This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
With rapid progress in the fields of machinelearning (ML) and artificial intelligence (AI), it is important to deploy the AI/ML model efficiently in production environments. The architecture downstream ensures scalability, cost efficiency, and real-time access to applications.
Traditionally, building frontend and backend applications has required knowledge of web development frameworks and infrastructure management, which can be daunting for those with expertise primarily in data science and machinelearning. Choose the us-east-1 AWS Region from the top right corner. Choose Manage model access.
Refer to Supported Regions and models for batch inference for current supporting AWS Regions and models. To address this consideration and enhance your use of batch inference, we’ve developed a scalable solution using AWS Lambda and Amazon DynamoDB. It stores information such as job ID, status, creation time, and other metadata.
Semantic routing offers several advantages, such as efficiency gained through fast similarity search in vector databases, and scalability to accommodate a large number of task categories and downstream LLMs. Before migrating any of the provided solutions to production, we recommend following the AWS Well-Architected Framework.
Were excited to announce the open source release of AWS MCP Servers for code assistants a suite of specialized Model Context Protocol (MCP) servers that bring Amazon Web Services (AWS) best practices directly to your development workflow. This post is the first in a series covering AWS MCP Servers.
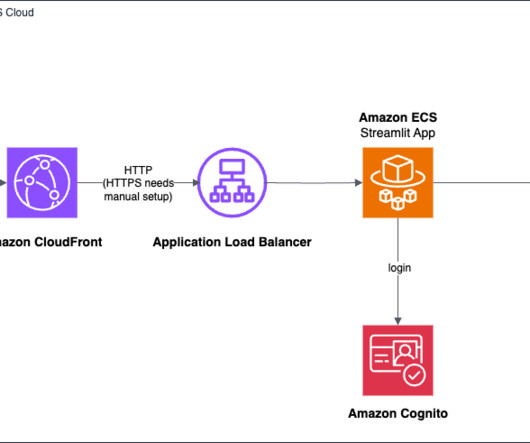
It also uses a number of other AWS services such as Amazon API Gateway , AWS Lambda , and Amazon SageMaker. You can use AWS services such as Application Load Balancer to implement this approach. API Gateway also provides a WebSocket API. These components are illustrated in the following diagram.
To achieve these goals, the AWS Well-Architected Framework provides comprehensive guidance for building and improving cloud architectures. This allows teams to focus more on implementing improvements and optimizing AWS infrastructure. This scalability allows for more frequent and comprehensive reviews.
With the QnABot on AWS (QnABot), integrated with Microsoft Azure Entra ID access controls, Principal launched an intelligent self-service solution rooted in generative AI. Principal also used the AWS open source repository Lex Web UI to build a frontend chat interface with Principal branding.
Organizations are increasingly turning to cloud providers, like Amazon Web Services (AWS), to address these challenges and power their digital transformation initiatives. However, the vastness of AWS environments and the ease of spinning up new resources and services can lead to cloud sprawl and ongoing security risks.
there is an increasing need for scalable, reliable, and cost-effective solutions to deploy and serve these models. AWS Trainium and AWS Inferentia based instances, combined with Amazon Elastic Kubernetes Service (Amazon EKS), provide a performant and low cost framework to run LLMs efficiently in a containerized environment.
At AWS re:Invent 2024, we are excited to introduce Amazon Bedrock Marketplace. Through Bedrock Marketplace, organizations can use Nemotron’s advanced capabilities while benefiting from the scalable infrastructure of AWS and NVIDIA’s robust technologies. You can find him on LinkedIn.
This post discusses how to use AWS Step Functions to efficiently coordinate multi-step generative AI workflows, such as parallelizing API calls to Amazon Bedrock to quickly gather answers to lists of submitted questions.
Without a scalable approach to controlling costs, organizations risk unbudgeted usage and cost overruns. Organizations can now label all Amazon Bedrock models with AWS cost allocation tags , aligning usage to specific organizational taxonomies such as cost centers, business units, and applications.
AWS App Studio is a generative AI-powered service that uses natural language to build business applications, empowering a new set of builders to create applications in minutes. Cross-instance Import and Export Enabling straightforward and self-service migration of App Studio applications across AWS Regions and AWS accounts.
Earlier this year, we published the first in a series of posts about how AWS is transforming our seller and customer journeys using generative AI. Field Advisor serves four primary use cases: AWS-specific knowledge search With Amazon Q Business, weve made internal data sources as well as public AWS content available in Field Advisors index.
