This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Azure Synapse Analytics is Microsofts end-to-give-up information analytics platform that combines massive statistics and facts warehousing abilities, permitting advanced records processing, visualization, and system mastering. What is Azure Synapse Analytics? What is Azure Key Vault Secret?
This approach is repeatable, minimizes dependence on manual controls, harnesses technology and AI for data management and integrates seamlessly into the digital product development process. They must also select the data processing frameworks such as Spark, Beam or SQL-based processing and choose tools for ML.
In this blogpost, we’re going to show how you can turn this opaqueness into transparency by using Astronomer Cosmos to automatically render your dbt project into an Airflow DAG while running dbt on Azure Container Instances. Azure Container Instances allow you to run containers on-demand in a dedicated environment. Kubernetes 3.
Since the release of Cloudera DataEngineering (CDE) more than a year ago , our number one goal was operationalizing Spark pipelines at scale with first class tooling designed to streamline automation and observability. The post Cloudera DataEngineering 2021 Year End Review appeared first on Cloudera Blog.
John Snow Labs’ Medical Language Models library is an excellent choice for leveraging the power of large language models (LLM) and natural language processing (NLP) in Azure Fabric due to its seamless integration, scalability, and state-of-the-art accuracy on medical tasks.
It was established in 1978 and certifies your ability to report on compliance procedures, how well you can assess vulnerabilities, and your knowledge of every stage in the auditing process. According to PayScale, the average salary for a CompTIA A+ certification is $70,000 per year.
There are an additional 10 paths for more advanced generative AI certification, including software development, business, cybersecurity, HR and L&D, finance and banking, marketing, retail, risk and compliance, prompt engineering, and project management. Cost : $4,000
Principal wanted to use existing internal FAQs, documentation, and unstructured data and build an intelligent chatbot that could provide quick access to the right information for different roles. It was important for Principal to maintain fine-grained access controls and make sure all data and sources remained secure within its environment.
Cloud engineers should have experience troubleshooting, analytical skills, and knowledge of SysOps, Azure, AWS, GCP, and CI/CD systems. Keep an eye out for candidates with certifications such as AWS Certified Cloud Practitioner, Google Cloud Professional, and Microsoft Certified: Azure Fundamentals.
Finance: Data on accounts, credit and debit transactions, and similar financial data are vital to a functioning business. But for data scientists in the finance industry, security and compliance, including fraud detection, are also major concerns. Data scientist skills. A method for turning data into value.
To find out, he queried Walgreens’ data lakehouse, implemented with Databricks technology on Microsoft Azure. “We You can intuitively query the data from the data lake. Users coming from a data warehouse environment shouldn’t care where the data resides,” says Angelo Slawik, dataengineer at Moonfare.
It is built around a data lake called OneLake, and brings together new and existing components from Microsoft Power BI, Azure Synapse, and AzureData Factory into a single integrated environment. In many ways, Fabric is Microsoft’s answer to Google Cloud Dataplex.
To get good output, you need to create a data environment that can be consumed by the model,” he says. You need to have dataengineering skills, and be able to recalibrate these models, so you probably need machine learning capabilities on your staff, and you need to be good at prompt engineering.
What specialists and their expertise level are required to handle a data warehouse? However, all of the warehouse products available require some technical expertise to run, including dataengineering and, in some cases, DevOps. Data loading. The files can be loaded from cloud storage like Microsoft Azure or Amazon S3.
We suggest drawing a detailed comparison of Azure vs AWS to answer these questions. Azure vs AWS market share. What is Microsoft Azure used for? Azure vs AWS features. Azure vs AWS comparison: other practical aspects. Azure vs AWS comparison: other practical aspects. Azure vs AWS: which is better?
Data architect and other data science roles compared Data architect vs dataengineerDataengineer is an IT specialist that develops, tests, and maintains data pipelines to bring together data from various sources and make it available for data scientists and other specialists.
Each of the ‘big three’ cloud providers (AWS, Azure, GCP) offer a number of cloud certification options that individuals can get to validate their cloud knowledge and skill set, while helping them advance in their careers and broaden the scope of their achievements. . Microsoft Azure Certifications. Azure Fundamentals.
This will be a blend of private and public hyperscale clouds like AWS, Azure, and Google Cloud Platform. The term “hyperscale” is used by Gartner to refer to Amazon Web Services, Microsoft Azure, and Google Cloud Platform.
You can leverage Kubernetes (K8s) and containerization technologies to consistently deploy your applications across multiple clouds including AWS, Azure, and Google Cloud, with portability to write once, run anywhere, and move from cloud to cloud with ease. This enables a range of data stewardship and regulatory compliance use cases.
AWS, Azure, and Google provide fully managed platforms, tools, training, and certifications to prototype and deploy AI solutions at scale. For instance, AWS Sagemaker, AWS Bedrock, Azure AI Search, Azure Open AI, and Google Vertex AI [3,4,5,6,7].
Temporal data and time-series analytics. Forecasting Financial Time Series with Deep Learning on Azure”. Foundational data technologies. Machine learning and AI require data—specifically, labeled data for training models. Data Platforms. Data Integration and Data Pipelines. Deep Learning.
What is Databricks Databricks is an analytics platform with a unified set of tools for dataengineering, data management , data science, and machine learning. It combines the best elements of a data warehouse, a centralized repository for structured data, and a data lake used to host large amounts of raw data.
In this article, well look at how you can use Prisma Cloud DSPM to add another layer of security to your Databricks operations, understand what sensitive data Databricks handles and enable you to quickly address misconfigurations and vulnerabilities in the storage layer. Databricks is often used for core operational or analytical workloads.
