This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
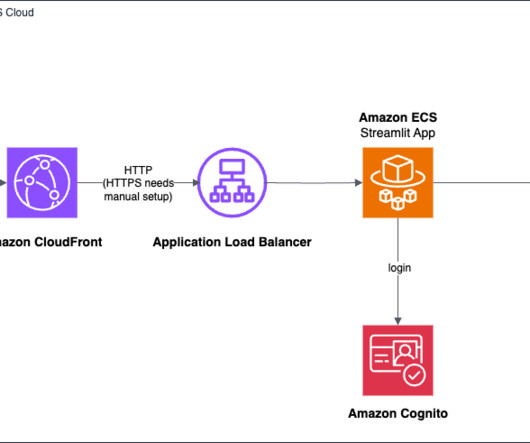
AWS provides a powerful set of tools and services that simplify the process of building and deploying generative AI applications, even for those with limited experience in frontend and backend development. The AWS deployment architecture makes sure the Python application is hosted and accessible from the internet to authenticated users.
Region Evacuation with static anycast IP approach Welcome back to our comprehensive "Building Resilient Public Networking on AWS" blog series, where we delve into advanced networking strategies for regional evacuation, failover, and robust disaster recovery. Find the detailed guide here.
AWS Trainium and AWS Inferentia based instances, combined with Amazon Elastic Kubernetes Service (Amazon EKS), provide a performant and low cost framework to run LLMs efficiently in a containerized environment. Adjust the following configuration to suit your needs, such as the Amazon EKS version, cluster name, and AWS Region.
It also uses a number of other AWS services such as Amazon API Gateway , AWS Lambda , and Amazon SageMaker. It also uses a number of other AWS services such as Amazon API Gateway , AWS Lambda , and Amazon SageMaker. You can use AWS services such as Application LoadBalancer to implement this approach.
The just-announced general availability of the integration between VM-Series virtual firewalls and the new AWS Gateway LoadBalancer (GWLB) introduces customers to massive security scaling and performance acceleration – while bypassing the awkward complexities traditionally associated with inserting virtual appliances in public cloud environments.
Cloud loadbalancing is the process of distributing workloads and computing resources within a cloud environment. Cloud loadbalancing also involves hosting the distribution of workload traffic within the internet. Cloud loadbalancing also involves hosting the distribution of workload traffic within the internet.
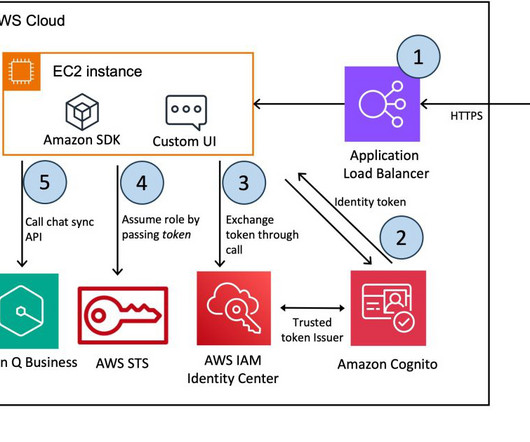
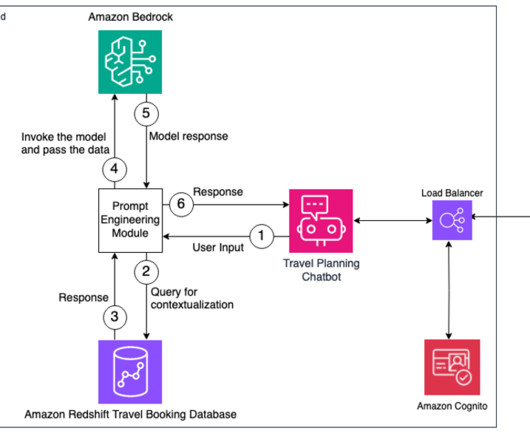
AWS offers powerful generative AI services , including Amazon Bedrock , which allows organizations to create tailored use cases such as AI chat-based assistants that give answers based on knowledge contained in the customers’ documents, and much more. The following figure illustrates the high-level design of the solution.
