This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Cloudera is committed to providing the most optimal architecture for data processing, advanced analytics, and AI while advancing our customers’ cloud journeys. Together, Cloudera and AWS empower businesses to optimize performance for data processing, analytics, and AI while minimizing their resource consumption and carbon footprint.
Principal wanted to use existing internal FAQs, documentation, and unstructured data and build an intelligent chatbot that could provide quick access to the right information for different roles. Principal also used the AWS open source repository Lex Web UI to build a frontend chat interface with Principal branding.
Dbt is a popular tool for transforming data in a data warehouse or data lake. It enables dataengineers and analysts to write modular SQL transformations, with built-in support for data testing and documentation. In the next post, we’ll look into setting up Ducklake in AWS. What’s Next?
What is a dataengineer? Dataengineers design, build, and optimize systems for data collection, storage, access, and analytics at scale. They create data pipelines that convert raw data into formats usable by data scientists, data-centric applications, and other data consumers.
What is a dataengineer? Dataengineers design, build, and optimize systems for data collection, storage, access, and analytics at scale. They create data pipelines used by data scientists, data-centric applications, and other data consumers. The dataengineer role.
Since the release of Cloudera DataEngineering (CDE) more than a year ago , our number one goal was operationalizing Spark pipelines at scale with first class tooling designed to streamline automation and observability. Securing and scaling storage. Figure 2 – CDE product launch highlights in 2021.
When we introduced Cloudera DataEngineering (CDE) in the Public Cloud in 2020 it was a culmination of many years of working alongside companies as they deployed Apache Spark based ETL workloads at scale. It’s no longer driven by data volumes, but containerization, separation of storage and compute, and democratization of analytics.
Whether it’s structured data in databases or unstructured content in document repositories, enterprises often struggle to efficiently query and use this wealth of information. The solution combines data from an Amazon Aurora MySQL-Compatible Edition database and data stored in an Amazon Simple Storage Service (Amazon S3) bucket.
We discuss the unique challenges MaestroQA overcame and how they use AWS to build new features, drive customer insights, and improve operational inefficiencies. The customer interaction transcripts are stored in an Amazon Simple Storage Service (Amazon S3) bucket.
Azure Key Vault Secrets offers a centralized and secure storage alternative for API keys, passwords, certificates, and other sensitive statistics. Azure Key Vault is a cloud service that provides secure storage and access to confidential information such as passwords, API keys, and connection strings. What is Azure Key Vault Secret?
Cloud data architect: The cloud data architect designs and implements data architecture for cloud-based platforms such as AWS, Azure, and Google Cloud Platform. Data security architect: The data security architect works closely with security teams and IT teams to design data security architectures.
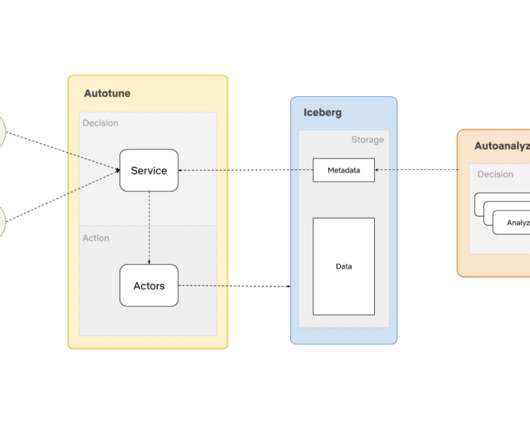
The Iceberg REST catalog specification is a key component for making Iceberg tables available and discoverable by many different tools and execution engines. It enables easy integration and interaction with Iceberg table metadata via an API and also decouples metadata management from the underlying storage.
Shared Data Experience ( SDX ) on Cloudera Data Platform ( CDP ) enables centralized data access control and audit for workloads in the Enterprise Data Cloud. The public cloud (CDP-PC) editions default to using cloud storage (S3 for AWS, ADLS-gen2 for Azure). RAZ for S3 gives them that capability.
