This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Tecton.ai , the startup founded by three former Uber engineers who wanted to bring the machinelearning feature store idea to the masses, announced a $35 million Series B today, just seven months after announcing their $20 million Series A. “We help organizations put machinelearning into production.
Training a frontier model is highly compute-intensive, requiring a distributed system of hundreds, or thousands, of accelerated instances running for several weeks or months to complete a single job. For example, pre-training the Llama 3 70B model with 15 trillion training tokens took 6.5 During the training of Llama 3.1
Training large language models (LLMs) models has become a significant expense for businesses. PEFT is a set of techniques designed to adapt pre-trained LLMs to specific tasks while minimizing the number of parameters that need to be updated.
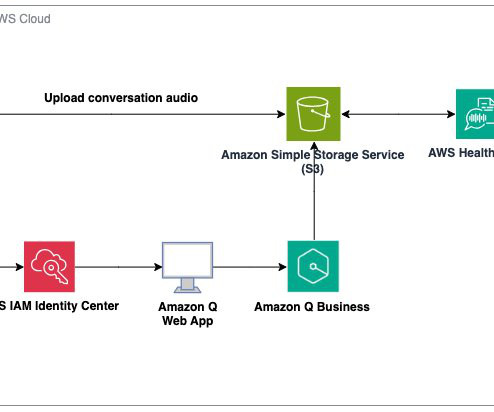
With the advent of generative AI and machinelearning, new opportunities for enhancement became available for different industries and processes. AWS HealthScribe combines speech recognition and generative AI trained specifically for healthcare documentation to accelerate clinical documentation and enhance the consultation experience.
Across diverse industries—including healthcare, finance, and marketing—organizations are now engaged in pre-training and fine-tuning these increasingly larger LLMs, which often boast billions of parameters and larger input sequence length. This approach reduces memory pressure and enables efficient training of large models.
Called OpenBioML , the endeavor’s first projects will focus on machinelearning-based approaches to DNA sequencing, protein folding and computational biochemistry. Stability AI’s ethically questionable decisions to date aside, machinelearning in medicine is a minefield. Predicting protein structures.
It also uses a number of other AWS services such as Amazon API Gateway , AWS Lambda , and Amazon SageMaker. You can use AWS services such as Application Load Balancer to implement this approach. API Gateway also provides a WebSocket API. These components are illustrated in the following diagram.
To achieve these goals, the AWS Well-Architected Framework provides comprehensive guidance for building and improving cloud architectures. This allows teams to focus more on implementing improvements and optimizing AWS infrastructure. This systematic approach leads to more reliable and standardized evaluations.
The Pro tier, however, would require a highly customized LLM that has been trained on specific data and terminology, enabling it to assist with intricate tasks like drafting complex legal documents. Before migrating any of the provided solutions to production, we recommend following the AWS Well-Architected Framework.
With the QnABot on AWS (QnABot), integrated with Microsoft Azure Entra ID access controls, Principal launched an intelligent self-service solution rooted in generative AI. Principal also used the AWS open source repository Lex Web UI to build a frontend chat interface with Principal branding.
At its re:Invent conference today, Amazon’s AWS cloud arm announced the launch of SageMaker HyperPod, a new purpose-built service for training and fine-tuning large language models (LLMs). SageMaker HyperPod is now generally available.
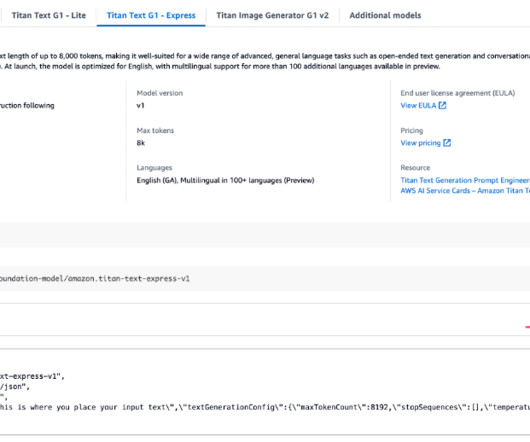
Exclusive to Amazon Bedrock, the Amazon Titan family of models incorporates 25 years of experience innovating with AI and machinelearning at Amazon. The AWS Command Line Interface (AWS CLI) installed on your machine to upload the dataset to Amazon S3. If enabled, its status will display as Access granted.
