This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Creating and configuring Secure AWS RDS Instances with a Reader and Backup Solution. In this live AWS environment, you will learn how to create an RDS database, then successfully implement a read replica and backups for that database. Setting Up an Application LoadBalancer with an Auto Scaling Group and Route 53 in AWS.
Loadbalancing – you can use this to distribute a load of incoming traffic on your virtual machine. Backup – To protect our virtual machine from accidental deletion or corruption of disks, you can turn this on. Also, the validation of the information that you have filled earlier will happen in this tab only.
The easiest way to use Citus is to connect to the coordinator node and use it for both schema changes and distributed queries, but for very demanding applications, you now have the option to loadbalance distributed queries across the worker nodes in (parts of) your application by using a different connection string and factoring a few limitations.
You still do your DDL commands and cluster administration via the coordinator but can choose to loadbalance heavy distributed query workloads across worker nodes. The post also describes how you can loadbalance connections from your applications across your Citus nodes. Figure 2: A Citus 11.0 Upgrading to Citus 11.
Deploying and operating physical firewalls, physical loadbalancing, and many other tasks that extend across the on-premises environment and virtual domain all require different teams and quickly become difficult and expensive. For more information on the Broadcom Pinnacle Partners visit us here or find your perfect partner here.
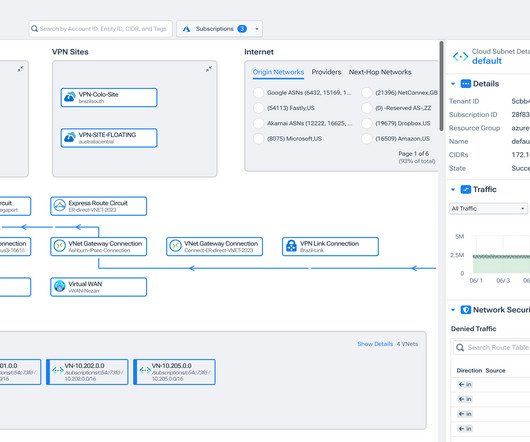
Live traffic flow arrows demonstrate how Azure Express Routes, Firewalls, LoadBalancers, Application Gateways, and VWANs connect in the Kentik Map, which updates dynamically as topology changes for effortless architecture reference.
Secure data while in transit and when stored, and consolidate encryption key management to protect information during the migration. Preparation of data and application Clean and classify information Before migration, classify data into tiers (e.g. Ensure data accuracy through comprehensive validation tests to guarantee completeness.;
When it comes to analyzing network traffic for tasks like peering, capacity planning, and DDoS attack detection, there are multiple auxiliary sources that can be utilized to supplement flow information. Back in 2015, when we monitored approximately 200 customer devices, we started with 2 nodes in active/backup mode.
One of our customers wanted us to crawl from a fixed IP address so that they could whitelist that IP for high-rate crawling without being throttled by their loadbalancer. A good example of this complexity is with IP Whitelisting. from the Algolia dashboard) and serving its own management and monitoring dashboard.
Special application solutions we offer include: CDN - We provide load-balanced application delivery and backup solutions that leverage nationwide networks provided by large ISPs, IDC centers, distributed by region. For more information on Sciens, check out their site and services. Want to know more?
By proactively computing backup paths, traffic can be swiftly switched to an alternative path when a failure occurs, reducing the impact of failures on network performance. With granular control over traffic flows, SR can be easily integrated with other network resilience mechanisms, such as loadbalancing and traffic prioritization.
Once the decommissioning process is finished, stop the Cassandra service on the node: Restart the Cassandra service on the remaining nodes in the cluster to ensure data redistribution and replication: LoadBalancing Cassandra employs a token-based partitioning strategy, where data is distributed across nodes based on a token value.
The information in this piece is curated from material available on the O’Reilly online learning platform and from interviews with Kubernetes experts. These challenges included service discovery, loadbalancing, health checks, storage management, workload scheduling, auto-scaling, and software packaging. What is Kubernetes?
In this blog, we discuss the information that shows the need for cloud computing in businesses to grow. In cloud computing, your information is stored in the cloud. Since these clouds are dedicated to the organization, no other organization can access the information. Several types of clouds in cloud computing: 1.
