This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This approach is repeatable, minimizes dependence on manual controls, harnesses technology and AI for data management and integrates seamlessly into the digital product development process. They must also select the data processing frameworks such as Spark, Beam or SQL-based processing and choose tools for ML.
Neudesic leverages extensive industry expertise and advanced skills in Microsoft Azure, AI, dataengineering, and analytics to help businesses meet the growing demands of AI. For instance, using AI to automate document preparation can cut processing time from hours to minutes.
John Snow Labs’ Medical Language Models library is an excellent choice for leveraging the power of large language models (LLM) and natural language processing (NLP) in Azure Fabric due to its seamless integration, scalability, and state-of-the-art accuracy on medical tasks.
Principal wanted to use existing internal FAQs, documentation, and unstructured data and build an intelligent chatbot that could provide quick access to the right information for different roles. By integrating QnABot with Azure Active Directory, Principal facilitated single sign-on capabilities and role-based access controls.
Cloud engineers should have experience troubleshooting, analytical skills, and knowledge of SysOps, Azure, AWS, GCP, and CI/CD systems. Keep an eye out for candidates with certifications such as AWS Certified Cloud Practitioner, Google Cloud Professional, and Microsoft Certified: Azure Fundamentals.
Analytics/data science architect: These data architects design and implement data architecture supporting advanced analytics and data science applications, including machine learning and artificial intelligence. Data architect vs. dataengineer The data architect and dataengineer roles are closely related.
Cloudera DataEngineering (CDE) is a cloud-native service purpose-built for enterprise dataengineering teams. CDE is already available in CDP Public Cloud (AWS & Azure) and will soon be available in CDP Private Cloud Experiences. image-engine="spark2". Try out Cloudera DataEngineering today!
Kedro generates simpler boilerplate code and has thorough documentation and guides. If you want to improve your data pipeline development skills and simplify adapting code to different cloud platforms, Kedro is a good choice. file with the iris dataset into Kedro pipelines and make it run on Azure.
In this blog, we’ll take you through our tried and tested best practices for setting up your DNS for use with Cloudera on Azure. Most Azure users use hub-spoke network topology. DNS servers are usually deployed in the hub virtual network or an on-prem data center instead of in the Cloudera VNET.
MLEs are usually a part of a data science team which includes dataengineers , data architects, data and business analysts, and data scientists. Who does what in a data science team. Machine learning engineers are relatively new to data-driven companies. Making business recommendations.
Opting for a centralized data and reporting model rather than training and embedding analysts in individual departments has allowed us to stay nimble and responsive to meet urgent needs, and prevented us from spending valuable resources on low-value data projects which often had little organizational impact,” Higginson says.
To get good output, you need to create a data environment that can be consumed by the model,” he says. You need to have dataengineering skills, and be able to recalibrate these models, so you probably need machine learning capabilities on your staff, and you need to be good at prompt engineering.
Shared Data Experience ( SDX ) on Cloudera Data Platform ( CDP ) enables centralized data access control and audit for workloads in the Enterprise Data Cloud. The public cloud (CDP-PC) editions default to using cloud storage (S3 for AWS, ADLS-gen2 for Azure).
What specialists and their expertise level are required to handle a data warehouse? However, all of the warehouse products available require some technical expertise to run, including dataengineering and, in some cases, DevOps. Data loading. The files can be loaded from cloud storage like Microsoft Azure or Amazon S3.
Data architect and other data science roles compared Data architect vs dataengineerDataengineer is an IT specialist that develops, tests, and maintains data pipelines to bring together data from various sources and make it available for data scientists and other specialists.
(EMEA livestream, Citus team, Citus performance, benchmarking, HammerDB, PostgreSQL) 2 Azure Cosmos DB for PostgreSQL talks (aka Citus on Azure) Auto scaling Azure Cosmos DB for PostgreSQL with Citus, Grafana, & Azure Serverless , by Lucas Borges Fernandes, a software engineer at Microsoft. (on-demand
With the combined knowledge from our previous blog posts on free training resources for AWS and Azure , you’ll be well on your way to expanding your cloud expertise and finding your own niche. For help with navigating the platform as you use it, check out GCP’s documentation for a full overview, comparisons, tutorials, and more.
