This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Recognizing this need, we have developed a Chrome extension that harnesses the power of AWS AI and generative AI services, including Amazon Bedrock , an AWS managed service to build and scale generative AI applications with foundation models (FMs). The user signs in by entering a user name and a password.
This post discusses how to use AWS Step Functions to efficiently coordinate multi-step generative AI workflows, such as parallelizing API calls to Amazon Bedrock to quickly gather answers to lists of submitted questions.
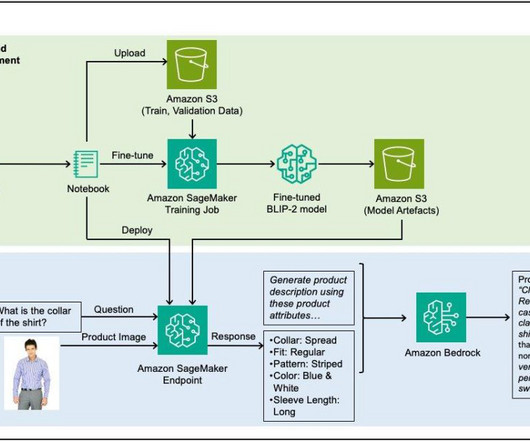
To solve this problem, this post shows you how to predict domain-specific product attributes from product images by fine-tuning a VLM on a fashion dataset using Amazon SageMaker , and then using Amazon Bedrock to generate product descriptions using the predicted attributes as input. For details, see Creating an AWS account.
For example, in the fashion retail industry, an assistant powered by agents and multimodal models can provide customers with a personalized and immersive experience. In this post, we implement a fashion assistant agent using Amazon Bedrock Agents and the Amazon Titan family models.
Many customers, including those in creative advertising, media and entertainment, ecommerce, and fashion, often need to change the background in a large number of images. However, Amazon Bedrock and AWS Step Functions make it straightforward to automate this process at scale. Invokes the Amazon Bedrock InvokeModel API action.
There are also newer AI/ML applications that need data storage, optimized for unstructured data using developer friendly paradigms like Python Boto API. Apache Ozone caters to both these storage use cases across a wide variety of industry verticals, some of which include: . Diversity of workloads. release version.
by Shefali Vyas Dalal AWS re:Invent is a couple weeks away and our engineers & leaders are thrilled to be in attendance yet again this year! To sustain this data growth at Netflix, it has deployed open-source software Ceph using AWS services to achieve the required SLOs of some of the post-production workflows.
virtual machine, container, microservice, application, storage, or cloud resource) used either as needed or in an always-on fashion to complete a specific task; for example, AWS S3. A workload is any specific service (e.g., Much like users, they need to be granted secure access to both applications and the internet.
Use natural language in your Amazon Q web experience chat to perform read and write actions in ServiceNow such as querying and creating incidents and KB articles in a secure and governed fashion. AWS Have an AWS account with administrative access. For more information, see Setting up for Amazon Q Business. Choose Create.
This solution is available in the AWS Solutions Library. AWS Lambda – AWS Lambda provides serverless compute for processing. Note that in this solution, all of the storage is in the UI. Amazon API Gateway passes the request to AWS Lambda through a proxy integration. This could be any database of your choice.
Cloud-native consumption model that leverages elastic compute to align consumption of compute resources with usage, in addition to offering cost-effective object storage that reduces data costs on a GB / month basis when compared to compute-attached storage used currently by Apache HBase implementations. Savings opportunity on AWS.
At Confluent, we see many of our customers are on AWS, and we’ve noticed that Amazon S3 plays a particularly significant role in AWS-based architectures. Unless a use case actively requires a specific database, companies use S3 for storage and process the data with Amazon Elastic MapReduce (EMR) or Amazon Athena.
Pre-AWS services had been deployed inside of Amazon that allowed for developers to “order up” compute, storage, networking, messaging, and the like. Much of this work is what inspired Amazon Web Services (AWS) and also the tooling work developed around “DevOps” and rapid CI/CD release pipelines. x after they were deprecated.[1]
Prior the introduction of CDP Public Cloud, many organizations that wanted to leverage CDH, HDP or any other on-prem Hadoop runtime in the public cloud had to deploy the platform in a lift-and-shift fashion, commonly known as “Hadoop-on-IaaS” or simply the IaaS model. Storage costs. 13,000-18,500. 7,500-11,500. 8,500-14,500.
This will be a blend of private and public hyperscale clouds like AWS, Azure, and Google Cloud Platform. They are a Premier Consulting Partner in the Amazon Web Services (AWS) Partner Network (APN) and a Microsoft Azure Silver Partner. REAN Cloud has expertise working with the hyperscale public clouds.
