This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
By evaluating metrics like lead time (time to start an action) and cycle time (time spent on productive work), utilities can identify repetitive tasks that can be automated. First, set clear objectives and success metrics. For utilities in particular, it helps teams identify high-impact opportunities.
Deployment isolation: Handling multiple users and environments During the development of a new data pipeline, it is common to make tests to check if all dependencies are working correctly. Managing deployment across multiple environments can be tedious, especially when multiple users use the same workspace for development. x-cpu-ml-scala2.12
Principal wanted to use existing internal FAQs, documentation, and unstructured data and build an intelligent chatbot that could provide quick access to the right information for different roles. By integrating QnABot with Azure Active Directory, Principal facilitated single sign-on capabilities and role-based access controls.
In this way, Equalum isn’t dissimilar to startups like Striim and StreamSets, which offer tools to build data pipelines across cloud and hybrid cloud platforms (i.e., Amazon Web Services, Google Cloud, and Azure also sell access to some version of pipeline orchestration technology, albeit unsurprisingly cloud-focused.
It facilitates collaboration between a data science team and IT professionals, and thus combines skills, techniques, and tools used in dataengineering, machine learning, and DevOps — a predecessor of MLOps in the world of software development. MLOps lies at the confluence of ML, dataengineering, and DevOps.
Quantitative analysis: Quantitative analysis improves your ability to run experimental analysis, scale your data strategy, and help you implement machine learning. Product intuition: Understanding products will help you perform quantitative analysis and better predict system behavior, establish metrics, and improve debugging skills.
MLEs are usually a part of a data science team which includes dataengineers , data architects, data and business analysts, and data scientists. Who does what in a data science team. Machine learning engineers are relatively new to data-driven companies.
Data architect and other data science roles compared Data architect vs dataengineerDataengineer is an IT specialist that develops, tests, and maintains data pipelines to bring together data from various sources and make it available for data scientists and other specialists.
Each of the ‘big three’ cloud providers (AWS, Azure, GCP) offer a number of cloud certification options that individuals can get to validate their cloud knowledge and skill set, while helping them advance in their careers and broaden the scope of their achievements. . Can deploy and define metrics, monitoring and logging systems on AWS. .
Performance metrics appear in charts and graphs. . We compare the current run of a job to a baseline derived from performance metrics. Fixed Reports / DataEngineering jobs . Fixed Reports / DataEngineering Jobs. CDP runs on AWS and Azure, with Google Cloud Platform coming soon. WM can help with: .
As depicted in the chart, Cloudera Data Warehouse ran the benchmark with significantly better price-performance than any of the other competitors tested. Compared to CDW, Amazon Redshift ran the workload at 19% higher cost, Azure Synapse Analytics had 43% higher cost, DW1 had 79% higher cost, and DW2 had 5.5x higher cost.
AWS, Azure, and Google provide fully managed platforms, tools, training, and certifications to prototype and deploy AI solutions at scale. For instance, AWS Sagemaker, AWS Bedrock, Azure AI Search, Azure Open AI, and Google Vertex AI [3,4,5,6,7].
That is accomplished by delivering most technical use cases through a primarily container-based CDP services (CDP services offer a distinct environment for separate technical use cases e.g., data streaming, dataengineering, data warehousing etc.) data streaming, dataengineering, data warehousing etc.),
Andrea Tosato – Software Architect at Open Job Metis Andrea is a green software speaker, Microsoft MVP in Azure, and Developer Technologies, recognized for outstanding contributions. Paola Annis – Engineering Manager at Microsoft With more than 25 years of experience in the IT industry, Paola E.
These can be data science teams , data analysts, BI engineers, chief product officers , marketers, or any other specialists that rely on data in their work. The simplest illustration for a data pipeline. Data pipeline components. Data lakes are mostly used by data scientists for machine learning projects.
As a matter of fact, these new challenges gave way to tremendous opportunities for businesses to optimize their key success metrics by leveraging technology. Streaming data (or data-in-motion) is one such technology space that thrived during these times.
The technology was written in Java and Scala in LinkedIn to solve the internal problem of managing continuous data flows. What does the high-performance data project have to do with the real Franz Kafka’s heritage? process data in real time and run streaming analytics. How Apache Kafka streams relate to Franz Kafka’s books.
Google Professional Machine Learning Engineer implies developers knowledge of design, building, and deployment of ML models using Google Cloud tools. It includes subjects like dataengineering, model optimization, and deployment in real-world conditions. Dataengineer.
The rest is done by dataengineers, data scientists , machine learning engineers , and other high-trained (and high-paid) specialists. Tech giants: Google, Amazon SageMaker, Microsoft Azure, and IBM Watson. Microsoft Azure AutoML: a wide range of algorithms and computer vision in preview.