Today at the AWS New York Summit, we announced a wide range of capabilities for customers to tailor generative AI to their needs and realize the benefits of generative AI faster. Each application can be immediately scaled to thousands of users and is secure and fully managed by AWS, eliminating the need for any operational expertise.
The shift to cloud has been accelerating, and with it, a push to modernize data pipelines that fuel key applications. That is why cloud native solutions which take advantage of the capabilities such as disaggregated storage & compute, elasticity, and containerization are more paramount than ever.
If you would like to submit a big data certification to this directory , please email us. AWS Certified Data Analytics The AWS Certified Data Analytics – Specialty certification is intended for candidates with experience and expertise working with AWS to design, build, secure, and maintain analytics solutions.
The problem is that this data is often sitting across a lot of different places — typically large organizations might have over 1,000 data sources, apps sitting across multiple clouds and servers and storage across Snowflake, Amazon Redshift and Databricks.
By Anupom Syam Background At Netflix, our current data warehouse contains hundreds of Petabytes of data stored in AWS S3 , and each day we ingest and create additional Petabytes. Some of the optimizations are prerequisites for a high-performance data warehouse. Increase in storage space. More processing resources.
While Microsoft, AWS, Google Cloud, and IBM have already released their generative AI offerings, rival Oracle has so far been largely quiet about its own strategy. While AWS, Google Cloud, Microsoft, and IBM have laid out how their AI services are going to work, most of these services are currently in preview.
The US financial services industry has fully embraced a move to the cloud, driving a demand for tech skills such as AWS and automation, as well as Python for data analytics, Java for developing consumer-facing apps, and SQL for database work. Dataengineer.
The US financial services industry has fully embraced a move to the cloud, driving a demand for tech skills such as AWS and automation, as well as Python for data analytics, Java for developing consumer-facing apps, and SQL for database work. Dataengineer.
Years ago, Mixbook undertook a strategic initiative to transition their operational workloads to Amazon Web Services (AWS) , a move that has continually yielded significant advantages. Data intake A user uploads photos into Mixbook. The raw photos are stored in Amazon Simple Storage Service (Amazon S3).
Prior to joining Lyft, Umare was a senior software engineer at Amazon and a principal engineer at Oracle, where he led development of a block storage product for an infrastructure-as-a-service and bare metal offering. “The machine learning sector is already large and growing within traditional companies as well.
by Shefali Vyas Dalal AWS re:Invent is a couple weeks away and our engineers & leaders are thrilled to be in attendance yet again this year! Technology advancements in content creation and consumption have also increased its data footprint. We’ve compiled our speaking events below so you know what we’ve been working on.
When our dataengineering team was enlisted to work on Tenable One, we knew we needed a strong partner. When Tenable’s product engineering team came to us in dataengineering asking how we could build a data platform to power the product, we knew we had an incredible opportunity to modernize our data stack.
On December 6 th -8 th 2023, the non-profit organization, Tech to the Rescue , in collaboration with AWS, organized the world’s largest Air Quality Hackathon – aimed at tackling one of the world’s most pressing health and environmental challenges, air pollution. Automatic code generation reduces dataengineering work from months to days.
The cloud offers excellent scalability, while graph databases offer the ability to display incredible amounts of data in a way that makes analytics efficient and effective. Who is Big DataEngineer? Big Data requires a unique engineering approach. Big DataEngineer vs Data Scientist.
To accomplish this, eSentire built AI Investigator, a natural language query tool for their customers to access security platform data by using AWS generative artificial intelligence (AI) capabilities. eSentire has over 2 TB of signal data stored in their Amazon Simple Storage Service (Amazon S3) data lake.
Snowflake, Redshift, BigQuery, and Others: Cloud Data Warehouse Tools Compared. From simple mechanisms for holding data like punch cards and paper tapes to real-time data processing systems like Hadoop, datastorage systems have come a long way to become what they are now. Is it still so? Scalability opportunities.
