and loadbalancing, which can help ensure high availability and minimize downtime. You need to provide your own loadbalancing solution. You can use any cloud storage offering or, if on-premise, an object store such as Miro.
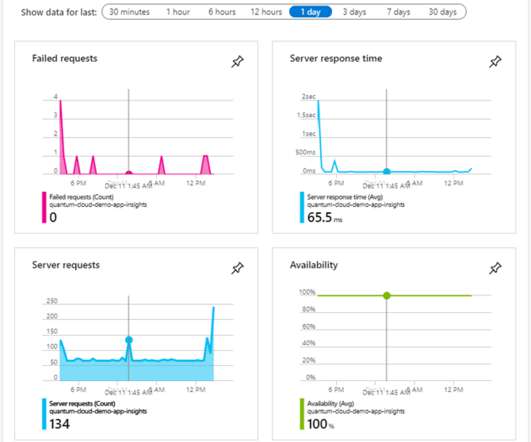
Sitefinity Cloud takes full advantage of all the available performance metrics and troubleshooting tools to keep your project in prime shape. Timed and on-demand database backups and a readily available code repository go without saying. An Application Metrics dashboard is also handy for a quick status check. A couple of them.
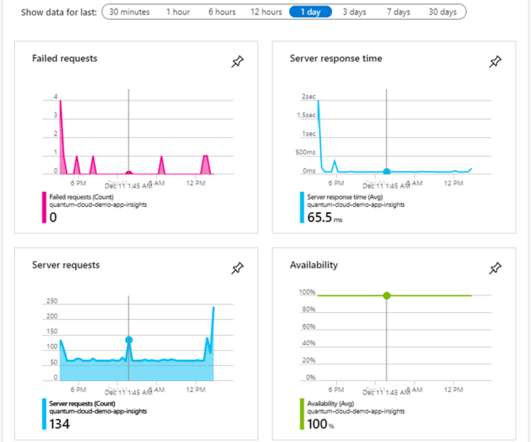
Sitefinity Cloud takes full advantage of all the available performance metrics and troubleshooting tools to keep your project in prime shape. Timed and on-demand database backups and a readily available code repository go without saying. An Application Metrics dashboard is also handy for a quick status check. A couple of them.
Sitefinity Cloud takes full advantage of all the available performance metrics and troubleshooting tools to keep your project in prime shape. Timed and on-demand database backups and a readily available code repository go without saying. An Application Metrics dashboard is also handy for a quick status check. A couple of them.
Creating a Secondary LUKS Passphrase and LUKS Header Backup. Implementing an Auto Scaling Group and Application LoadBalancer in AWS. Start by building a foundation of some general monitoring concepts, then get hands-on by working with common metrics across all levels of our platform. Encrypting a Volume with NBDE.
Infrastructure-as-a-service (IaaS) is a category that offers traditional IT services like compute, database, storage, network, loadbalancers, firewalls, etc. Monitoring and logging: collect performance and availability metrics as well as automate incident management and log aggregation.
Keyspaces provides Point-in-time Backup and Recovery to the nearest second for up to 35 days. CloudWatch provides relevant metrics , far fewer than open source Cassandra – but this reflects the serverless nature of the service where we don’t need to wrestle with the complex multivariate health indicators provided natively.
The outage caused 404 errors for downstream customers using Google Cloud LoadBalancing (GCLB). An incident begins when monitoring tools detect service metrics straying into unusual territory, which can be as simple as a service going down or running low on resources, or as potentially nuanced as increased error rates.
Network infrastructure includes everything from routers and switches to firewalls and loadbalancers, as well as the physical cables that connect all of these devices. It is important to test your backup system regularly to ensure it works when needed.
They also design and implement a detailed disaster recovery plan to ensure that all infrastructure elements (data and systems) have efficient backup solutions. The expert also documents problems and how they were addressed and creates metrics reports. Infrastructure upgrades and integration project management.
Some products may automatically create Kafka clusters in a dedicated compute instance and provide a way to connect to it, but eventually, users might need to scale the cluster, patch it, upgrade it, create backups, etc. In this case, it is not a managed solution but instead a hosted solution.
Ben shared lots of revealing graphs of metrics relevant to community health, including trends in the number of issues created and resolved since 2014, code additions and subtractions, code commits, committer stats (there are more now than 2017), release activity, commits by top contributors, google search term trends, and database engines ranking.
KEDA also serves as a Kubernetes Metrics Server and allows users to define autoscaling rules using a dedicated Kubernetes custom resource definition. ??News If left unchecked (or not considered properly), it is easy for much of this day two work to become toil?—?which Microsoft also announced the 1.0 News from #KubeCon + #CloudNativeCon??
Ben shared lots of revealing graphs of metrics relevant to community health, including trends in the number of issues created and resolved since 2014, code additions and subtractions, code commits, committer stats (there are more now than 2017), release activity, commits by top contributors, google search term trends, and database engines ranking.
But for your database or for your loadbalancers or other parts of your system. The firewalls you rely on, the loadbalancers and things like that. In the metrics you use matter because those metrics are what you’re going to be explaining to your user base about what’s going on. To your users?
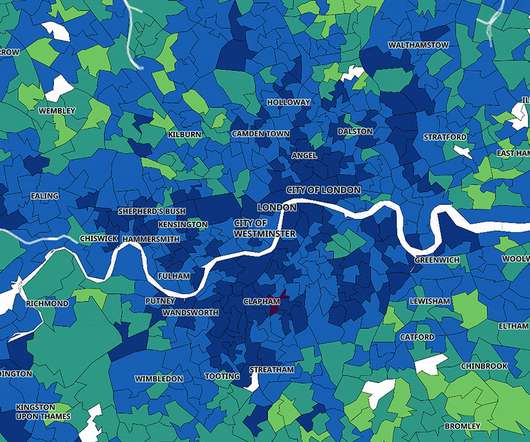
From the beginning of the COVID-19 pandemic, the United Kingdom (UK) government has made it a top priority to track key health metrics and to share those metrics with the public. Over the next year, Pouria’s team expanded the analytics dashboard, adding in more metrics and more interactive features. daily average users.
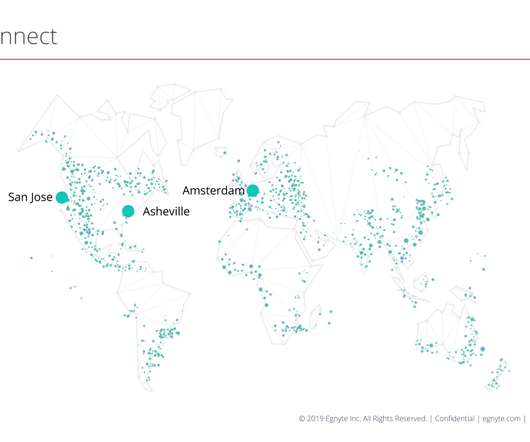
LoadBalancers / Reverse Proxy. How do you handle loadbalancing? We geo balance customers based on the IP they are accessing the system using DNS and within a data center they are routed to their corresponding POD using HAProxy and inside POD they are again routed using HAProxy. Egnyte Object Store. Elasticsearch.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



























Let's personalize your content