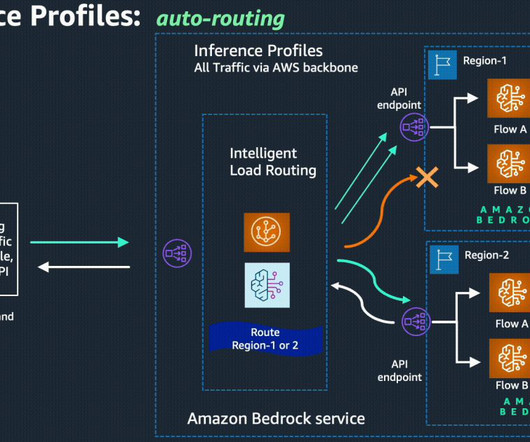
We discuss the unique challenges MaestroQA overcame and how they use AWS to build new features, drive customer insights, and improve operational inefficiencies. Cross-Region inference dynamically routes traffic across multiple Regions, providing optimal availability for each request and smoother performance during these high-usage periods.
Deploy Secure Public Web Endpoints Welcome to Building Resilient Public Networking on AWS—our comprehensive blog series on advanced networking strategies tailored for regional evacuation, failover, and robust disaster recovery. We laid the groundwork for understanding the essentials that underpin the forthcoming discussions.
The following figure illustrates the performance of DeepSeek-R1 compared to other state-of-the-art models on standard benchmark tests, such as MATH-500 , MMLU , and more. SM_NUM_GPUS : This parameter specifies the number of GPUs to use for model inference, allowing the model to be sharded across multiple GPUs for improved performance.
In this article, we will discuss the advantages of using AWS and Terraform and provide an example of this collaboration for better understanding. Here are some key advantages of using AWS with Terraform:
For medium to large businesses with outdated systems or on-premises infrastructure, transitioning to AWS can revolutionize their IT operations and enhance their capacity to respond to evolving market needs. AWS migration isnt just about moving data; it requires careful planning and execution. Need to hire skilled engineers?
This would cache the content closer to your users, making sure that your users have the best performance. AWS has a service called Cognito that allows you to manage a pool of users. I am using an Application LoadBalancer to invoke a Lambda function. The loadbalancer will now invoke the target group with the request.
Amazon Elastic Container Service (ECS): It is a highly scalable, high-performance container management service that supports Docker containers and allows to run applications easily on a managed cluster of Amazon EC2 instances. Before that let’s create a loadbalancer by performing the following steps.
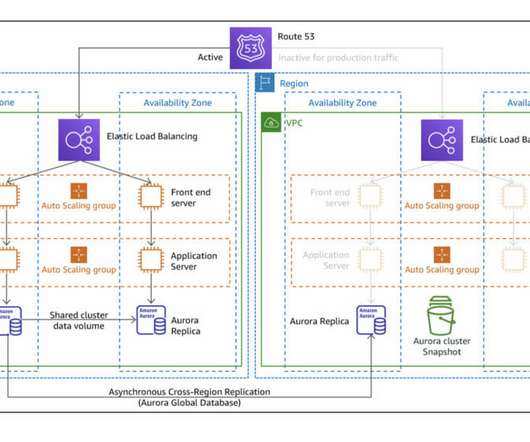
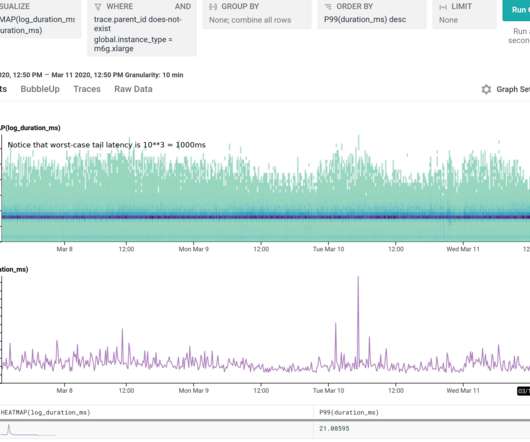
A regional failure is an uncommon event in AWS (and other Public Cloud providers), where all Availability Zones (AZs) within a region are affected by any condition that impedes the correct functioning of the provisioned Cloud infrastructure. For demonstration purposes, we are using HTTP instead of HTTPS. Pilot Light strategy diagram.
In addition, you can also take advantage of the reliability of multiple cloud data centers as well as responsive and customizable loadbalancing that evolves with your changing demands. In this blog, we’ll compare the three leading public cloud providers, namely Amazon Web Services (AWS), Microsoft Azure and Google Cloud.
We demonstrate how to build an end-to-end RAG application using Cohere’s language models through Amazon Bedrock and a Weaviate vector database on AWS Marketplace. This is done by generating the vector embeddings of the user query with an embedding model to perform a vector search to retrieve the most relevant context from the database.