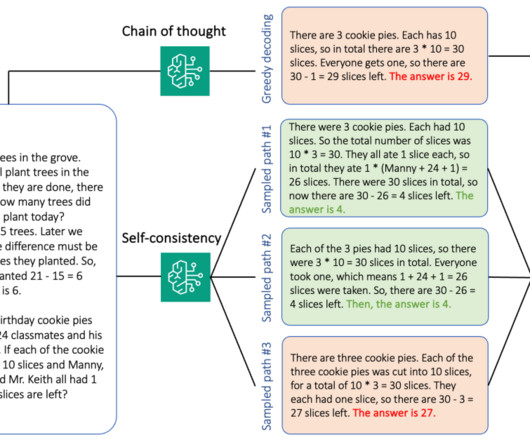
Another is to expose the model to exemplars of intermediate reasoning steps in few-shot prompting fashion. For multiple-choice reasoning, we prompt AI21 Labs Jurassic-2 Mid on a small sample of questions from the AWS Certified Solutions Architect – Associate exam. Both scenarios typically use greedy decoding. Lambda function B.
by Shefali Vyas Dalal AWS re:Invent is a couple weeks away and our engineers & leaders are thrilled to be in attendance yet again this year! To sustain this data growth at Netflix, it has deployed open-source software Ceph using AWS services to achieve the required SLOs of some of the post-production workflows.
by Shefali Vyas Dalal AWS re:Invent is a couple weeks away and our engineers & leaders are thrilled to be in attendance yet again this year! To sustain this data growth at Netflix, it has deployed open-source software Ceph using AWS services to achieve the required SLOs of some of the post-production workflows.
You don’t have to manage servers to run apps, storage systems, or databases at any scale. In the AWS world, the go-to options for solving this issue would be DyanamoDB or Aurora Serverless. Since it was an isolated feature, we created a separate Lambda function for it on AWS. Are you comfortable with higher OpEx for lower CapEx?
XetHub is “ a collaborative storage platform for managing data at scale.” AWS Clean Rooms are a new service that allows organizations to cooperate on data analysis without revealing the underlying data to each other. Fashion may be the Metaverse’s first killer app. Essentially, it’s GitHub for data.
Given that it is at a relatively early stage, developers are still trying to grok the best approach for each cloud vendor and often face the following question: Should I go cloud native with AWS Lambda, GCP functions, etc., The more recent developments around AWS Step Functions and Azure Durable Functions (patterns) reveal future direction.
If Apple can’t make technology into a fashion statement, no one can. The Solid project is developing a specification for decentralized data storage. Amazon has open sourced two security tools developed for AWS: Cedar and Snapchange. Or maybe not. And Rust has forked, spawning a new programming language called Crab.
Providing a comprehensive set of diverse analytical frameworks for different use cases across the data lifecycle (data streaming, data engineering, data warehousing, operational database and machine learning) while at the same time seamlessly integrating data content via the Shared Data Experience (SDX), a layer that separates compute and storage.
High-quality video datasets tend to be massive, requiring substantial storage capacity and efficient data management systems. FSx for Lustre enables full bidirectional synchronization with Amazon Simple Storage Service (Amazon S3) , including the synchronization of deleted files and objects.
Only one out of more than 50 total AWS accounts identified by the researchers was being monitored by Amazon GuardDuty (an AWS security tool that continuously monitors configured AWS accounts for malicious activity) and the Prisma Cloud platform. SolarWinds – Failure to Secure the Build Environment.
Solution overview In this solution, we start with data preparation, where the raw datasets can be stored in an Amazon Simple Storage Service (Amazon S3) bucket. The whole process is shown in the following image: Implementation steps This solution has been tested in AWS Region us-east-1. Go to SageMaker Studio.
Imagine you’re a business analyst in a fast fashion brand, and you have a task to understand why sales of a new clothing line in a given region are dropping and how to increase them while achieving desired profit benchmark. Then to move data to single storage, explore and visualize it, defining interconnections between events and data points.
All 4,000 vCPUs, 7,680GB of RAM, and 384TB of NVMe storage of it! I thought I’d compile a good old fashioned list of Frequently Asked Questions (FAQ). This was after all the original incentive behind AWS. And then, in June, it was done. We had left the cloud. To say this journey was controversial is putting it mildly.