At a high level, if your data contained PII or other sensitive information, it remained on premise in dedicated VMWare pods. Availability ECE provides features such as automatic failover and loadbalancing, which can help ensure high availability and minimize downtime. You need to provide your own loadbalancing solution.
There’s no shortage of good information on the internet on how to use Amazon Web Services (AWS). Visibility Across Multiple Accounts in One Frame Helps Make More Informed Decisions. “ Essentially, the more high-quality information associated with a resource, the easier it becomes to manage.”. Automatically Backup Tasks.
Further information and documentation [link] . Externally facing services such as Hue and Hive on Tez (HS2) roles can be more limited to specific ports and loadbalanced as appropriate for high availability. This unified distribution is a scalable and customizable platform where you can securely run many types of workloads.
We have more information on t he release in general and all the new features in our podcast Linux Action News and episode 105. Creating a Secondary LUKS Passphrase and LUKS Header Backup. Implementing an Auto Scaling Group and Application LoadBalancer in AWS. New Content. Encrypting a Volume with NBDE.
Require “phising-resistant” multifactor authentication as much as possible, in particular for services like webmail, VPNs, accounts with access to critical systems and accounts that manage backups. Maintain offline data backups, and ensure all backup data is encrypted, immutable and comprehensive. Ghost backup attack.
You can also build automation using Lambda Functions with custom triggers like AutoScaling Lifecycle Hooks, have a LoadBalancer in front of your servers to balance the traffic as well as have DNS management in Route53.
Timed and on-demand database backups and a readily available code repository go without saying. There’s more than one way to get things right and fine-tuning is an art if you want loadbalancing, geo redundancy, autoscaling, backup and recovery to absolutely click. System logs , a.k.a.
Timed and on-demand database backups and a readily available code repository go without saying. There’s more than one way to get things right and fine-tuning is an art if you want loadbalancing, geo redundancy, autoscaling, backup and recovery to absolutely click. System logs , a.k.a.
Timed and on-demand database backups and a readily available code repository go without saying. There’s more than one way to get things right and fine-tuning is an art if you want loadbalancing, geo redundancy, autoscaling, backup and recovery to absolutely click. System logs , a.k.a.
ITIL , the Information Technology Infrastructure Library, defines problems and incidents as: A problem is “a cause or potential cause of one or more incidents.”. The outage caused 404 errors for downstream customers using Google Cloud LoadBalancing (GCLB). Let’s look at the differences between a problem and an incident.
Military and intelligence agencies, hospitals and corporations all deploy air-gapped environments to protect their sensitive information from breaches and theft. Once you have your images, you can do a backup of a Kubernetes cluster and all the configurations that were deployed to it.
The public cloud setup gives users access to comprehensive IT resources like virtual machines, computing power, application storage and data backup over the internet without requiring them to maintain the hardware themselves. There is also a risk associated with mass data transfers, as information can get intercepted during the transfer.
Network infrastructure includes everything from routers and switches to firewalls and loadbalancers, as well as the physical cables that connect all of these devices. It is important to test your backup system regularly to ensure it works when needed. Email: Sending an email is easy and quick.
The two R’s stand for Recovery Point Objective, RPO, how much new or changed data is lost because it hasn’t been backup yet, and Recovery Time Objective, RTO, how long it takes to resume operations. Backup and point in time copies are still required to protect against data corruption caused by errors or malicious attacks.
Common architectures for multicloud services include: Containerized applications or services deployed across providers and behind loadbalancers to enable an “always-on” environment. Sometimes even having cold backup services on a different cloud provider can remedy situations so that organizations can implement long-term fixes.
’ However, the databases storing the information upon which those containers rely haven’t evolved at the same pace, which complicates the sophisticated scale and deployment efforts of developers the world over. Will it have or need to have failover elections, replication, sharding and cluster management concerns?
If you want to have an unsampled feed, be sure to use a separate pipeline or add this exporter at the loadbalancer: env: - name: "AWS_ACCESS_KEY_ID" valueFrom: secretKeyRef: name: "aws-s3-creds" key: "AWS_ACCESS_KEY_ID" - name: "AWS_SECRET_ACCESS_KEY" valueFrom: secretKeyRef: name: "aws-s3-creds" key: "AWS_SECRET_ACCESS_KEY" [.]
