This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
To achieve these goals, the AWS Well-Architected Framework provides comprehensive guidance for building and improving cloud architectures. This allows teams to focus more on implementing improvements and optimizing AWS infrastructure. This scalability allows for more frequent and comprehensive reviews.
Refer to Supported Regions and models for batch inference for current supporting AWS Regions and models. To address this consideration and enhance your use of batch inference, we’ve developed a scalable solution using AWS Lambda and Amazon DynamoDB. One of the key advantages of batch inference is its cost-effectiveness.
Principal wanted to use existing internal FAQs, documentation, and unstructured data and build an intelligent chatbot that could provide quick access to the right information for different roles. Principal also used the AWS open source repository Lex Web UI to build a frontend chat interface with Principal branding.
Were excited to announce the open source release of AWS MCP Servers for code assistants a suite of specialized Model Context Protocol (MCP) servers that bring Amazon Web Services (AWS) best practices directly to your development workflow. This post is the first in a series covering AWS MCP Servers.
For instance, consider an AI-driven legal document analysis system designed for businesses of varying sizes, offering two primary subscription tiers: Basic and Pro. Meanwhile, the business analysis interface would focus on text summarization for analyzing various business documents. This is illustrated in the following figure.
AI practitioners and industry leaders discussed these trends, shared best practices, and provided real-world use cases during EXLs recent virtual event, AI in Action: Driving the Shift to Scalable AI. And its modular architecture distributes tasks across multiple agents in parallel, increasing the speed and scalability of migrations.
Earlier this year, we published the first in a series of posts about how AWS is transforming our seller and customer journeys using generative AI. Field Advisor serves four primary use cases: AWS-specific knowledge search With Amazon Q Business, weve made internal data sources as well as public AWS content available in Field Advisors index.
It also uses a number of other AWS services such as Amazon API Gateway , AWS Lambda , and Amazon SageMaker. You can use AWS services such as Application Load Balancer to implement this approach. On AWS, you can use the fully managed Amazon Bedrock Agents or tools of your choice such as LangChain agents or LlamaIndex agents.
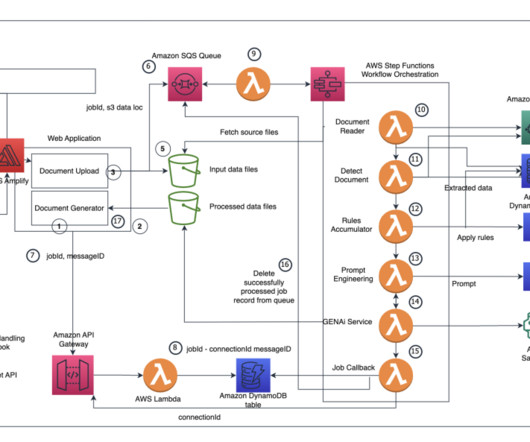
This post discusses how to use AWS Step Functions to efficiently coordinate multi-step generative AI workflows, such as parallelizing API calls to Amazon Bedrock to quickly gather answers to lists of submitted questions.
As part of MMTech’s unifying strategy, Beswick chose to retire the data centers and form an “enterprisewide architecture organization” with a set of standards and base layers to develop applications and workloads that would run on the cloud, with AWS as the firm’s primary cloud provider. The biggest challenge is data.
Today, were excited to announce the general availability of Amazon Bedrock Data Automation , a powerful, fully managed feature within Amazon Bedrock that automate the generation of useful insights from unstructured multimodal content such as documents, images, audio, and video for your AI-powered applications. billion in 2025 to USD 66.68
With Amazon Q Business , Hearst’s CCoE team built a solution to scale cloud best practices by providing employees across multiple business units self-service access to a centralized collection of documents and information. The CCoE implemented AWS Organizations across a substantial number of business units.
Using vLLM on AWS Trainium and Inferentia makes it possible to host LLMs for high performance inference and scalability. Deploy vLLM on AWS Trainium and Inferentia EC2 instances In these sections, you will be guided through using vLLM on an AWS Inferentia EC2 instance to deploy Meta’s newest Llama 3.2 You will use inf2.xlarge
Access to car manuals and technical documentation helps the agent provide additional context for curated guidance, enhancing the quality of customer interactions. The workflow includes the following steps: Documents (owner manuals) are uploaded to an Amazon Simple Storage Service (Amazon S3) bucket.
Whether processing invoices, updating customer records, or managing human resource (HR) documents, these workflows often require employees to manually transfer information between different systems a process thats time-consuming, error-prone, and difficult to scale. Prerequisites AWS Command Line Interface (CLI), follow instructions here.