Developers gather and preprocess data to build and train algorithms with libraries like Keras, TensorFlow, and PyTorch. Dataengineering. Experts in the Python programming language will help you design, create, and manage data pipelines with Pandas, SQLAlchemy, and Apache Spark libraries. Creating cloud systems.
Three types of data migration tools. Automation scripts can be written by dataengineers or ETL developers in charge of your migration project. This makes sense when you move a relatively small amount of data and deal with simple requirements. Phases of the data migration process. Data sources and destinations.
Percona Live 2023 was an exciting open-source database event that brought together industry experts, database administrators, dataengineers, and IT leadership. The top factors leading to respondents choosing proprietary databases included greater stability (68%), more security (63%), and regulatory compliance (61%).
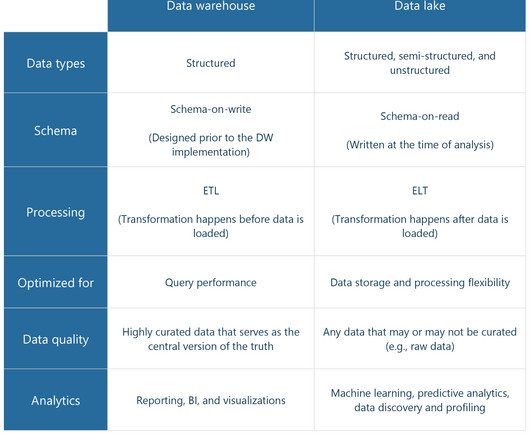
Instead of relying on traditional hierarchical structures and predefined schemas, as in the case of data warehouses, a data lake utilizes a flat architecture. This structure is made efficient by dataengineering practices that include object storage. Watch our video explaining how dataengineering works.
Technologies Behind Data Lake Construction Distributed Storage Systems: When building data lakes, distributed storage systems play a critical role. These systems ensure high availability and facilitate the storage of massive data volumes.
DataRobot enables entire teams — from data scientists to dataengineers and from IT to business users — to collaborate on a unified platform. By partnering with major cloud companies like AWS, Google Cloud, Azure, and VMware, DataRobot helps customers harness the power of their data wherever it lives.
Large language models can run through, research, and interpret large amounts of text data like reports and financial statements, to recognize trends and map out possible risks. This knowledge enables companies to predict different cases including market shifts or compliance challenges and simplifies addressing potential troubles.
So, we’ll only touch on its most vital aspects, instruments, and areas of interest — namely, data quality, patient identity, database administration, and compliance with privacy regulations. Cloud capabilities and HIPAA compliance out of the box. What is health information management: brief introduction the HIM landscape.
As the picture above clearly shows, organizations have data producers and operational data on the left side and data consumers and analytical data on the right side. Data producers lack ownership over the information they generate which means they are not in charge of its quality. It works like this.
Data Handling and Big Data Technologies Since AI systems rely heavily on data, engineers must ensure that data is clean, well-organized, and accessible. Do AI Engineer skills incorporate cloud computing? How important are soft skills for AI engineers?
Schema enforcement allows users to control data integrity and quality by declining any writes that don’t fit the table’s schema. Schema evolution enables changes of the table’s current schema in compliance with dynamic data. Of course, there may be other motivations behind moving to a data lakehouse.
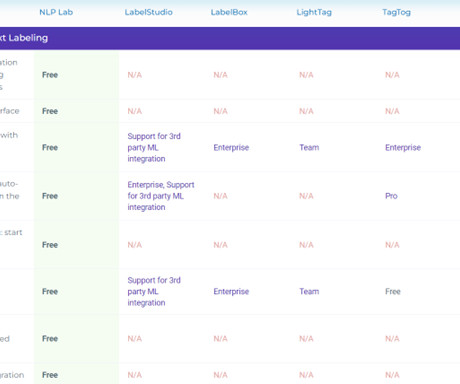
The two important functions of this tool are: – Performing different types of labeling with various data formats. LabelBox LabelBox is an efficient AI DataEngine platform for AI assisted labeling, data curation, model training, and more. It annotates images, videos, text documents, audio, and HTML, etc.
Data analysis and databases Dataengineering was by far the most heavily used topic in this category; it showed a 3.6% Dataengineering deals with the problem of storing data at scale and delivering that data to applications. Interest in data warehouses saw an 18% drop from 2022 to 2023.
Governance (year-over-year increase of 72%) is a very broad topic that includes virtually every aspect of compliance and risk management. DataData is another very broad category, encompassing everything from traditional business analytics to artificial intelligence. That growth is easy to understand.
A quick look at bigram usage (word pairs) doesn’t really distinguish between “data science,” “dataengineering,” “data analysis,” and other terms; the most common word pair with “data” is “data governance,” followed by “data science.” Even on Azure, Linux dominates.
As a Databricks Champion working for Perficient’s Data Solutions team , I spend most of my time installing and managing Databricks on Azure and AWS. I am limiting myself to the question of which AWS versus Azure from a Databricks perspective. The Databricks integration with these products on Azure is seamless.
Recently, we sponsored a study with IDC* that surveyed teams of data scientists, dataengineers, developers, and IT professionals working on AI projects across enterprises worldwide. Additionally, we expose our capabilities to the tools data teams use, such as AWS SageMaker, Google Vertex, and Azure ML Studio.
Databricks is a powerful Data + AI platform that enables companies to efficiently build data pipelines, perform large-scale analytics, and deploy machine learning models. Organizations turn to Databricks for its ability to unify dataengineering, data science, and business analytics, simplifying collaboration and driving innovation.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content