This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Data privacy regulations such as GDPR , HIPAA , and CCPA impose strict requirements on organizations handling personally identifiable information (PII) and protected health information (PHI). Ensuring compliant data deletion is a critical challenge for dataengineering teams, especially in industries like healthcare, finance, and government.
In-demand skills for the role include programming languages such as Scala, Python, open-source RDBMS, NoSQL, as well as skills involving machine learning, dataengineering, distributed microservices, and full stack systems. Dataengineer.
In-demand skills for the role include programming languages such as Scala, Python, open-source RDBMS, NoSQL, as well as skills involving machine learning, dataengineering, distributed microservices, and full stack systems. Dataengineer.
Since we are comparing top providers on the market, they all have powerful data loading capabilities, including streaming data. Support for databackup and recovery. To get rid of worrying about your data, it is better to ask your vendor what disaster recovery and databackup measures they provide upfront.
However, arriving at specs for other aspects of network performance requires extensive monitoring, dashboarding, and dataengineering to unify this data and help make it meaningful. When backup operations occur during staffing, customer visits, or partner-critical operations, contention occurs.
For a cloud-native data platform that supports data warehousing, dataengineering, and machine learning workloads launched by potentially thousands of concurrent users, aspects such as upgrades, scaling, troubleshooting, backup/restore, and security are crucial. How does Cloudera support Day 2 operations?
Databackup and disaster recovery. CDP Public Cloud consists of a set of best-of-breed analytic services covering streaming, dataengineering, data warehouse, operational database, and machine learning, all secured and governed by Cloudera SDX. Encryption controls that meet or exceed best practices.
That is accomplished by delivering most technical use cases through a primarily container-based CDP services (CDP services offer a distinct environment for separate technical use cases e.g., data streaming, dataengineering, data warehousing etc.) The case of backup and disaster recovery costs . Deployment Type.
Although not elaborated on in this blog post, it is possible to use a CDP Data Hub DataEngineering cluster for pre-processing data via Spark, and then post to Solr on DDE for indexing and serving. The solr.hdfs.home of the hdfs backup repository must be set to the bucket we want to place the snapshots.
In addition to the HartCode program, The Hartford instituted a 19-week bootcamp to take recently graduated hires through training to become full-stack developers and another 12-week program to build a pipeline for its highly-coveted dataengineering role.
While these instructions are carried out for Cloudera Data Platform (CDP), Cloudera DataEngineering, and Cloudera Data Warehouse, one can extrapolate them easily to other services and other use cases as well. Keep in mind that the migrate procedure creates a backup table named “events__BACKUP__.”
In general terms, data migration is the transfer of the existing historical data to new storage, system, or file format. It involves a lot of preparation and post-migration activities including planning, creating backups, quality testing, and validation of results. What makes companies migrate their data assets.
Informatica and Cloudera deliver a proven set of solutions for rapidly curating data into trusted information. Informatica’s comprehensive suite of DataEngineering solutions is designed to run natively on Cloudera Data Platform — taking full advantage of the scalable computing platform.
This might mean a complete transition to cloud-based services and infrastructure or isolating an IT or business domain in a microservice, like databackups or auth, and establishing proof-of-concept. Either way, it’s a step that forces teams to deal with new data, network problems, and potential latency.
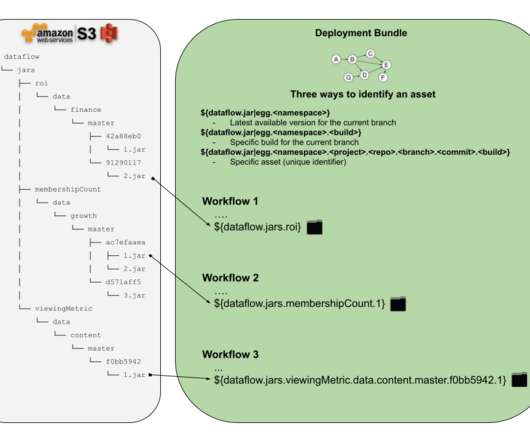
Or what if Alice wanted to add new backup functionality and she accidentally broke existing code while updating it? Let’s define some requirements that we are interested in delivering to the Netflix dataengineers or anyone who would like to schedule a workflow with some external assets in it.
These can be data science teams , data analysts, BI engineers, chief product officers , marketers, or any other specialists that rely on data in their work. The simplest illustration for a data pipeline. Data pipeline components. a data lake) doesn’t meet your needs or if you find a cheaper option.
Percona Live 2023 was an exciting open-source database event that brought together industry experts, database administrators, dataengineers, and IT leadership. Keynotes, breakout sessions, workshops, and panel discussions kept the database conversations going throughout the event.