As part of MMTech’s unifying strategy, Beswick chose to retire the data centers and form an “enterprisewide architecture organization” with a set of standards and base layers to develop applications and workloads that would run on the cloud, with AWS as the firm’s primary cloud provider. The biggest challenge is data.
Whether it’s structured data in databases or unstructured content in document repositories, enterprises often struggle to efficiently query and use this wealth of information. Amazon S3 is an object storage service that offers industry-leading scalability, data availability, security, and performance. aligned identity provider (IdP).
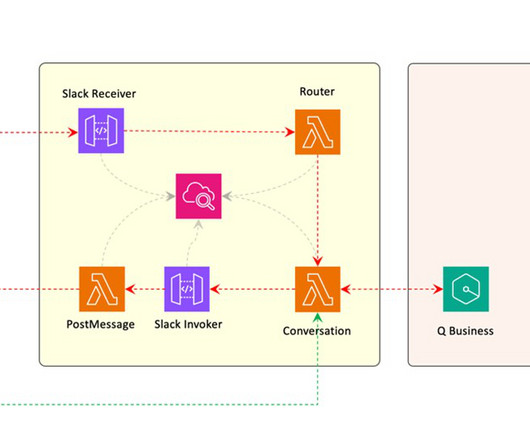
AWS offers powerful generative AI services , including Amazon Bedrock , which allows organizations to create tailored use cases such as AI chat-based assistants that give answers based on knowledge contained in the customers’ documents, and much more. The following figure illustrates the high-level design of the solution.
A key part of the submission process is authoring regulatory documents like the Common Technical Document (CTD), a comprehensive standard formatted document for submitting applications, amendments, supplements, and reports to the FDA. The tedious process of compiling hundreds of documents is also prone to errors.
This solution uses decorators in your application code to capture and log metadata such as input prompts, output results, run time, and custom metadata, offering enhanced security, ease of use, flexibility, and integration with native AWS services.
Solution overview This solution uses the Amazon Bedrock Knowledge Bases chat with document feature to analyze and extract key details from your invoices, without needing a knowledge base. Importantly, your document and data are not stored after processing. Make sure your AWS credentials are configured correctly.
This engine uses artificial intelligence (AI) and machine learning (ML) services and generative AI on AWS to extract transcripts, produce a summary, and provide a sentiment for the call. Organizations typically can’t predict their call patterns, so the solution relies on AWS serverless services to scale during busy times.
In Part 1 of this series, we learned about the importance of AWS and Pulumi. Now, lets explore the demo part in this practical session, which will create a service on AWS VPC by using Pulumi. AdministratorAccess or a custom policy). us-east-1) Output format (e.g., us-east-1) Output format (e.g., py to create a VPC: Step 3.
Deploy Secure Public Web Endpoints Welcome to Building Resilient Public Networking on AWS—our comprehensive blog series on advanced networking strategies tailored for regional evacuation, failover, and robust disaster recovery. We laid the groundwork for understanding the essentials that underpin the forthcoming discussions.
This is where intelligent document processing (IDP), coupled with the power of generative AI , emerges as a game-changing solution. The process involves the collection and analysis of extensive documentation, including self-evaluation reports (SERs), supporting evidence, and various media formats from the institutions being reviewed.
Solution overview To evaluate the effectiveness of RAG compared to model customization, we designed a comprehensive testing framework using a set of AWS-specific questions. On the Configure data source page, provide the following information: Specify the Amazon S3 location of the documents. Under Knowledge Bases, choose Create.
In this post, we explore how to deploy distilled versions of DeepSeek-R1 with Amazon Bedrock Custom Model Import, making them accessible to organizations looking to use state-of-the-art AI capabilities within the secure and scalableAWS infrastructure at an effective cost. You can monitor costs with AWS Cost Explorer.
Cloud modernization has become a prominent topic for organizations, and AWS plays a crucial role in helping them modernize their IT infrastructure, applications, and services. Overall, discussions on AWS modernization are focused on security, faster releases, efficiency, and steps towards GenAI and improved innovation.
Intelligent document processing , translation and summarization, flexible and insightful responses for customer support agents, personalized marketing content, and image and code generation are a few use cases using generative AI that organizations are rolling out in production.
As successful proof-of-concepts transition into production, organizations are increasingly in need of enterprise scalable solutions. The AWS Well-Architected Framework provides best practices and guidelines for designing and operating reliable, secure, efficient, and cost-effective systems in the cloud.
