This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Region Evacuation with static anycast IP approach Welcome back to our comprehensive "Building Resilient Public Networking on AWS" blog series, where we delve into advanced networking strategies for regional evacuation, failover, and robust disaster recovery. Find the detailed guide here.
Software-as-a-service (SaaS) applications with tenant tiering SaaS applications are often architected to provide different pricing and experiences to a spectrum of customer profiles, referred to as tiers. The user prompt is then routed to the LLM associated with the task category of the reference prompt that has the closest match.
To achieve these goals, the AWS Well-Architected Framework provides comprehensive guidance for building and improving cloud architectures. This allows teams to focus more on implementing improvements and optimizing AWS infrastructure. This systematic approach leads to more reliable and standardized evaluations.
Recognizing this need, we have developed a Chrome extension that harnesses the power of AWS AI and generative AI services, including Amazon Bedrock , an AWS managed service to build and scale generative AI applications with foundation models (FMs). The user signs in by entering a user name and a password.
It also uses a number of other AWS services such as Amazon API Gateway , AWS Lambda , and Amazon SageMaker. Shared components refer to the functionality and features shared by all tenants. You can use AWS services such as Application Load Balancer to implement this approach. API Gateway also provides a WebSocket API.
This post discusses how to use AWS Step Functions to efficiently coordinate multi-step generative AI workflows, such as parallelizing API calls to Amazon Bedrock to quickly gather answers to lists of submitted questions. We're more than happy to provide further references upon request.
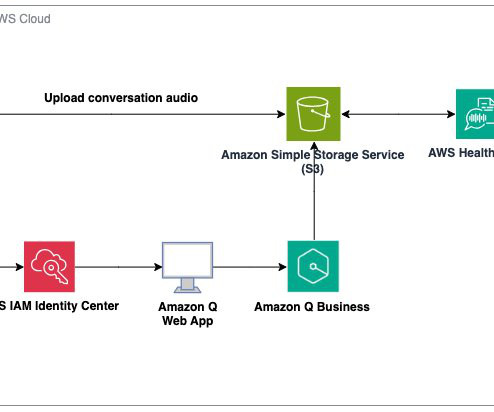
During re:Invent 2023, we launched AWS HealthScribe , a HIPAA eligible service that empowers healthcare software vendors to build their clinical applications to use speech recognition and generative AI to automatically create preliminary clinician documentation. AWS HealthScribe will then output two files which are also stored on Amazon S3.
Earlier this year, we published the first in a series of posts about how AWS is transforming our seller and customer journeys using generative AI. Field Advisor serves four primary use cases: AWS-specific knowledge search With Amazon Q Business, weve made internal data sources as well as public AWS content available in Field Advisors index.
AWS Trainium and AWS Inferentia based instances, combined with Amazon Elastic Kubernetes Service (Amazon EKS), provide a performant and low cost framework to run LLMs efficiently in a containerized environment. For more information on how to view and increase your quotas, refer to Amazon EC2 service quotas.
Using vLLM on AWS Trainium and Inferentia makes it possible to host LLMs for high performance inference and scalability. Deploy vLLM on AWS Trainium and Inferentia EC2 instances In these sections, you will be guided through using vLLM on an AWS Inferentia EC2 instance to deploy Meta’s newest Llama 3.2 You will use inf2.xlarge
Large Medium – This refers to the material or technique used in creating the artwork. This might involve incorporating additional data such as reference images or rough sketches as conditioning inputs alongside your text prompts. You can provide extensive details, such as the gender of a character, their clothing, and the setting.
Refer to Supported Regions and models for batch inference for current supporting AWS Regions and models. To address this consideration and enhance your use of batch inference, we’ve developed a scalable solution using AWS Lambda and Amazon DynamoDB. Access to your selected models hosted on Amazon Bedrock.
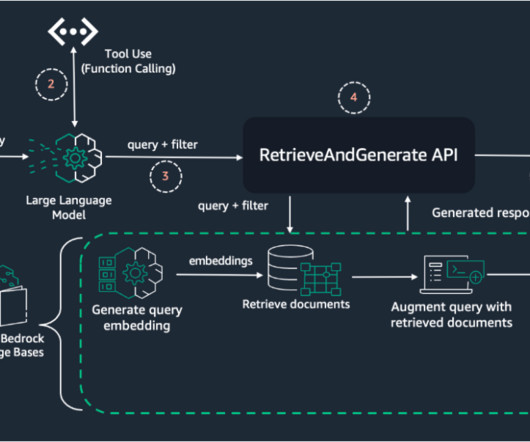
AWS offers powerful generative AI services , including Amazon Bedrock , which allows organizations to create tailored use cases such as AI chat-based assistants that give answers based on knowledge contained in the customers’ documents, and much more. The following figure illustrates the high-level design of the solution.
Model customization refers to adapting a pre-trained language model to better fit specific tasks, domains, or datasets. Solution overview To evaluate the effectiveness of RAG compared to model customization, we designed a comprehensive testing framework using a set of AWS-specific questions.