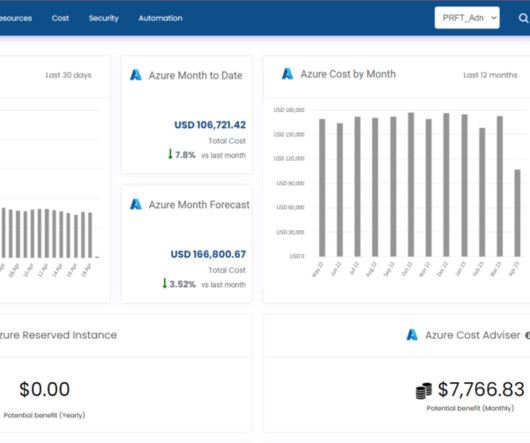
This could involve resizing instances, choosing the right storage type, or implementing automation to eliminate manual tasks. By implementing cloud FinOps practices, businesses can gain insight into their cloud costs, identify areas of waste, and take action to optimize their cloud usage.
are stored in secure storage layers. Amsterdam is built on top of three storage layers. And finally, we have an Apache Iceberg layer which stores assets in a denormalized fashion to help answer heavy queries for analytics use cases. It is also responsible for asset discovery, validation, sharing, and for triggering workflows.
Taos Practice Leader Supercomputing is the International Conference for High-Performance Computing (HPC), Networking, Storage and Analysis. Column-oriented NoSQL data stores, Object storage, and of course a wide variety of Hadoop implementations now play a critical role. Supercomputing ’12 is happening now in Salt Lake City.
Sub-intents and intent trees If you make the preceding scenario more complex, as in many real-life use cases, intents can be designed in a large number of categories and also in a hierarchical fashion, which will make the classification tasks more challenging for the model.
But what do the gas and oil corporation, the computer software giant, the luxury fashion house, the top outdoor brand, and the multinational pharmaceutical enterprise have in common? The relatively new storage architecture powering Databricks is called a data lakehouse. Databricks lakehouse platform architecture.
Scaling and State This is Part 9 of Learning Lambda, a tutorial series about engineering using AWS Lambda. Lambda’s scaling model has a large impact on how we consider state, so I also talk about Lambda’s instantiation and threading model, followed by a discussion on Application State & Data Storage, and Caching.
To reduce latency, assets should be generated in an offline fashion and not in real time. This requires an asset storage solution. Asset Storage We refer to asset storage and management simply as asset management. We can leverage high performance VMs in AWS to generate the assets.
Utilizing AWS Hosted Technologies to Bootstrap a Simple Cloud E-Commerce Solution A Very Brief Serverless Introduction There are plenty of blog posts and documentation that give introductions to serverless architectures in general and specific providers and technologies. They also mesh neatly with CI/CD solutions like CircleCI.
DataRobot AI Cloud brings together any type of data from any source to give our customers a holistic view that drives their business: critical information in databases, data clouds, cloud storage systems, enterprise apps, and more.
Cloud software computing and storage is a generalized term that describes all the layers and processes in cloud computing. The main idea behind the cloud-based approach is to move all sensitive data and files related to the server to dedicated cloud storage and request client-side data from there. Cloud T echnology: How it works.
The vigilant developer Imagine an IDE that's not just a glorified notepad but a security vigilante — a beautiful marriage of cutting-edge automation and good old fashioned human ingenuity. That's where our trusty friend, the integrated development environment (IDE), comes in armed with plug-ins to battle vulnerabilities.
No matter how cutting edge that new data storage solution is , regardless of or how much incredible value the sales engineer of the newest HCI platform to hit the market claims you will realize, at some point, there comes a point when it is time to move on. Then of course AWS continues its relentless pace of introducing new innovations.
Scaling and State This is Part 9 of Learning Lambda, a tutorial series about engineering using AWS Lambda. Lambda’s scaling model has a large impact on how we consider state, so I also talk about Lambda’s instantiation and threading model, followed by a discussion on Application State & Data Storage, and Caching.
Today I will be covering the advances that we have made in the area of hybrid-core architecture and its application to Network Attached Storage. It can be upgraded easily with a new firmware image in the same fashion as for switches or routers today. and Ethernet and FC handling.
In the digital communities that we live in, storage is virtually free and our garrulous species is generating and storing data like never before. 2 Enabling Infrastructure and Platform: Storage capacity, computation power and software tools are the three keys that have triggered the current wave of AI/ML success.
Before we dive into what cloud platform to choose and how to find a reliable AWS cloud managed services provider, for example, let’s define the benefits of such a decision. The difference is the same as going to a fast fashion shop and using tailor services. . It includes storage, backups, and data management. Cost Efficiency.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content