This is especially relevant if you migrate sensitive information, which is subject to compliance requirements. data replication — or continuous duplication or making copies of data to store the content in different locations; data integration — or gathering data from different sources to provide users with a single view of information.
They also utilize tools like AWS Compute Optimizer to identify overprovisioned resources and make informed decisions on instance resizing. Mixing up auto-scaling and loadbalancing Auto-scaling automatically accommodates the number of resources to fit demand, confirming that businesses only pay for what they use. S3 Glacier.
Infrastructure engineers collect and analyze information on what is needed to handle the current traffic, keep services running, and scale them up or down if necessary. They also design and implement a detailed disaster recovery plan to ensure that all infrastructure elements (data and systems) have efficient backup solutions.
Some products may automatically create Kafka clusters in a dedicated compute instance and provide a way to connect to it, but eventually, users might need to scale the cluster, patch it, upgrade it, create backups, etc. In this case, it is not a managed solution but instead a hosted solution. How long each step takes to complete.
However, you only need to cast your mind back to when you began this journey and had questions related to topics like: Kubernetes Ingress vs loadbalancers, annotations vs CRDs, resource requests and limits, persistent claims and volumes, debugging loops when using containers etc.
Cassandra Backup & Restore Tool, takes snapshots, uploads snapshots to cloud storage or remote file systems, has throttling and automatic “de-duplication”, get it here: [link]. Features include safe scaling, backups, repairs, security, and Prometheus integration for monitoring, get it here: [link]. Source: Paul Brebner).
Cassandra Backup & Restore Tool , takes snapshots, uploads snapshots to cloud storage or remote file systems, has throttling and automatic “de-duplication”, get it here: [link]. Features include safe scaling, backups, repairs, security, and Prometheus integration for monitoring, get it here: [link]. Apache Kafka.
Modern Marvel of Cloud engineering where you don’t have to worry about maintaining the infrastructure, worry about the scale and other services such as monitoring, security, logging, disaster recovery, loadbalancing, backup, etc. It was informative and insightful, and I definitely enjoyed listening.
Good practices for authentication, backups, and software updates are the best defense against ransomware and many other attacks. It’s a minor change, but we’ve long argued that in AI, “why” may give you more information than “what.” That’s new and very dangerous territory. Operations. Observability is the next step beyond monitoring.
But for your database or for your loadbalancers or other parts of your system. The firewalls you rely on, the loadbalancers and things like that. If you showed someone a number that says, Hey, we load in five seconds on average. Many have those components aren’t working.
And the citizens of the UK were hungry for information, as they tried to make sense of what was happening. From the beginning of the COVID-19 pandemic, the United Kingdom (UK) government has made it a top priority to track key health metrics and to share those metrics with the public. As a result, the GOV.UK
LoadBalancers / Reverse Proxy. How do you handle loadbalancing? We geo balance customers based on the IP they are accessing the system using DNS and within a data center they are routed to their corresponding POD using HAProxy and inside POD they are again routed using HAProxy. Egnyte Object Store. Kubernetes.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















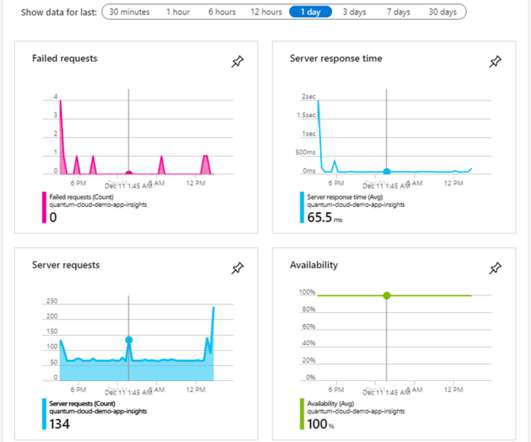
























Let's personalize your content