Each of the ‘big three’ cloud providers (AWS, Azure, GCP) offer a number of cloud certification options that individuals can get to validate their cloud knowledge and skill set, while helping them advance in their careers and broaden the scope of their achievements. . Microsoft Azure Certifications. Azure Fundamentals.
.” Microsoft’s Azure Machine Learning Studio. Microsoft’s set of tools for machine learning includes Azure Machine Learning (which also covers Azure Machine Learning Studio), Power BI, AzureData Lake, Azure HDInsight, Azure Stream Analytics and AzureData Factory. Algorithmia.
What is Databricks Databricks is an analytics platform with a unified set of tools for dataengineering, data management , data science, and machine learning. It combines the best elements of a data warehouse, a centralized repository for structured data, and a data lake used to host large amounts of raw data.
Microsoft’s Azure Machine Learning Studio . Microsoft’s set of tools for ML includes Azure Machine Learning (including Azure Machine Learning Studio), Power BI, AzureData Lake, Azure HDInsight, Azure Stream Analytics and AzureData Factory. Pricing: try it out free for 12-months.
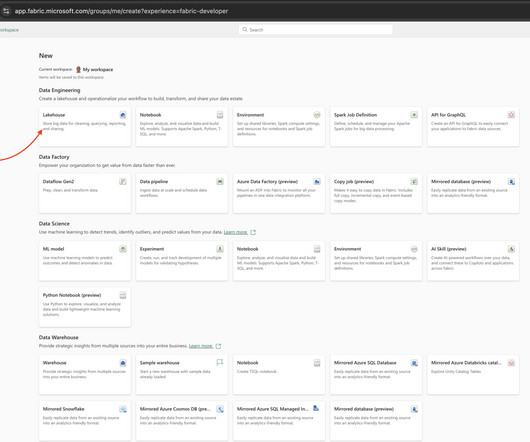
Traditionally, organizations used to provision multiple services of Azure Services, like Azure Storage, Azure Databricks, etc. To know more about Lakehouse, visit official documentation link: [link] Notebook: It is a place to store our Python code along with supporting documentation (in Markdown format).
AWS, Azure, and Google provide fully managed platforms, tools, training, and certifications to prototype and deploy AI solutions at scale. For instance, AWS Sagemaker, AWS Bedrock, Azure AI Search, Azure Open AI, and Google Vertex AI [3,4,5,6,7].
This use case was chosen because it involves semi-structured documents with quite a high density of information, rather than free flowing and verbose texts such as this blog post, so could present more of a challenge for the application. The two main services we will be using are AWS Bedrock and Azure OpenAI.
As a result, it became possible to provide real-time analytics by processing streamed data. Please note: this topic requires some general understanding of analytics and dataengineering, so we suggest you read the following articles if you’re new to the topic: Dataengineering overview.
If you want to experiment with AI or go live with your solution, there are three widely known vendors: Amazon, Google, and Azure. SageMaker provides extensive documentation to help you understand how the algorithms work in the machine learning space. Azure Machine Learning lets you accelerate and manage ML-based projects.
This dashboard is in the form of one single HTML file, including all the required data in a base64 encoded json string. You can let Elementary automatically upload this dashboard file to object storage such as GCS , S3 , or Azure Blob. Another option is to upload the dashboard file to a web server yourself.
Three types of data migration tools. Automation scripts can be written by dataengineers or ETL developers in charge of your migration project. This makes sense when you move a relatively small amount of data and deal with simple requirements. Phases of the data migration process. Data sources and destinations.
DBFS is a distributed file system that comes integrated with Databricks, a unified analytics platform designed to simplify big data processing and machine learning tasks. DBFS provides a unified interface to access data stored in various underlying storage systems. How does DBFS work?
Each policy change, or introduction of a new user or new group typically requires interaction between CDP administrators and AWS/Azure administrators and potential changes to existing applications. Let’s say that both Jon and Remi belong to the DataEngineering group. Without RAZ: Group-based access control with IDBroker.