Response latency refers to the time between the user finishing their speech and beginning to hear the AI assistants response. AWS Local Zones are a type of edge infrastructure deployment that places select AWS services close to large population and industry centers. Next, create a subnet inside each Local Zone.
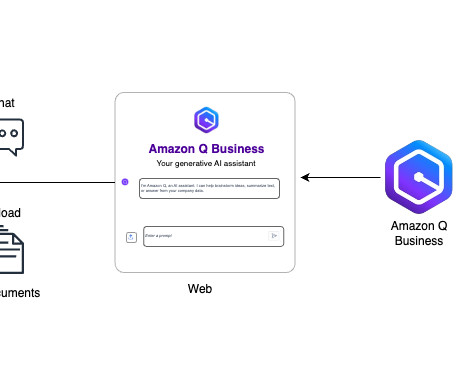
Amazon Q Business as a web experience makes AWS best practices readily accessible, providing cloud-centered recommendations quickly and making it straightforward to access AWS service functions, limits, and implementations. For more on MuleSofts journey to cloud computing, refer to Why a Cloud Operating Model?
This solution can serve as a valuable reference for other organizations looking to scale their cloud governance and enable their CCoE teams to drive greater impact. The challenge: Enabling self-service cloud governance at scale Hearst undertook a comprehensive governance transformation for their Amazon Web Services (AWS) infrastructure.
Developer tools The solution also uses the following developer tools: AWS Powertools for Lambda – This is a suite of utilities for Lambda functions that generates OpenAPI schemas from your Lambda function code. After deployment, the AWS CDK CLI will output the web application URL. Python 3.9 or later Node.js
For the unacquainted, Web3 refers to a set of protocols led by blockchain, that intends to reinvent how the Internet is wired in the backend). Put simply, Alchemy wants to do for blockchain and Web3 what AWS (Amazon Web Services) did for the internet. ?? Alchemy raises $80M at a $505M valuation to be the ‘AWS for blockchain’.
Amazon Bedrock cross-Region inference capability that provides organizations with flexibility to access foundation models (FMs) across AWS Regions while maintaining optimal performance and availability. We provide practical examples for both SCP modifications and AWS Control Tower implementations.
With this launch, you can now access Mistrals frontier-class multimodal model to build, experiment, and responsibly scale your generative AI ideas on AWS. AWS is the first major cloud provider to deliver Pixtral Large as a fully managed, serverless model. Additionally, Pixtral Large supports the Converse API and tool usage.
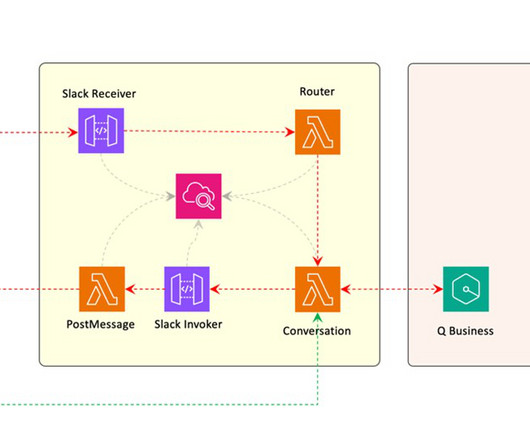
It uses Amazon Bedrock , AWS Health , AWS Step Functions , and other AWS services. Event-driven operations management Operational events refer to occurrences within your organization’s cloud environment that might impact the performance, resilience, security, or cost of your workloads.
Observability refers to the ability to understand the internal state and behavior of a system by analyzing its outputs, logs, and metrics. Security – The solution uses AWS services and adheres to AWS Cloud Security best practices so your data remains within your AWS account.
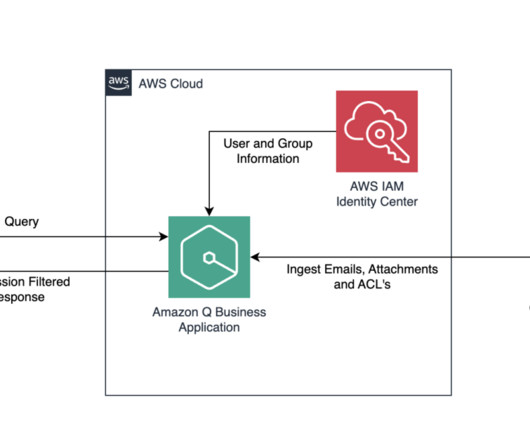
The web application that the user uses to retrieve answers is connected to an identity provider (IdP) or AWS IAM Identity Center. The user’s credentials from the IdP or IAM Identity Center are referred to here as the federated user credentials. Refer to How Amazon Q Business connector crawls Gmail ACLs for more information.
You may check out additional reference notebooks on aws-samples for how to use Meta’s Llama models hosted on Amazon Bedrock. You can implement these steps either from the AWS Management Console or using the latest version of the AWS Command Line Interface (AWS CLI). 0 means not expensive, 1 means expensive.
