This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
AWS Trainium and AWS Inferentia based instances, combined with Amazon Elastic Kubernetes Service (Amazon EKS), provide a performant and low cost framework to run LLMs efficiently in a containerized environment. Adjust the following configuration to suit your needs, such as the Amazon EKS version, cluster name, and AWS Region.
But they share a common bottleneck: hardware. New techniques and chips designed to accelerate certain aspects of AI system development promise to (and, indeed, already have) cut hardware requirements. Emerging from stealth today, Exafunction is developing a platform to abstract away the complexity of using hardware to train AI systems.
As cluster sizes grow, the likelihood of failure increases due to the number of hardware components involved. Each hardware failure can result in wasted GPU hours and requires valuable engineering time to identify and resolve the issue, making the system prone to downtime that can disrupt progress and delay completion.
Using vLLM on AWS Trainium and Inferentia makes it possible to host LLMs for high performance inference and scalability. Deploy vLLM on AWS Trainium and Inferentia EC2 instances In these sections, you will be guided through using vLLM on an AWS Inferentia EC2 instance to deploy Meta’s newest Llama 3.2 You will use inf2.xlarge
In continuation of its efforts to help enterprises migrate to the cloud, Oracle said it is partnering with Amazon Web Services (AWS) to offer database services on the latter’s infrastructure. Oracle Database@AWS is expected to be available in preview later in the year with broader availability expected in 2025.
of a red apple Practical settings for optimal results To optimize the performance for these models, several key settings should be adjusted based on user preferences and hardware capabilities. A photo of a (red:1.2) apple A (photorealistic:1.4) (3D render:1.2) Start with 28 denoising steps to balance image quality and generation time.
Although many customers focus on optimizing the technology stack behind the FM inference endpoint through techniques such as model optimization , hardware acceleration, and semantic caching to reduce the TTFT, they often overlook the significant impact of network latency. Next, create a subnet inside each Local Zone.
Audio startup Syng has been building on quite a bit more hype than the average fresh hardware startup, largely because of the team behind it. The company has now raised $50 million to date to build out an audio hardware startup with a hefty focus on design and advanced tech.
Ironwood brings performance gains for large AI workloads, but just as importantly, it reflects Googles move to reduce its dependency on Nvidia, a shift that matters as CIOs grapple with hardware supply issues and rising GPU costs.
million/year on AWS S3 at the moment to host files for Basecamp , HEY , and everything else. Pure Storage comes with an S3-compatible API, so no need for CEPH, Minio, or any of the other object storage software solutions you might need, if you were trying to do this exercise on commodity hardware. We're spending just shy of $1.5
AWS Amazon Web Services (AWS) es la plataforma de nube ms utilizada en la actualidad. Las habilidades de AWS son fundamentales para las estrategias de nube en casi todas las industrias y tienen una gran demanda, ya que las organizaciones buscan aprovechar al mximo la amplia gama de ofertas de la plataforma.
Around a year ago, TechCrunch wrote about a little-known company developing AI-accelerating chips to face off against hardware from titans of industry — e.g. Nvidia, AMD, Microsoft, Meta, AWS and Intel. Its mission at the time sounded a little ambitious — and still does.
” Long before the team had working hardware, though, the company focused on building its compiler to ensure that its solution could actually address its customers’ needs. With this, the compiler can then look at the model and figure out how to best map it on the hardware to optimize for data flow and minimize data movement.
Here's a theory I have about cloud vendors (AWS, Azure, GCP): Cloud vendors 1 will increasingly focus on the lowest layers in the stack: basically leasing capacity in their data centers through an API. Redshift is a data warehouse (aka OLAP database) offered by AWS. If you're an ambitious person, do you go work at AWS?
How does High-Performance Computing on AWS differ from regular computing? Today’s server hardware is powerful enough to execute most compute tasks. HPC services on AWS Compute Technically you could design and build your own HPC cluster on AWS, it will work but you will spend time on plumbing and undifferentiated heavy lifting.
AWS or other providers? The Capgemini-AWS partnership journey Capgemini has spent the last 15 years partnering with AWS to answer these types of questions. Our journey has evolved from basic cloud migrations to cutting-edge AI implementations, earning us recognition as AWS’s Global AI/ML Partner of the Year for 2023.