60 Minutes to Better Product Metrics , July 10. Data science and data tools. Practical Linux Command Line for DataEngineers and Analysts , May 20. First Steps in Data Analysis , May 20. Red Hat Certified Engineer (RHCE) Crash Course , June 11-14. Unlock Your Potential , July 9. Core Agile , July 10.
Power BI Pro and Power BI Premium (these are sometimes referred to as Power BI Service) are more feature-rich, paid services hosted on the Microsoft Azure cloud. To create the Power BI embedded capacity, you need to have at least one account with Power BI and Azure subscription in your organizational directory. Power BI data sources.
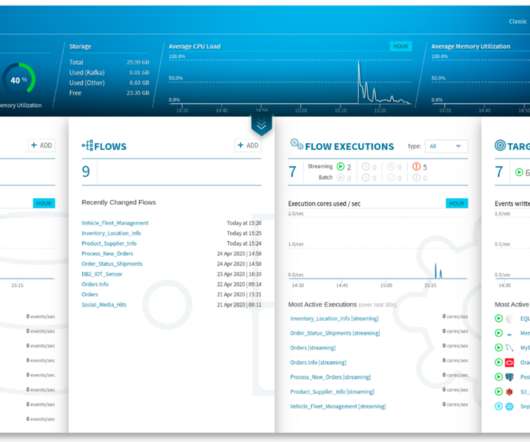
As the picture above clearly shows, organizations have data producers and operational data on the left side and data consumers and analytical data on the right side. Data producers lack ownership over the information they generate which means they are not in charge of its quality. It works like this.
Whether your goal is data analytics or machine learning , success relies on what data pipelines you build and how you do it. But even for experienced dataengineers, designing a new data pipeline is a unique journey each time. Dataengineering in 14 minutes. Flexibility. Please note! Apache Airflow.
What was worth noting was that (anecdotally) even engineers from large organisations were not looking for full workload portability (i.e. There were also two patterns of adoption of HashiCorp tooling I observed from engineers that I chatted to: Infrastructure-driven?
All ten dimensions of data quality are tightly interconnected with each other, so the following recommendations increase the value of the health information as a whole. Build and maintain medical data dictionaries. A data dictionary is a super catalog of data elements and associated fields, formats, metrics, and values.
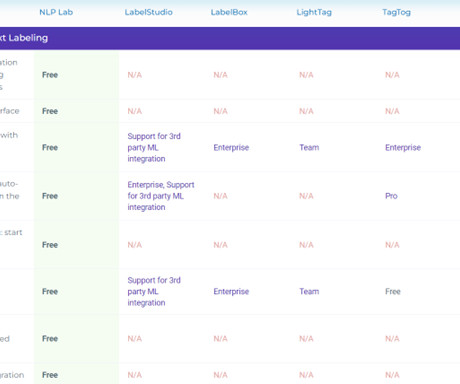
The two important functions of this tool are: – Performing different types of labeling with various data formats. LabelBox LabelBox is an efficient AI DataEngine platform for AI assisted labeling, data curation, model training, and more. It annotates images, videos, text documents, audio, and HTML, etc.
Using prepared data, AI software developers can implement techniques to evaluate and optimize model performance. It can often involve feature engineering to support relevant functionality. Relevant certifications, such as those from AWS, Google Cloud, or Microsoft Azure, can enhance an AI developer’s earning potential.
Methodology This report is based on our internal “units viewed” metric, which is a single metric across all the media types included in our platform: ebooks, of course, but also videos and live training courses. Dataengineering was the dominant topic by far, growing 35% year over year. That growth is easy to understand.
Just a few notes on methodology: This report is based on O’Reilly’s internal “Units Viewed” metric. The data used in this report covers January through November in 2022 and 2023. Data analysis and databases Dataengineering was by far the most heavily used topic in this category; it showed a 3.6%
So while we can discuss whether Answers usage is in line with other services, it’s difficult to talk about trends with so little data, and it’s impossible to do a year-over-year comparison. Our data about the cloud and cloud providers tells an interesting story. But that isn’t a good metric. We saw that play out on our platform.
The biggest skills gaps were ML modelers and data scientists (52%), understanding business use cases (49%), and dataengineering (42%). A second group of tools, including Amazon’s SageMaker (25%), Microsoft’s Azure ML Studio (21%), and Google’s Cloud ML Engine (18%), clustered around 20%, along with Spark NLP and spaCy.
The biggest challenge facing operations teams in the coming year, and the biggest challenge facing dataengineers, will be learning how to deploy AI systems effectively. We don’t see that in our data, though there are certainly some metrics to say that artificial intelligence has stalled. What’s behind this story?
Entirely new paradigms rise quickly: cloud computing, dataengineering, machine learning engineering, mobile development, and large language models. It’s less risky to hire adjunct professors with industry experience to fill teaching roles that have a vocational focus: mobile development, dataengineering, and cloud computing.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









































Let's personalize your content