Prerequisites Before you dive into the integration process, make sure you have the following prerequisites in place: AWS account – You’ll need an AWS account to access and use Amazon Bedrock. You can interact with Amazon Bedrock using AWS SDKs available in Python, Java, Node.js, and more.
The Systems Manager (SSM) streamlines managing Windows instances in AWS. Instead of taking a backup, creating a new instance, and reconfiguring the environmentwhich is time-consuming and impacts business operationswe leverage AWS Systems Manager (SSM) to efficiently recover access without disruption.
The computer use agent demo powered by Amazon Bedrock Agents provides the following benefits: Secure execution environment Execution of computer use tools in a sandbox environment with limited access to the AWS ecosystem and the web. Prerequisites AWS Command Line Interface (CLI), follow instructions here. Require Python 3.11
To evaluate the metadata quality, the team used reference-free LLM metrics, inspired by LangSmith. DPG Media chose Amazon Transcribe for its ease of transcription and low maintenance, with the added benefit of incremental improvements by AWS over the years.
Why LoRAX for LoRA deployment on AWS? The surge in popularity of fine-tuning LLMs has given rise to multiple inference container methods for deploying LoRA adapters on AWS. Prerequisites For this guide, you need access to the following prerequisites: An AWS account Proper permissions to deploy EC2 G6 instances.
If you dont have an existing application, you can create an application integrated with AWS IAM Identity Center or AWS Identity and Access Management (IAM) identity federation. You can find your web experience ID with the list-web-experiences AWS CLI command. Amazon Q Business hosts the web experience on an AWS domain.
Use the us-west-2 AWS Region to run this demo. Prerequisites This notebook is designed to run on AWS, using Amazon Bedrock for both Anthropics Claude 3 Sonnet and Stability AI model access. Make sure you have the following set up before moving forward: An AWS account. An Amazon SageMaker domain. Access to Stability AIs SD3.5
Prerequisites To perform this solution, complete the following: Create and activate an AWS account. Make sure your AWS credentials are configured correctly. This tutorial assumes you have the necessary AWS Identity and Access Management (IAM) permissions. If you’re new to Amazon EC2, refer to the Amazon EC2 User Guide.
AWS CloudFormation, a key service in the AWS ecosystem, simplifies IaC by allowing users to easily model and set up AWS resources. This blog explores the best practices for utilizing AWS CloudFormation to achieve reliable, secure, and efficient infrastructure management. Why Use AWS CloudFormation? Example: 3.
Large organizations often have many business units with multiple lines of business (LOBs), with a central governing entity, and typically use AWS Organizations with an Amazon Web Services (AWS) multi-account strategy. LOBs have autonomy over their AI workflows, models, and data within their respective AWS accounts.
In this post, we explore how you can use Amazon Q Business , the AWS generative AI-powered assistant, to build a centralized knowledge base for your organization, unifying structured and unstructured datasets from different sources to accelerate decision-making and drive productivity. In this post, we use IAM Identity Center as the SAML 2.0-aligned
Enhancing AWS Support Engineering efficiency The AWS Support Engineering team faced the daunting task of manually sifting through numerous tools, internal sources, and AWS public documentation to find solutions for customer inquiries. Then we introduce the solution deployment using three AWS CloudFormation templates.
For a comprehensive overview of metadata filtering and its benefits, refer to Amazon Bedrock Knowledge Bases now supports metadata filtering to improve retrieval accuracy. Prerequisites Before proceeding with this tutorial, make sure you have the following in place: AWS account – You should have an AWS account with access to Amazon Bedrock.
Amazon Bedrock offers a serverless experience so you can get started quickly, privately customize FMs with your own data, and integrate and deploy them into your applications using AWS tools without having to manage infrastructure. Refer to the GitHub repository for deployment instructions.
How does High-Performance Computing on AWS differ from regular computing? HPC services on AWS Compute Technically you could design and build your own HPC cluster on AWS, it will work but you will spend time on plumbing and undifferentiated heavy lifting. AWS has two services to support your HPC workload.
Amazon Bedrock Flows offers an intuitive visual builder and a set of APIs to seamlessly link foundation models (FMs), Amazon Bedrock features, and AWS services to build and automate user-defined generative AI workflows at scale. Amazon Bedrock Agents offers a fully managed solution for creating, deploying, and scaling AI agents on AWS.
AWS offers a range of security services like AWS Security Hub, AWS GuardDuty, Amazon Inspector, Amazon Macie etc. This post will dive into how we can monitor these AWS Security services and build a layered security approach, emphasizing the importance of both prevention and detection.
The time taken to determine the root cause is referred to as mean time to detect (MTTD). The failed instance also needs to be isolated and terminated manually, either through the AWS Management Console , AWS Command Line Interface (AWS CLI), or tools like kubectl or eksctl.
At AWS, we are committed to developing AI responsibly , taking a people-centric approach that prioritizes education, science, and our customers, integrating responsible AI across the end-to-end AI lifecycle. For human-in-the-loop evaluation, which can be done by either AWS managed or customer managed teams, you must bring your own dataset.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content