At AWS, our top priority is safeguarding the security and confidentiality of our customers’ workloads. With the AWS Nitro System , we delivered a first-of-its-kind innovation on behalf of our customers. The Nitro System is an unparalleled computing backbone for AWS, with security and performance at its core.
In this post, we explore how to deploy distilled versions of DeepSeek-R1 with Amazon Bedrock Custom Model Import, making them accessible to organizations looking to use state-of-the-art AI capabilities within the secure and scalable AWS infrastructure at an effective cost. You can monitor costs with AWS Cost Explorer.
AI services require high resources like CPU/GPU and memory and hence cloud providers like Amazon AWS, Microsoft Azure and Google Cloud provide many AI services including features for genAI. Specialized hardware AI services often rely on specialized hardware, such as GPUs and TPUs, which can be expensive.
Our cloud strategy was to use a single cloud provider for our enterprise cloud platform AWS. This included both the hardware cost, the operational staff required to support the solution and the cost of building the features. Time to market. How long does it take to develop comparable features on our new ecosystem compared to legacy.
We discuss the unique challenges MaestroQA overcame and how they use AWS to build new features, drive customer insights, and improve operational inefficiencies. Its serverless architecture allowed the team to rapidly prototype and refine their application without the burden of managing complex hardware infrastructure.
The first week of August was dedicated to re:Inforce, a two-day annual AWS conference where security and encryption announcements take the stage. Kurt Kufeld, Vice President Platform AWS, closed the first keynote with three AWS encryption calls to action. Encrypt everything . Enable Multi-Factor Authentication. Concluding.
This week in AWS is dedicated to re:Inforce, a two-day annual conference where security and encryption announcements take the stage. Kurt Kufeld, Vice President Platform AWS, closed the first keynote with three AWS encryption calls to action. The post Three Calls To Action for Encryption On AWS appeared first on Xebia.
Revenue for AWS increased 12% year-on-year in the second quarter to $21.4 However, Amazon CEO Andy Jassy said enterprises subscribing to AWS services have “needed assistance cost optimizing to withstand this challenging time.” Revenue growth for AWS continued to be on a constant decline. and 33% respectively.
Namely, these layers are: perception layer (hardware components such as sensors, actuators, and devices; transport layer (networks and gateway); processing layer (middleware or IoT platforms); application layer (software solutions for end users). Perception layer: IoT hardware. AWS IoT Platform: the best place to build smart cities.
In this blog post, we examine the relative costs of different language runtimes on AWS Lambda. Many languages can be used with AWS Lambda today, so we focus on four interesting ones. Rust just came to AWS Lambda in November 2023 , so probably a lot of folks are wondering whether to try it out. We choose Rust.
Today at AWS re:Invent 2024, we are excited to announce the new Container Caching capability in Amazon SageMaker, which significantly reduces the time required to scale generative AI models for inference. His primary focus is on delivering secure, high-performance, and user-friendly machine learning features for AWS customers.
Traditional model serving approaches can become unwieldy and resource-intensive, leading to increased infrastructure costs, operational overhead, and potential performance bottlenecks, due to the size and hardware requirements to maintain a high-performing FM. Why LoRAX for LoRA deployment on AWS?
Two years ago, we shared our experiences with adopting AWS Graviton3 and our enthusiasm for the future of AWS Graviton and Arm. Once again, we’re privileged to share our experiences as a launch customer of the Amazon EC2 R8g instances powered by AWS Graviton4, the newest generation of AWS Graviton processors.
Picture this scenario as a young enterprise: You are a customer of Azure, AWS, or the Google Cloud Platform, assuming they are the frontrunners. Ideally, the software and hardware that implement the API should also be open source. Use of hardware without being able to audit its design poses a risk of logistics attacks.
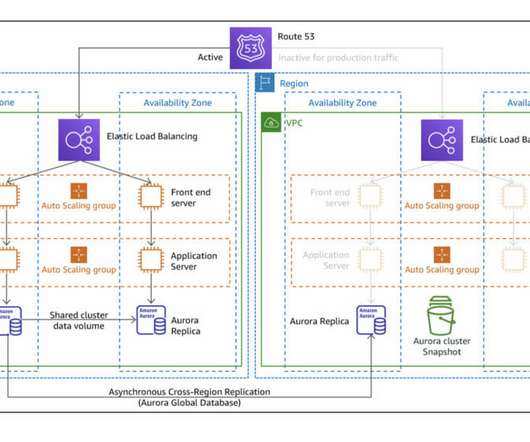
A regional failure is an uncommon event in AWS (and other Public Cloud providers), where all Availability Zones (AZs) within a region are affected by any condition that impedes the correct functioning of the provisioned Cloud infrastructure. For demonstration purposes, we are using HTTP instead of HTTPS. Pilot Light strategy diagram.