Using vLLM on AWS Trainium and Inferentia makes it possible to host LLMs for high performance inference and scalability. Deploy vLLM on AWS Trainium and Inferentia EC2 instances In these sections, you will be guided through using vLLM on an AWS Inferentia EC2 instance to deploy Meta’s newest Llama 3.2 You will use inf2.xlarge
This engine uses artificial intelligence (AI) and machinelearning (ML) services and generative AI on AWS to extract transcripts, produce a summary, and provide a sentiment for the call. Organizations typically can’t predict their call patterns, so the solution relies on AWS serverless services to scale during busy times.
Solution overview To evaluate the effectiveness of RAG compared to model customization, we designed a comprehensive testing framework using a set of AWS-specific questions. Our study used Amazon Nova Micro and Amazon Nova Lite as baseline FMs and tested their performance across different configurations.
AI skills broadly include programming languages, database modeling, data analysis and visualization, machinelearning (ML), statistics, natural language processing (NLP), generative AI, and AI ethics. As one of the most sought-after skills on the market right now, organizations everywhere are eager to embrace AI as a business tool.
About the Authors Isha Dua is a Senior Solutions Architect based in the San Francisco Bay Area working with GENAI Model providers and helping customer optimize their GENAI workloads on AWS. She’s passionate about machinelearning technologies and environmental sustainability.
Today at AWS re:Invent 2024, we are excited to announce the new Container Caching capability in Amazon SageMaker, which significantly reduces the time required to scale generative AI models for inference. With its growing feature set, TorchServe is a popular choice for deploying and scaling machinelearning models among inference customers.
AI practitioners and industry leaders discussed these trends, shared best practices, and provided real-world use cases during EXLs recent virtual event, AI in Action: Driving the Shift to Scalable AI. And its modular architecture distributes tasks across multiple agents in parallel, increasing the speed and scalability of migrations.
Amazon Web Services (AWS) provides an expansive suite of tools to help developers build and manage serverless applications with ease. By abstracting the complexities of infrastructure, AWS enables teams to focus on innovation. Why Combine AI, ML, and Serverless Computing?
As part of MMTech’s unifying strategy, Beswick chose to retire the data centers and form an “enterprisewide architecture organization” with a set of standards and base layers to develop applications and workloads that would run on the cloud, with AWS as the firm’s primary cloud provider. The biggest challenge is data.
This solution uses decorators in your application code to capture and log metadata such as input prompts, output results, run time, and custom metadata, offering enhanced security, ease of use, flexibility, and integration with native AWS services.
The computer use agent demo powered by Amazon Bedrock Agents provides the following benefits: Secure execution environment Execution of computer use tools in a sandbox environment with limited access to the AWS ecosystem and the web. Prerequisites AWS Command Line Interface (CLI), follow instructions here. Require Python 3.11
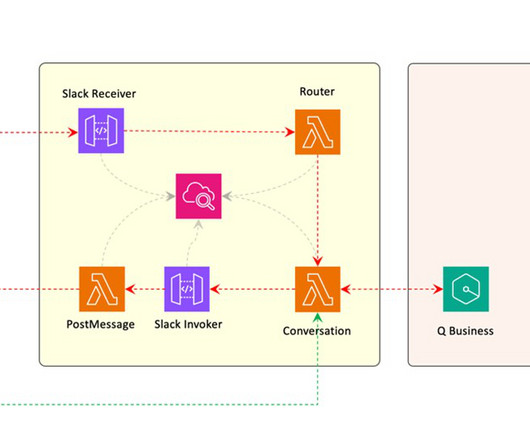
AWS offers powerful generative AI services , including Amazon Bedrock , which allows organizations to create tailored use cases such as AI chat-based assistants that give answers based on knowledge contained in the customers’ documents, and much more. The following figure illustrates the high-level design of the solution.
Amazon Bedrock cross-Region inference capability that provides organizations with flexibility to access foundation models (FMs) across AWS Regions while maintaining optimal performance and availability. We provide practical examples for both SCP modifications and AWS Control Tower implementations.
This is where AWS and generative AI can revolutionize the way we plan and prepare for our next adventure. This innovative service goes beyond traditional trip planning methods, offering real-time interaction through a chat-based interface and maintaining scalability, reliability, and data security through AWS native services.
As DPG Media grows, they need a more scalable way of capturing metadata that enhances the consumer experience on online video services and aids in understanding key content characteristics. Tom Lauwers is a machinelearning engineer on the video personalization team for DPG Media.
