This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Deletion vectors are a storage optimization feature that replaces physical deletion with soft deletion. Data privacy regulations such as GDPR , HIPAA , and CCPA impose strict requirements on organizations handling personally identifiable information (PII) and protected health information (PHI).
Snowflake, Redshift, BigQuery, and Others: Cloud Data Warehouse Tools Compared. From simple mechanisms for holding data like punch cards and paper tapes to real-time data processing systems like Hadoop, datastorage systems have come a long way to become what they are now. Is it still so? Scalability opportunities.
However, arriving at specs for other aspects of network performance requires extensive monitoring, dashboarding, and dataengineering to unify this data and help make it meaningful. When backup operations occur during staffing, customer visits, or partner-critical operations, contention occurs.
In-demand skills for the role include programming languages such as Scala, Python, open-source RDBMS, NoSQL, as well as skills involving machine learning, dataengineering, distributed microservices, and full stack systems. Dataengineer.
In-demand skills for the role include programming languages such as Scala, Python, open-source RDBMS, NoSQL, as well as skills involving machine learning, dataengineering, distributed microservices, and full stack systems. Dataengineer.
Second, since IaaS deployments replicated the on-premises HDFS storage model, they resulted in the same data replication overhead in the cloud (typical 3x), something that could have mostly been avoided by leveraging modern object store. Storage costs. using list pricing of $0.72/hour hour using a r5d.4xlarge
In general terms, data migration is the transfer of the existing historical data to new storage, system, or file format. It involves a lot of preparation and post-migration activities including planning, creating backups, quality testing, and validation of results. What makes companies migrate their data assets.
For a cloud-native data platform that supports data warehousing, dataengineering, and machine learning workloads launched by potentially thousands of concurrent users, aspects such as upgrades, scaling, troubleshooting, backup/restore, and security are crucial. How does Cloudera support Day 2 operations?
The CrunchIndexerTool can use Spark to read data from HDFS files into Apache Solr for indexing, and run the data through a so-called morphline for extraction and transformation in an efficient way. You need to configure the backup repository in solr xml to point to your cloud storage location (in this example your S3 bucket).
Informatica and Cloudera deliver a proven set of solutions for rapidly curating data into trusted information. Informatica’s comprehensive suite of DataEngineering solutions is designed to run natively on Cloudera Data Platform — taking full advantage of the scalable computing platform.
It means you must collect transactional data and move it from the database that supports transactions to another system that can handle large volumes of data. And, as is common, to transform it before loading to another storage system. But how do you move data? The simplest illustration for a data pipeline.
While these instructions are carried out for Cloudera Data Platform (CDP), Cloudera DataEngineering, and Cloudera Data Warehouse, one can extrapolate them easily to other services and other use cases as well. Keep in mind that the migrate procedure creates a backup table named “events__BACKUP__.”
Apache Hadoop is an open-source framework written in Java for distributed storage and processing of huge datasets. The keyword here is distributed since the data quantities in question are too large to be accommodated and analyzed by a single computer. Virtually, Hadoop puts no limits on the storage capacity. What is Hadoop.
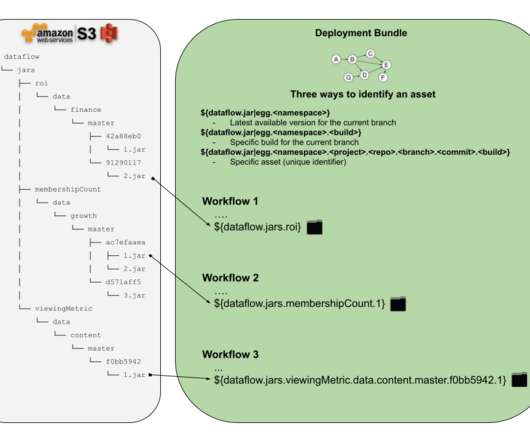
Or what if Alice wanted to add new backup functionality and she accidentally broke existing code while updating it? Let’s define some requirements that we are interested in delivering to the Netflix dataengineers or anyone who would like to schedule a workflow with some external assets in it.
In most digital spheres, especially in fintech, where all business processes are tied to data processing, a good big dataengineer is worth their weight in gold. In this article, we’ll discuss the role of an ETL engineer in data processing and why businesses need such experts nowadays. Who Is an ETL Engineer?
That means 85% of data growth results from copying data you already have. Does that figure seem excessive, especially when more copies mean more storage, which requires servers that consume yet more power? Business-friendly data views simplify access and hide IT complexity. Opportunity 2: Improve query efficiency.
This might mean a complete transition to cloud-based services and infrastructure or isolating an IT or business domain in a microservice, like databackups or auth, and establishing proof-of-concept. Either way, it’s a step that forces teams to deal with new data, network problems, and potential latency.
Data is a valuable source that needs management. If your business generates tons of data and you’re looking for ways to organize it for storage and further use, you’re at the right place. Read the article to learn what components data management consists of and how to implement a data management strategy in your business.
Three types of data migration tools. Automation scripts can be written by dataengineers or ETL developers in charge of your migration project. This makes sense when you move a relatively small amount of data and deal with simple requirements. Phases of the data migration process. Data sources and destinations.
In 2010, they launched Windows Azure, the PaaS, positioning it as an alternative to Google App Engine and Amazon EC2. They provided a few services like computing, Azure Bob storage, SQL Azure, and Azure Service Bus. The new structure enabled the opportunity to meet such customer needs in computing as storage, networking, and services.
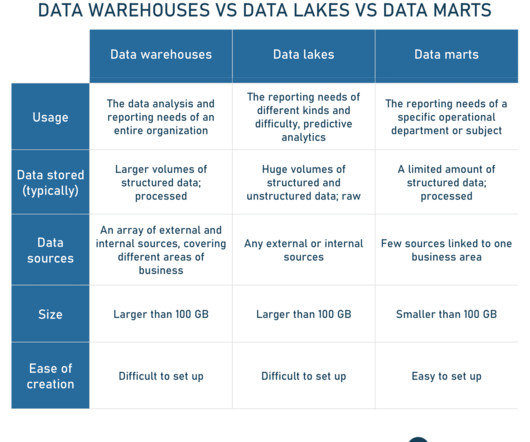
“They combine the best of both worlds: flexibility, cost effectiveness of data lakes and performance, and reliability of data warehouses.”. It allows users to rapidly ingest data and run self-service analytics and machine learning. Make sure you have encryption for data in motion as well as at rest. Data loss prevention.
Both data integration and ingestion require building data pipelines — series of automated operations to move data from one system to another. For this task, you need a dedicated specialist — a dataengineer or ETL developer. Dataengineering explained in 14 minutes. Find sources of relevant data.
Chatbots can serve as a backup for customer service representatives in this case. ?”The Building a data-driven organization. Retailers often have a significant amount of transaction and financial data that needs to be archived and utilized for both compliance and analytics purposes.
Generally, if five LOB users use the data warehouse on a public cloud for eight hours a day for one month, you pay for the use of the service and the associated cloud hardware resources (compute and storage) for this period. 150 for storage use = $15 / TB / month x 10 TB. 150 for storage use = $15 / TB / month x 10 TB.
For example, your business may not require 99.999% uptime on a generative AI application, so the additional recovery time associated to recovery using AWS Backup with Amazon S3 Glacier may be an acceptable risk.
Data analysis and databases Dataengineering was by far the most heavily used topic in this category; it showed a 3.6% Dataengineering deals with the problem of storing data at scale and delivering that data to applications. Interest in data warehouses saw an 18% drop from 2022 to 2023.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

































Let's personalize your content