Were excited to announce the open source release of AWS MCP Servers for code assistants a suite of specialized Model Context Protocol (MCP) servers that bring Amazon Web Services (AWS) best practices directly to your development workflow. This post is the first in a series covering AWS MCP Servers.
Organizations are increasingly turning to cloud providers, like Amazon Web Services (AWS), to address these challenges and power their digital transformation initiatives. However, the vastness of AWS environments and the ease of spinning up new resources and services can lead to cloud sprawl and ongoing security risks.
These powerful models, trained on vast amounts of data, can generate human-like text, answer questions, and even engage in creative writing tasks. However, training and deploying such models from scratch is a complex and resource-intensive process, often requiring specialized expertise and significant computational resources.
At AWS re:Invent 2024, we are excited to introduce Amazon Bedrock Marketplace. Nemotron-4 15B, with its impressive 15-billion-parameter architecture trained on 8 trillion text tokens, brings powerful multilingual and coding capabilities to the Amazon Bedrock. About the authors James Park is a Solutions Architect at Amazon Web Services.
With the release of powerful publicly available foundation models, tools for training, fine tuning and hosting your own LLM have also become democratized. Using vLLM on AWS Trainium and Inferentia makes it possible to host LLMs for high performance inference and scalability. xlarge instances are only available in these AWS Regions.
With a shortage of IT workers with AI skills looming, Amazon Web Services (AWS) is offering two new certifications to help enterprises building AI applications on its platform to find the necessary talent. Candidates for this certification can sign up for an AWS Skill Builder subscription to check three new courses exploring various concepts.
As part of MMTech’s unifying strategy, Beswick chose to retire the data centers and form an “enterprisewide architecture organization” with a set of standards and base layers to develop applications and workloads that would run on the cloud, with AWS as the firm’s primary cloud provider.
Demystifying RAG and model customization RAG is a technique to enhance the capability of pre-trained models by allowing the model access to external domain-specific data sources. Unlike fine-tuning, in RAG, the model doesnt undergo any training and the model weights arent updated to learn the domain knowledge.
To help address the problem, he says, companies are doing a lot of outsourcing, depending on vendors and their client engagement engineers, or sending their own people to training programs. In the Randstad survey, for example, 35% of people have been offered AI training up from just 13% in last years survey.
Several LLMs are publicly available through APIs from OpenAI , Anthropic , AWS , and others, which give developers instant access to industry-leading models that are capable of performing most generalized tasks. Given some example data, LLMs can quickly learn new content that wasn’t available during the initial training of the base model.
We recommend referring to the Submit a model distillation job in Amazon Bedrock in the official AWS documentation for the most up-to-date and comprehensive information. Amazon Bedrock provides two primary methods for preparing your training data: uploading JSONL files to Amazon S3 or using historical invocation logs.
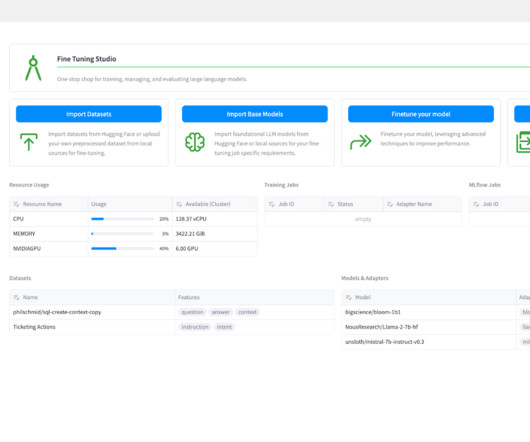
Tuning model architecture requires technical expertise, training and fine-tuning parameters, and managing distributed training infrastructure, among others. Its a familiar NeMo-style launcher with which you can choose a recipe and run it on your infrastructure of choice (SageMaker HyperPod or training). recipes=recipe-name.
As part of MMTech’s unifying strategy, Beswick chose to retire the data centers and form an “enterprisewide architecture organization” with a set of standards and base layers to develop applications and workloads that would run on the cloud, with AWS as the firm’s primary cloud provider.
At Data Reply and AWS, we are committed to helping organizations embrace the transformative opportunities generative AI presents, while fostering the safe, responsible, and trustworthy development of AI systems. These potential vulnerabilities could be exploited by adversaries through various threat vectors.
You can try these models with SageMaker JumpStart, a machinelearning (ML) hub that provides access to algorithms and models that can be deployed with one click for running inference. Both pre-trained base and instruction-tuned checkpoints are available under the Apache 2.0
… that is not an awful lot. Both the tech and the skills are there: MachineLearning technology is by now easy to use and widely available. So then let me re-iterate: why, still, are teams having troubles launching MachineLearning models into production? First let’s throw in a statistic. What a waste!