There are additional optional runtime parameters that are already pre-optimized in TGI containers to maximize performance on host hardware. We didnt try to optimize the performance for each model/hardware/use case combination. GenAI Data Scientist at AWS. Model Base Model Download DeepSeek-R1-Distill-Qwen-1.5B
Venturo, a hobbyist Ethereum miner, cheaply acquired GPUs from insolvent cryptocurrency mining farms, choosing Nvidia hardware for the increased memory (hence Nvidia’s investment in CoreWeave, presumably). For perspective, AWS made $80.1 Initially, CoreWeave was focused exclusively on cryptocurrency applications. billion and $26.28
Looking back to 2021, when Anthropic first started building on AWS, no one could have envisioned how transformative the Claude family of models would be. In addition, proprietary data is never exposed to the public internet, never leaves the AWS network, is securely transferred through VPC, and is encrypted in transit and at rest.
Back in 2014, to pick one example, Amazon’s AWS cut its prices in response to Google’s recently launched competing service. Sure, AWS is still top dog, with Microsoft and Google working to both snag share from the leader (and one another). — mentioned some more modest cases where it may use its own hardware instead of public cloud services.
In a public cloud, all of the hardware, software, networking and storage infrastructure is owned and managed by the cloud service provider. In this blog, we’ll compare the three leading public cloud providers, namely Amazon Web Services (AWS), Microsoft Azure and Google Cloud. Amazon Web Services (AWS) Overview.
Launching a machine learning (ML) training cluster with Amazon SageMaker training jobs is a seamless process that begins with a straightforward API call, AWS Command Line Interface (AWS CLI) command, or AWS SDK interaction. About the Authors Kanwaljit Khurmi is a Principal Worldwide Generative AI Solutions Architect at AWS.
Llama2 by Meta is an example of an LLM offered by AWS. To learn more about Llama 2 on AWS, refer to Llama 2 foundation models from Meta are now available in Amazon SageMaker JumpStart. Virginia) and US West (Oregon) AWS Regions, and most recently announced general availability in the US East (Ohio) Region.
In this post, we showcase fine-tuning a Llama 2 model using a Parameter-Efficient Fine-Tuning (PEFT) method and deploy the fine-tuned model on AWS Inferentia2. We use the AWS Neuron software development kit (SDK) to access the AWS Inferentia2 device and benefit from its high performance.
Alchemist has also continued to grow AlchemistX , a program in which Alchemist helps companies like LG, Siemens, and NEC build accelerators of their own; today it announced 10 companies selected into a space-focused accelerator built in partnership with Amazon’s AWS. Pitches are scheduled to start at 10:30 a.m.
The NFL ‘s Philadelphia Eagles switched to a specialized cloud storage provider because it worked with their existing systems and cost just one-fifth the price of legacy cloud providers such as AWS. The big three providers AWS, Google and Microsoft have come under fire by regulators for their vendor lock-in approaches.
We’re getting back into this frenetic spend mode that we saw in the early days of cloud,” observed James Greenfield, vice president of AWS Commerce Platform, at the FinOps X conference in San Diego in June. Storment, executive director of the FinOps Foundation, echoed the concern.
In this post, we’ll summarize training procedure of GPT NeoX on AWS Trainium , a purpose-built machine learning (ML) accelerator optimized for deep learning training. M tokens/$) trained such models with AWS Trainium without losing any model quality. We’ll outline how we cost-effectively (3.2 billion in Pythia. 2048 256 10.4
Generative AI with AWS The emergence of FMs is creating both opportunities and challenges for organizations looking to use these technologies. Beyond hardware, data cleaning and processing, model architecture design, hyperparameter tuning, and training pipeline development demand specialized machine learning (ML) skills.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















































Let's personalize your content