Data integration and interoperability: consolidating data into a single view. Specialist responsible for the area: data architect, dataengineer, ETL developer. They bring data to a single platform giving a cohesive view of the business. Snowflake data management processes. Ensure data accessibility.
The Data Discovery and Exploration template contains the most commonly used services in search analytics applications. Stores source documents. Solr indexes source documents to make them searchable. If you rather want to create your own cluster definition, you can read how to in our product documentation.
Health information resource management and innovation take care of health documents across their life cycle. Health information governance and stewardship ensure compliance of data use with regulations, standards, ethical norms, and internal organizational policies. What is API: Definition, Types, Specifications, Documentation.
Power BI Pro and Power BI Premium (these are sometimes referred to as Power BI Service) are more feature-rich, paid services hosted on the Microsoft Azure cloud. To create the Power BI embedded capacity, you need to have at least one account with Power BI and Azure subscription in your organizational directory. Power BI data sources.
The technology was written in Java and Scala in LinkedIn to solve the internal problem of managing continuous data flows. cloud data warehouses — for example, Snowflake , Google BigQuery, and Amazon Redshift. Rich documentation, guides, and learning resources. Apache Kafka official documentation.
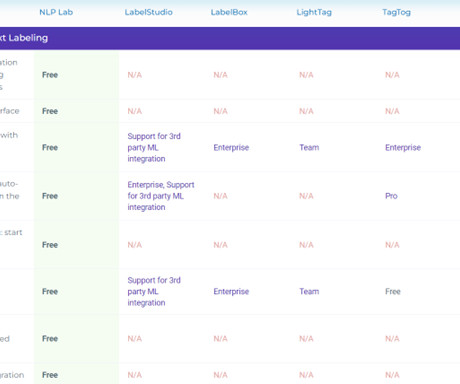
Text annotation assigns labels to a text document or various elements of its content. NLP Lab is a Free End-to-End No-Code AI platform for document labeling and AI/ML model training. to extract meaningful facts from text documents, images or PDFs and train models that will automatically predict those facts on new documents.
Developers gather and preprocess data to build and train algorithms with libraries like Keras, TensorFlow, and PyTorch. Dataengineering. Experts in the Python programming language will help you design, create, and manage data pipelines with Pandas, SQLAlchemy, and Apache Spark libraries. Creating cloud systems.
Technologies Behind Data Lake Construction Distributed Storage Systems: When building data lakes, distributed storage systems play a critical role. These systems ensure high availability and facilitate the storage of massive data volumes.
The rest is done by dataengineers, data scientists , machine learning engineers , and other high-trained (and high-paid) specialists. Tech giants: Google, Amazon SageMaker, Microsoft Azure, and IBM Watson. Microsoft Azure AutoML: a wide range of algorithms and computer vision in preview.
Depending on the type and capacities of a warehouse, it can become home to structured, semi-structured, or unstructured data. Structured data is highly-organized and commonly exists in a tabular format like Excel files. Modern data pipeline with Snowflake technology as its part. Awesome documentation. Source: Snowflake.
As the picture above clearly shows, organizations have data producers and operational data on the left side and data consumers and analytical data on the right side. Data producers lack ownership over the information they generate which means they are not in charge of its quality. It works like this.
Whether your goal is data analytics or machine learning , success relies on what data pipelines you build and how you do it. But even for experienced dataengineers, designing a new data pipeline is a unique journey each time. Dataengineering in 14 minutes. Tools to build an ELT pipeline.
Microsoft Certified: Azure AI Engineer Associate. This certification provides a solid background in implementing smart solutions on Microsoft Azure, prioritizing NLP, computer vision, and ML pipelines. It’s the most reasonable for LLM engineers employing Azure’s infrastructure and services.
Collaboration: They also collaborate with cross-functional teams, including data scientists, dataengineers, software developers, and domain experts, to ensure that AI solutions align with organizational goals. The update with the latest trends and technologies in the AI field is also important.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content