Our goal is to enable you to set up automated, optimal routing between large language models (LLMs) through Amazon Bedrock Intelligent Prompt Routing and its deep understanding of model behaviors within each model family, which incorporates state-of-the-art methods for training routers for different sets of models, tasks and prompts.
Its improved architecture, based on the Multimodal Diffusion Transformer (MMDiT), combines multiple pre-trained text encoders for enhanced text understanding and uses QK-normalization to improve training stability. Use the us-west-2 AWS Region to run this demo. An Amazon SageMaker domain. Access to Stability AIs SD3.5
The Education and Training Quality Authority (BQA) plays a critical role in improving the quality of education and training services in the Kingdom Bahrain. BQA oversees a comprehensive quality assurance process, which includes setting performance standards and conducting objective reviews of education and training institutions.
By doing this, clients and servers can scale independently, making it a great fit for serverless orchestration powered by Lambda, AWS Fargate for Amazon ECS, or Fargate for Amazon EKS. The dedicated MCP server in this example is running on a local Docker container, but it can be quickly deployed to the AWS Cloud using services like Fargate.
Today at AWS re:Invent 2024, we are excited to announce the new Container Caching capability in Amazon SageMaker, which significantly reduces the time required to scale generative AI models for inference. With its growing feature set, TorchServe is a popular choice for deploying and scaling machinelearning models among inference customers.
This engine uses artificial intelligence (AI) and machinelearning (ML) services and generative AI on AWS to extract transcripts, produce a summary, and provide a sentiment for the call. Organizations typically can’t predict their call patterns, so the solution relies on AWS serverless services to scale during busy times.
LoRA is a technique for efficiently adapting large pre-trained language models to new tasks or domains by introducing small trainable weight matrices, called adapters, within each linear layer of the pre-trained model. Why LoRAX for LoRA deployment on AWS? Two prominent approaches among our customers are LoRAX and vLLM.
At AWS, we are committed to developing AI responsibly , taking a people-centric approach that prioritizes education, science, and our customers, integrating responsible AI across the end-to-end AI lifecycle. For human-in-the-loop evaluation, which can be done by either AWS managed or customer managed teams, you must bring your own dataset.
Roughly a year ago, we wrote “ What machinelearning means for software development.” Karpathy suggests something radically different: with machinelearning, we can stop thinking of programming as writing a step of instructions in a programming language like C or Java or Python. Instead, we can program by example.
SAP is expanding its AI ecosystem with a partnership with AWS. The cloud hyperscalers AWS, Google and Microsoft are also important platform partners to operate SAP’s cloud applications. The cloud hyperscalers AWS, Google and Microsoft are also important platform partners to operate SAP’s cloud applications.
A generative pre-trained transformer (GPT) uses causal autoregressive updates to make prediction. Training LLMs requires colossal amount of compute time, which costs millions of dollars. Training LLMs requires colossal amount of compute time, which costs millions of dollars. We’ll outline how we cost-effectively (3.2
DeepSeek-R1 , developed by AI startup DeepSeek AI , is an advanced large language model (LLM) distinguished by its innovative, multi-stage training process. Instead of relying solely on traditional pre-training and fine-tuning, DeepSeek-R1 integrates reinforcement learning to achieve more refined outputs.
Llama2 by Meta is an example of an LLM offered by AWS. It comes in a range of parameter sizes—7 billion, 13 billion, and 70 billion—as well as pre-trained and fine-tuned variations. To learn more about Llama 2 on AWS, refer to Llama 2 foundation models from Meta are now available in Amazon SageMaker JumpStart.
Prerequisites To use this feature, make sure that you have satisfied the following requirements: An active AWS account. model customization is available in the US West (Oregon) AWS Region. Refer to Supported models and Regions for fine-tuning and continued pre-training for updates on Regional availability and quotas.
Fine-tuning is a powerful approach in natural language processing (NLP) and generative AI , allowing businesses to tailor pre-trained large language models (LLMs) for specific tasks. The TAT-QA dataset has been divided into train (28,832 rows), dev (3,632 rows), and test (3,572 rows).
It often requires managing multiple machinelearning (ML) models, designing complex workflows, and integrating diverse data sources into production-ready formats. Cross-Region inference enables seamless management of unplanned traffic bursts by using compute across different AWS Regions.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content