Second, since IaaS deployments replicated the on-premises HDFS storage model, they resulted in the same data replication overhead in the cloud (typical 3x), something that could have mostly been avoided by leveraging modern object store. Storage costs. 13,000-18,500. 7,500-11,500. 8,500-14,500. 5,500-9,000. hour using a r5d.4xlarge
To evaluate the models accuracy and track the mechanism, we store every user input and output in Amazon Simple Storage Service (Amazon S3). Prerequisites To create this solution, complete the following prerequisites: Sign up for an AWS account if you dont already have one. The FM generates the SQL query based on the final input.
As one of the largest AWS customers, Twilio engages with data, artificial intelligence (AI), and machine learning (ML) services to run their daily workloads. Data is the foundational layer for all generative AI and ML applications. The following diagram illustrates the solution architecture.
We suggest drawing a detailed comparison of Azure vs AWS to answer these questions. Azure vs AWS market share. What is Amazon AWS used for? Azure vs AWS features. Azure vs AWS comparison: other practical aspects. Azure vs AWS comparison: other practical aspects. Azure vs AWS: which is better?
The Ranger Authorization Service (RAZ) is a new service added to help provide fine-grained access control (FGAC) for cloud storage. RAZ for S3 and RAZ for ADLS introduce FGAC and Audit on CDP’s access to files and directories in cloud storage making it consistent with the rest of the SDX data entities.
Data architecture is the organization and design of how data is collected, transformed, integrated, stored, and used by a company. What is the main difference between a data architect and a dataengineer? By the way, we have a video dedicated to the dataengineering working principles.
Scalability and performance – The EMR Serverless integration automatically scales the compute resources up or down based on your workload’s demands, making sure you always have the necessary processing power to handle your big data tasks. This flexibility helps optimize performance and minimize the risk of bottlenecks or resource constraints.
This blog post focuses on how the Kafka ecosystem can help solve the impedance mismatch between data scientists, dataengineers and production engineers. Impedance mismatch between data scientists, dataengineers and production engineers. For now, we’ll focus on Kafka.
A data source connector is a component of Amazon Q that helps integrate and synchronize data from multiple repositories into one index. For a full list of Amazon Q business supported data source connectors, see Amazon Q Business connectors. For a complete list of ServiceNow roles, refer to documentation.
An overview of data warehouse types. Optionally, you may study some basic terminology on dataengineering or watch our short video on the topic: What is dataengineering. What is data pipeline. This could be a transactional database or any other storage we take data from. Data extraction.
Cloudera, a leader in big data analytics, provides a unified Data Platform for data management, AI, and analytics. Our customers run some of the world’s most innovative, largest, and most demanding data science, dataengineering, analytics, and AI use cases, including PB-size generative AI workloads.
This will be a blend of private and public hyperscale clouds like AWS, Azure, and Google Cloud Platform. Hybrid clouds must bond together the two clouds through fundamental technology, which will enable the transfer of data and applications. REAN Cloud has expertise working with the hyperscale public clouds.
by Shefali Vyas Dalal AWS re:Invent is a couple weeks away and our engineers & leaders are thrilled to be in attendance yet again this year! Technology advancements in content creation and consumption have also increased its data footprint. We’ve compiled our speaking events below so you know what we’ve been working on.
by Shefali Vyas Dalal AWS re:Invent is a couple weeks away and our engineers & leaders are thrilled to be in attendance yet again this year! Technology advancements in content creation and consumption have also increased its data footprint. We’ve compiled our speaking events below so you know what we’ve been working on.
Each of the ‘big three’ cloud providers (AWS, Azure, GCP) offer a number of cloud certification options that individuals can get to validate their cloud knowledge and skill set, while helping them advance in their careers and broaden the scope of their achievements. . Amazon Web Services (AWS) Certifications.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















































Let's personalize your content