Use the us-west-2 AWS Region to run this demo. Prerequisites This notebook is designed to run on AWS, using Amazon Bedrock for both Anthropics Claude 3 Sonnet and Stability AI model access. Make sure you have the following set up before moving forward: An AWS account. An Amazon SageMaker domain. Access to Stability AIs SD3.5
The challenge: Enabling self-service cloud governance at scale Hearst undertook a comprehensive governance transformation for their Amazon Web Services (AWS) infrastructure. The CCoE implemented AWS Organizations across a substantial number of business units.
At Data Reply and AWS, we are committed to helping organizations embrace the transformative opportunities generative AI presents, while fostering the safe, responsible, and trustworthy development of AI systems. Post-authentication, users access the UI Layer, a gateway to the Red Teaming Playground built on AWS Amplify and React.
As part of MMTech’s unifying strategy, Beswick chose to retire the data centers and form an “enterprisewide architecture organization” with a set of standards and base layers to develop applications and workloads that would run on the cloud, with AWS as the firm’s primary cloud provider. The biggest challenge is data.
In this post, we explore how to deploy distilled versions of DeepSeek-R1 with Amazon Bedrock Custom Model Import, making them accessible to organizations looking to use state-of-the-art AI capabilities within the secure and scalableAWS infrastructure at an effective cost. You can monitor costs with AWS Cost Explorer.
It often requires managing multiple machinelearning (ML) models, designing complex workflows, and integrating diverse data sources into production-ready formats. With Amazon Bedrock Data Automation, enterprises can accelerate AI adoption and develop solutions that are secure, scalable, and responsible.
With this launch, you can now access Mistrals frontier-class multimodal model to build, experiment, and responsibly scale your generative AI ideas on AWS. AWS is the first major cloud provider to deliver Pixtral Large as a fully managed, serverless model. Take a look at the Mistral-on-AWS repo.
Prerequisites To perform this solution, complete the following: Create and activate an AWS account. Make sure your AWS credentials are configured correctly. This tutorial assumes you have the necessary AWS Identity and Access Management (IAM) permissions. or later on your local machine. Install Python 3.7
Over the last 18 months, AWS has announced more than twice as many machinelearning (ML) and generative artificial intelligence (AI) features into general availability than the other major cloud providers combined. The following figure highlights where AWS lands in the DSML Magic Quadrant.
Developer tools The solution also uses the following developer tools: AWS Powertools for Lambda – This is a suite of utilities for Lambda functions that generates OpenAPI schemas from your Lambda function code. After deployment, the AWS CDK CLI will output the web application URL. Python 3.9 or later Node.js
The collaboration between BQA and AWS was facilitated through the Cloud Innovation Center (CIC) program, a joint initiative by AWS, Tamkeen , and leading universities in Bahrain, including Bahrain Polytechnic and University of Bahrain. The extracted text data is placed into another SQS queue for the next processing step.
These recipes include a training stack validated by Amazon Web Services (AWS) , which removes the tedious work of experimenting with different model configurations, minimizing the time it takes for iterative evaluation and testing. You can run these recipes using SageMaker HyperPod or as SageMaker training jobs.
Large organizations often have many business units with multiple lines of business (LOBs), with a central governing entity, and typically use AWS Organizations with an Amazon Web Services (AWS) multi-account strategy. LOBs have autonomy over their AI workflows, models, and data within their respective AWS accounts.
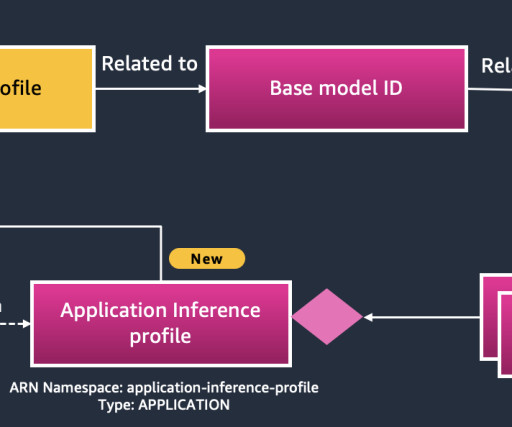
Amazon SageMaker AI provides a managed way to deploy TGI-optimized models, offering deep integration with Hugging Faces inference stack for scalable and cost-efficient LLM deployment. GenAI Data Scientist at AWS. Model Base Model Download DeepSeek-R1-Distill-Qwen-1.5B deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















































Let's personalize your content