On March 25, 2021, between 14:39 UTC and 18:46 UTC we had a significant outage that caused around 5% of our global traffic to stop being served from one of several loadbalancers and disrupted service for a portion of our customers. At 18:46 UTC we restored all traffic remaining on the Google loadbalancer. What happened.
AWS account - Amazon Web Services provides on-demand computing platforms. Note: The infrastructure we are going to build will involve a small cost in standing up the AWS services we require. Create an AWS account & credentials. First, we need to sign up for an AWS account. AWS infrastructure using Terraform.
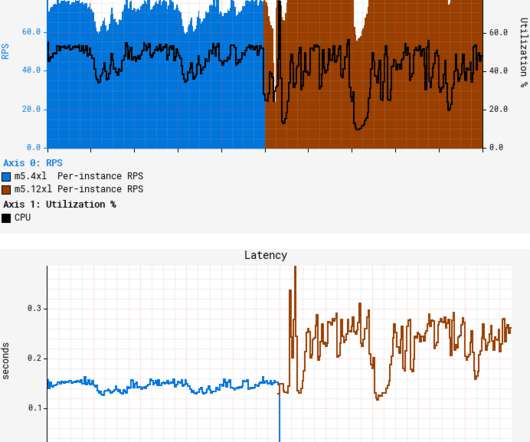
to a larger AWS instance size, from m5.4xl (16 vCPUs) to m5.12xl (48 vCPUs). As GS2 relies on AWS EC2 Auto Scaling to target-track CPU utilization, we thought we just had to redeploy the service on the larger instance type and wait for the ASG (Auto Scaling Group) to settle on the CPU target. let’s call it GS2?—?to
The workflow includes the following steps: The user accesses the chatbot application, which is hosted behind an Application LoadBalancer. For more information about trusted token issuers and how token exchanges are performed, see Using applications with a trusted token issuer. A VPC where you will deploy the solution.
Other services, such as Cloud Run, Cloud Bigtable, Cloud MemCache, Apigee, Cloud Redis, Cloud Spanner, Extreme PD, Cloud LoadBalancer, Cloud Interconnect, BigQuery, Cloud Dataflow, Cloud Dataproc, Pub/Sub, are expected to be made available within six months of the launch of the region.
Optimizing the performance of PeopleSoft enterprise applications is crucial for empowering businesses to unlock the various benefits of Amazon Web Services (AWS) infrastructure effectively. Research indicates that AWS has approximately five times more deployed cloud infrastructure than their next 14 competitors.
Currently, users might have to engineer their applications to handle scenarios involving traffic spikes that can use service quotas from multiple regions by implementing complex techniques such as client-side loadbalancing between AWS regions, where Amazon Bedrock service is supported.
With the advancements being made with LLMs like the Mixtral-8x7B Instruct , derivative of architectures such as the mixture of experts (MoE) , customers are continuously looking for ways to improve the performance and accuracy of generative AI applications while allowing them to effectively use a wider range of closed and open source models.
Creating and configuring Secure AWS RDS Instances with a Reader and Backup Solution. In this live AWS environment, you will learn how to create an RDS database, then successfully implement a read replica and backups for that database. Elastic Compute Cloud (EC2) is AWS’s Infrastructure as a Service product.
Try Render Vercel Earlier known as Zeit, the Vercel app acts as the top layer of AWS Lambda which will make running your applications easy. This is the serverless wrapper made on top of AWS. AWS is a cloud-based server that doesn’t offer hosting with the physical server but uses the virtual server. services for free.
AWS Trusted Advisor is a service that helps you understand if you are using your AWS services well. It does this by looking at 72 different best practices across 5 total categories, which include Cost Optimization, Performance, Security, Fault Tolerance, and Service Limits. LoadBalancers – idle LBs.
With AWS generative AI services like Amazon Bedrock , developers can create systems that expertly manage and respond to user requests. An AI assistant is an intelligent system that understands natural language queries and interacts with various tools, data sources, and APIs to perform tasks or retrieve information on behalf of the user.
In this post, we demonstrate a solution using Amazon FSx for NetApp ONTAP with Amazon Bedrock to provide a RAG experience for your generative AI applications on AWS by bringing company-specific, unstructured user file data to Amazon Bedrock in a straightforward, fast, and secure way. Install the AWS Command Line Interface (AWS CLI).