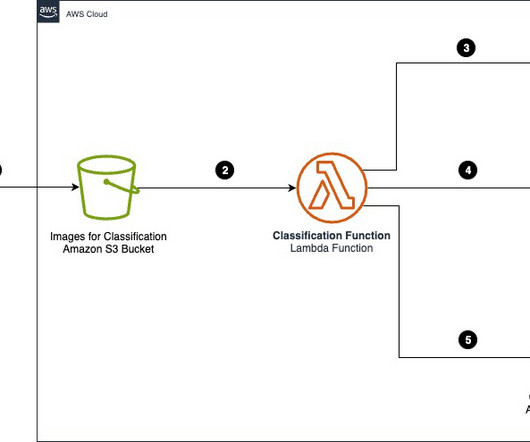
Organizations across industries want to categorize and extract insights from high volumes of documents of different formats. Manually processing these documents to classify and extract information remains expensive, error prone, and difficult to scale. Categorizing documents is an important first step in IDP systems.
Mozart, the leading platform for creating and updating insurance forms, enables customers to organize, author, and file forms seamlessly, while its companion uses generative AI to compare policy documents and provide summaries of changes in minutes, cutting the change adoption time from days or weeks to minutes.
Scalability and performance – The EMR Serverless integration automatically scales the compute resources up or down based on your workload’s demands, making sure you always have the necessary processing power to handle your big data tasks. By unlocking the potential of your data, this powerful integration drives tangible business results.
SageMaker Unified Studio combines various AWS services, including Amazon Bedrock , Amazon SageMaker , Amazon Redshift , Amazon Glue , Amazon Athena , and Amazon Managed Workflows for Apache Airflow (MWAA) , into a comprehensive data and AI development platform. Navigate to the AWS Secrets Manager console and find the secret -api-keys.
For example, consider how the following source document chunk from the Amazon 2023 letter to shareholders can be converted to question-answering ground truth. By segment, North America revenue increased 12% Y oY from $316B to $353B, International revenue grew 11% Y oY from$118B to $131B, and AWS revenue increased 13% Y oY from $80B to $91B.
The public cloud infrastructure is heavily based on virtualization technologies to provide efficient, scalable computing power and storage. Cloud adoption also provides businesses with flexibility and scalability by not restricting them to the physical limitations of on-premises servers. Amazon Web Services (AWS) Overview.
Today at AWS re:Invent 2024, we are excited to announce the new Container Caching capability in Amazon SageMaker, which significantly reduces the time required to scale generative AI models for inference. This feature is only supported when using inference components.
This post demonstrates how to seamlessly automate the deployment of an end-to-end RAG solution using Knowledge Bases for Amazon Bedrock and AWS CloudFormation , enabling organizations to quickly and effortlessly set up a powerful RAG system. An S3 bucket where your documents are stored in a supported format (.txt,md,html,doc/docx,csv,xls/.xlsx,pdf).
Confirm the AWS Regions where the model is available and quotas. Complete the knowledge base evaluation prerequisites related to AWS Identity and Access Management (IAM) creation and add permissions for an S3 bucket to access and write output data. Selected evaluator and generator models enabled in Amazon Bedrock.
With this launch, you can now access Mistrals frontier-class multimodal model to build, experiment, and responsibly scale your generative AI ideas on AWS. AWS is the first major cloud provider to deliver Pixtral Large as a fully managed, serverless model. Take a look at the Mistral-on-AWS repo.
However, these tools may not be suitable for more complex data or situations requiring scalability and robust business logic. In short, Booster is a Low-Code TypeScript framework that allows you to quickly and easily create a backend application in the cloud that is highly efficient, scalable, and reliable. WTF is Booster?
We demonstrate how to build an end-to-end RAG application using Cohere’s language models through Amazon Bedrock and a Weaviate vector database on AWS Marketplace. Additionally, you can securely integrate and easily deploy your generative AI applications using the AWS tools you are already familiar with.
From insurance to banking to healthcare, organizations of all stripes are upgrading their aging content management systems with modern, advanced systems that introduce new capabilities, flexibility, and cloud-based scalability. million documents, representing the past 15 years of business documents, to OnBase.
OpenAI launched GPT-4o in May 2024, and Amazon introduced Amazon Nova models at AWS re:Invent in December 2024. One of the most critical applications for LLMs today is Retrieval Augmented Generation (RAG), which enables AI models to ground responses in enterprise knowledge bases such as PDFs, internal documents, and structured data.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content