This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
What’s on your data dashboard as the most important metrics? From an IT security perspective, dashboards of the past were traditionally used to indicate metrics like system status (i.e., online, offline) or uptime; however, the most important metrics today are those that indicate abnormal trends or indications of compromise.
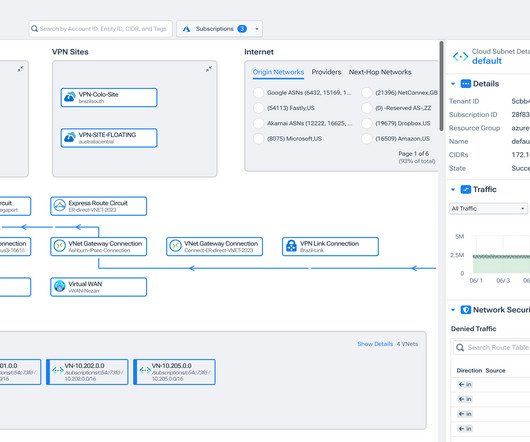
It includes rich metrics for understanding the volume, path, business context, and performance of flows traveling through Azure network infrastructure. For example, Express Route metrics include data about inbound and outbound dropped packets. Kentik Map for Azure makes denied traffic easily discoverable from each subnet visualized.
When evaluating solutions, whether to internal problems or those of our customers, I like to keep the core metrics fairly simple: will this reduce costs, increase performance, or improve the network’s reliability? When backup operations occur during staffing, customer visits, or partner-critical operations, contention occurs.
Decompose these into quantifiable KPIs to direct the project, utilizing metrics like migration duration, savings on costs, and enhancements in performance. Update DNS and network configurations Modify DNS entries and adjust firewall settings, network policies, and VPNs as necessary. lowering costs, enhancing scalability).
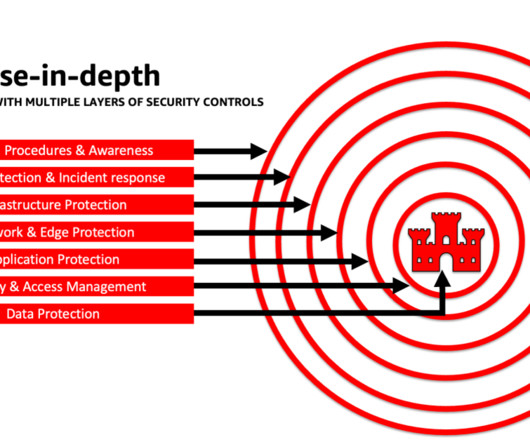
All businesses can significantly boost their information security by implementing fundamental elements of cybersecurity – vulnerability scanning , patch application, antivirus and anti-malware tools, firewalls and companywide security policies featuring well-established best practices. High) or 10.0 Act now to close your Cyber Exposure gap.
You can monitor all infrastructure components, performance metrics (CPU, memory, disk space, uptime), processes and services, event logs, application and hardware changes, and more. Mobile Devices (Smartphones, Tablets) Cloud Infrastructure (AWS, Azure, Google Cloud) Network Devices (Routers, Switches, Firewalls, Printers, etc.)
Amazon FSx for NetApp ONTAP now provides performance and capacity metrics in Amazon CloudWatch – Amazon FSx for NetApp ONTAP now provides metrics in Amazon CloudWatch, enabling you to monitor and alarm on performance and storage usage metrics for your file systems and volumes. Console/General.
It is a metric used to denote the performance of a server. CPU, RAM, and network utilization) Check logs for hardware errors Verify backups working properly. What Is Server Uptime? Uptime refers to the time a system runs without a shutdown or restart. Server uptime is monitored and measured by server monitoring tools.
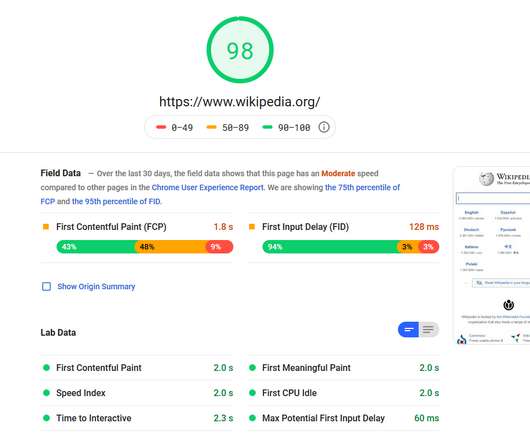
In most cases, this metric explains how much a user must wait before the target operation happens (the page renders, a transaction gets processed, etc.) Performance requirements may describe background processes invisible to users, e.g. backup. Jakob Nielsen back in 1993 has outlined 3 main metrics for a response time.
For example, a technician running routine maintenance across hundreds of devices can automate updates, monitor performance and ensure backups run smoothly from a single dashboard. Endpoint backup: Regular, automated backups for rapid data recovery and continuity. Backup Data loss can be catastrophic for any organization.