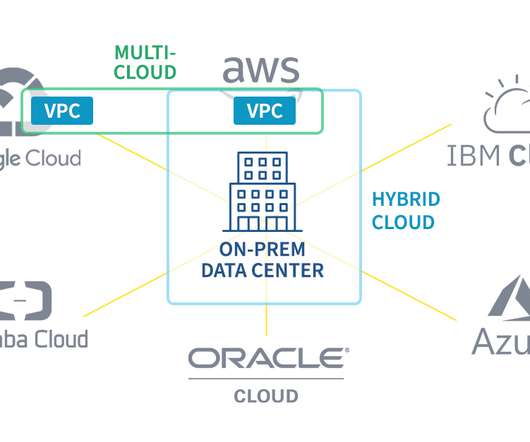
The public clouds (representing Google, AWS, IBM, Azure, Alibaba and Oracle) are all readily available. Outlined in light blue is the hybrid cloud which includes the on-premises network, as well as the virtual public cloud (VPC) in the AWS public cloud. Moving to the cloud can also increase performance. Multi-cloud Benefits.
Behind the scenes, OneFootball runs on a sophisticated, high-scale infrastructure hosted on AWS and distributed across multiple AWS zones under the same region. This mission led them to Honeycomb, setting the stage for a transformative journey in how they approach reliability and performance at scale.
QA engineers: Test functionality, security, and performance to deliver a high-quality SaaS platform. DevOps engineers: Optimize infrastructure, manage deployment pipelines, monitor security and performance. The team works towards improved performance and the integration of new functionality.
This allows SageMaker Studio users to perform petabyte-scale interactive data preparation, exploration, and machine learning (ML) directly within their familiar Studio notebooks, without the need to manage the underlying compute infrastructure. This same interface is also used for provisioning EMR clusters.
As many of you may have read, Amazon has released C7g instances powered by the highly anticipated AWS Graviton3 Processors. As we shared at re:Invent 2021 , we had the chance to take a little sneak peek under the Graviton3 hood to find out what even more performance will mean for Honeycomb and our customers. Reservations[]|.Instances[]'
It is part of the Cloudera Data Platform, or CDP , which runs on Azure and AWS, as well as in the private cloud. ensure your SLAs are met – via compute isolation, autoscaling, and performance optimizations. ensure your SLAs are met – via compute isolation, autoscaling, and performance optimizations. Network Security.
It’s on the hot path of every user request, and because of this, it needs to be performant, secure, and easily configurable. DORA metrics are used by DevOps teams to measure their performance and find out whether they are “low performers” to “elite performers.” What is an API gateway?
AWS re:Invent 2019 is now firmly in the rearview mirror, and we’re already looking forward to 2020. This year was no different—so it’s time to take a look at what we’ve learned from AWS re:Invent 2019. This year was no different—so it’s time to take a look at what we’ve learned from AWS re:Invent 2019.
At re:Invent in December, Amazon announced the AWS Graviton2 processor and its forthcoming availability powering Amazon EC2 M6g instances. For our initial test, we chose to trial migrating a subset of the shepherd workload as it’s stateless, performance-critical, and scales out horizontally. Some architectural context.
Webex works with the world’s leading business and productivity apps—including AWS. To optimize its AI/ML infrastructure, Cisco migrated its LLMs to Amazon SageMaker Inference , improving speed, scalability, and price-performance. The following diagram illustrates the WxAI architecture on AWS.
R&D Server Once the microservices project is ready, it will be deployed in a cloud environment like AWS/Azure/Google Cloud, etc., LoadBalancer Client If any microservice has more demand, then we allow the creation of multiple instances dynamically.
Amazon Bedrock offers a choice of high-performing foundation models from leading AI companies, including AI21 Labs, Anthropic, Cohere, Meta, Stability AI, and Amazon, via a single API. First, the user logs in to the chatbot application, which is hosted behind an Application LoadBalancer and authenticated using Amazon Cognito.
Terraform is similar to configuration tools provided by cloud platforms such as AWS CloudFormation or Azure Resource Manager , but it has the advantage of being provider-agnostic. If you’re not familiar with Terraform, we recommend that you first go through their getting started with AWS guide to learn the most important concepts.
AWS Elastic Beanstalk offers a powerful and user-friendly platform to streamline this process, allowing you to focus on writing code rather than managing infrastructure. In this blog, we’ll explore AWS Elastic Beanstalk, its key features, and how to deploy a web application using this robust service.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content