Three types of data migration tools. Automation scripts can be written by dataengineers or ETL developers in charge of your migration project. This makes sense when you move a relatively small amount of data and deal with simple requirements. Phases of the data migration process. Data sources and destinations.
That means 85% of data growth results from copying data you already have. Granted, you need backups, but even if you back up all your new data twice, you still consume 50% more energy to store all the other extra copies. The primary driver behind data’s growth is business’ reliance on data as fuel for analytical insight.
Data integration and interoperability: consolidating data into a single view. Specialist responsible for the area: data architect, dataengineer, ETL developer. Among widely-used data security techniques are. backups to prevent data loss. Snowflake data management processes.
The demand for specialists who know how to process and structure data is growing exponentially. In most digital spheres, especially in fintech, where all business processes are tied to data processing, a good big dataengineer is worth their weight in gold. Who Is an ETL Engineer?
on-demand talk, performance, PostgreSQL) PostgreSQL Security: Defending Against External Attacks , by Taras Kloba, a big dataengineering manager at SoftServe. (on-demand on-demand talk, security, authentication, backups, PostgreSQL) Postgres Storytelling: Support in the Darkest Hour , by Boriss Mejias of EDB.
Following this approach, the tool focuses on fast retrieval of the whole data set rather than on the speed of the storing process or fetching a single record. If a node with required data fails, you can always make use of a backup. and keeps track of storage capacity, a volume of data being transferred, etc.
As IoT adoption in the enterprise continues to take shape, organizations are finding that the diverse capabilities represent another massive increase in the number of devices and the data volumes generated by these devices in enterprise networks. IoT infrastructure represents a broad diversity of technology.
Both data integration and ingestion require building data pipelines — series of automated operations to move data from one system to another. For this task, you need a dedicated specialist — a dataengineer or ETL developer. Dataengineering explained in 14 minutes.
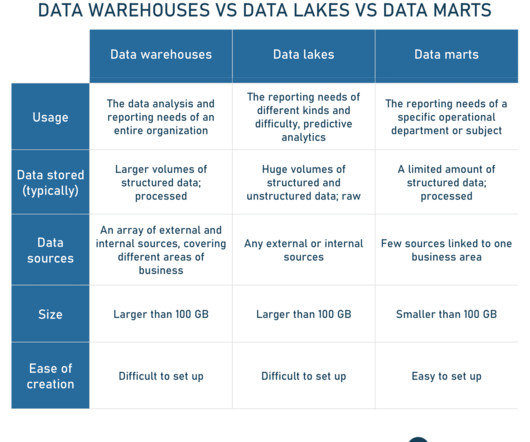
“They combine the best of both worlds: flexibility, cost effectiveness of data lakes and performance, and reliability of data warehouses.”. It allows users to rapidly ingest data and run self-service analytics and machine learning.
Chatbots can serve as a backup for customer service representatives in this case. ?”The Retailers that plan to use data wisely, need to consider technical aspects, from storage options to deriving key business insights, thinks John Radosta , enterprise solutions architect and dataengineer at KaizenTek.
Moreover, it includes some other storage-related services like Azure Files, Azure Backup, Data Box, etc. Amazon Simple Storage Service stays at the core of AWS storage while being advanced by adding Amazon Elastic File System, Amazon Elastic Block Store, AWS DataSync, AWS Snow Family, AWS Storage Gateway, AWS Backup, etc.
” In a post aimed at nontechnical managers and senior developers, he shares a framework for building a core team consisting of data scientists, domain experts and dataengineers who can build a system that can learn from its mistakes iteratively.
Data analysis and databases Dataengineering was by far the most heavily used topic in this category; it showed a 3.6% Dataengineering deals with the problem of storing data at scale and delivering that data to applications. Interest in data warehouses saw an 18% drop from 2022 to 2023.
You can hardly compare dataengineering toil with something as easy as breathing or as fast as the wind. The platform went live in 2015 at Airbnb, the biggest home-sharing and vacation rental site, as an orchestrator for increasingly complex data pipelines. How dataengineering works. What is Apache Airflow?
This operation requires a massively scalable records system with backups everywhere, reliable access functionality, and the best security in the world. The platform can absorb data streams in real-time, then pass them on to the right database or distributed file system. . The DoD’s budget of $703.7
For example, your business may not require 99.999% uptime on a generative AI application, so the additional recovery time associated to recovery using AWS Backup with Amazon S3 Glacier may be an acceptable risk.
These file formats not only help avoid data duplication into proprietary storage formats but also provide highly efficient storage formats. Multiple analytical engines (data warehousing, machine learning, dataengineering, and so on) can operate on the same data in these file formats.
Cloduera Shared Data Experience (SDX) Integration: Provide unified security, governance, and metadata management, as well as data lineage and auditing on all your data. Iceberg Replication: Out-of-the-box disaster recovery and table backup capability.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content