For example, a technician running routine maintenance across hundreds of devices can automate updates, monitor performance and ensure backups run smoothly from a single dashboard. Endpoint backup: Regular, automated backups for rapid data recovery and continuity. Backup Data loss can be catastrophic for any organization.
Performance Metrics. Leverage your RMM to pro-actively capture, measure and analyze the performance metrics of the systems. A glance at important metrics like memory, disk space, uptime, downtime, etc., While backing this data is one aspect of it, monitoring that backup is equally critical. None of us saw that coming.
Infrastructure-as-a-service (IaaS) is a category that offers traditional IT services like compute, database, storage, network, load balancers, firewalls, etc. Monitoring and logging: collect performance and availability metrics as well as automate incident management and log aggregation.
When Bart worked his way up to server support, he 'fixed' an Exchange issue by restoring a backup into production without warning because "It worked when the backup was taken." It turns out Bart saw GitHub as a threatening malicious code breeding ground so he had a network admin block it on the firewall.
Or if you introduce a software bug to your SDS that actively damages your datasets causing you to have to reload from backups or resynchronize from a secondary system? L2 firewall service instance. What happens if you bring your SDN system down hard and can no longer reach the control plane? Let’s look at just a couple of examples.
Network infrastructure includes everything from routers and switches to firewalls and load balancers, as well as the physical cables that connect all of these devices. Network monitoring consists of three primary components: Network devices: Includes routers, switches, firewalls and other hardware that make up the network infrastructure.
CISA recommendations include: Change the Unitronics PLC default password Require multi-factor authentication for all remote access to the OT network Unplug the PLC from the open internet, and should remote access be necessary, control it using a firewall and virtual private network (VPN) Use a different port from TCP 20256, which attackers are actively (..)
Use one of the many enterprise firewalls offered within the cloud platform marketplaces. You can deploy a virtualized enterprise firewall in a hub and spoke design, using a single or pair of highly available firewalls to secure all your cloud networks. Host-based security. Identity management and authentication.
Implementing basic cyber hygiene such as encryption, authentication (MFA), firewalls, antivirus software, patching, zero trust access and so on. Establishing roles and responsibilities for cybersecurity governance, oversight, coordination and other areas. Providing training and awareness programs for staff, management, customers, etc.
They also design and implement a detailed disaster recovery plan to ensure that all infrastructure elements (data and systems) have efficient backup solutions. The expert also documents problems and how they were addressed and creates metrics reports. Infrastructure upgrades and integration project management. Networking.
Some products may automatically create Kafka clusters in a dedicated compute instance and provide a way to connect to it, but eventually, users might need to scale the cluster, patch it, upgrade it, create backups, etc. In this case, it is not a managed solution but instead a hosted solution.
Automatic daily backup feature. Presents real-time dashboards with mix-and-match events and metrics from linked services, containers, hosts, and apps. Integrated firewall, VPN, and vulnerability detection. Provides full-text searching of all content, including pages, comments, and space descriptions.
Automatic daily backup feature. Presents real-time dashboards with mix-and-match events and metrics from linked services, containers, hosts, and apps. Integrated firewall, VPN, and vulnerability detection. Provides full-text searching of all content, including pages, comments, and space descriptions.
For example, your business may not require 99.999% uptime on a generative AI application, so the additional recovery time associated to recovery using AWS Backup with Amazon S3 Glacier may be an acceptable risk. During the training, retraining, or fine-tuning process, you should be aware of any sensitive data that is utilized.
Just a few notes on methodology: This report is based on O’Reilly’s internal “Units Viewed” metric. Firewalls, which are an important component of network security, grew 16%. In this report about how people are using O’Reilly’s learning platform, we’ll see how patterns are beginning to shift. The challenges are really very simple.
The Rapid Data Recovery Act of 2028 requires the mandatory implementation of backup schemes by publicly traded companies, government agencies, and critical infrastructure. The most effective countermeasure to ransomware is a sound backup scheme that stores copies off-line where ransomware cannot reach it. FORECAST TWO: SOX REDUX.
The firewalls you rely on, the load balancers and things like that. In the metrics you use matter because those metrics are what you’re going to be explaining to your user base about what’s going on. Many have those components aren’t working. To your users? So in our New York office, we have a main ISP pilot.
For example, there are central log analytics workspaces for all central log metrics and (audit) or resources. Here is where we find the Virtual WAN and all the Virtual Hubs, as well as the firewalls connected to those hubs and, of course, the express route circuits and Peer to Site and Site to Site Gateways.
For e.g., if accessing file system over WebDAV or FTP has performance issues, and it will take 4 hours to fix, then for those 4 hours, you can just kill FTP/WebDAV at kong/firewall and ask customers to use web UI or other mechanisms to work. We also generate quite a bit of internal application metrics using a home grown framework.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


































Let's personalize your content