This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
We discuss the unique challenges MaestroQA overcame and how they use AWS to build new features, drive customer insights, and improve operational inefficiencies. This expansion is achieved without introducing additional complexities, thereby maintaining operational efficiency while adhering to Regional data regulations.
That’s where the new Amazon EMR Serverless application integration in Amazon SageMaker Studio can help. In this post, we demonstrate how to leverage the new EMR Serverless integration with SageMaker Studio to streamline your data processing and machine learning workflows.
Key Components of Azure Synapse Analytics Data Warehousing with Dedicated SQL Pools At its core, Azure Synapse provides dedicated SQL pools (formerly known as Azure SQL Data Warehouse), which function as a traditional MPP (massively parallel processing) data warehouse. on-premises, AWS, Google Cloud).
To accomplish this, eSentire built AI Investigator, a natural language query tool for their customers to access security platform data by using AWS generative artificial intelligence (AI) capabilities. eSentire has over 2 TB of signal data stored in their Amazon Simple Storage Service (Amazon S3) data lake.
On December 6 th -8 th 2023, the non-profit organization, Tech to the Rescue , in collaboration with AWS, organized the world’s largest Air Quality Hackathon – aimed at tackling one of the world’s most pressing health and environmental challenges, air pollution. Having a human-in-the-loop to validate each data transformation step is optional.
Years ago, Mixbook undertook a strategic initiative to transition their operational workloads to Amazon Web Services (AWS) , a move that has continually yielded significant advantages. The data intake process involves three macro components: Amazon Aurora MySQL-Compatible Edition , Amazon S3, and AWS Fargate for Amazon ECS.
Building applications with RAG requires a portfolio of data (company financials, customer data, data purchased from other sources) that can be used to build queries, and data scientists know how to work with data at scale. Dataengineers build the infrastructure to collect, store, and analyze data.
Another cloud service I’m asked about is AWS Amplify from another popular cloud giant. Assuming you’re able to choose the best tool for the job, let’s contrast AWS Amplify with Kinvey, our serverless development platform for business apps. Where Does AWS Amplify Fit? When Should I Use Progress Kinvey?
Another cloud service I’m asked about is AWS Amplify from another popular cloud giant. Assuming you’re able to choose the best tool for the job, let’s contrast AWS Amplify with Kinvey, our serverless development platform for business apps. Where Does AWS Amplify Fit? When Should I Use Progress Kinvey?
Another cloud service I’m asked about is AWS Amplify from another popular cloud giant. Assuming you’re able to choose the best tool for the job, let’s contrast AWS Amplify with Kinvey, our serverless development platform for business apps. Where Does AWS Amplify Fit? When Should I Use Progress Kinvey?
The 3rd generation data warehouses add more computing choices to MPP and offer different pricing models. By the level of back-end management involved: Serverlessdata warehouses get their functional building blocks with the help of serverless services, meaning they are fully-managed by third-party vendors. Source: AWS.
Get hands-on training in machine learning, AWS, Kubernetes, Python, Java, and many other topics. An Introduction to Amazon Machine Learning on AWS , April 29-30. Data science and data tools. Practical Linux Command Line for DataEngineers and Analysts , March 13. Data Modelling with Qlik Sense , March 19-20.
Because Amazon Bedrock is serverless, you don’t have to manage any infrastructure. About the Authors Ori Nakar is a Principal cyber-security researcher, a dataengineer, and a data scientist at Imperva Threat Research group. Eitan Sela is a Generative AI and Machine Learning Specialist Solutions Architect at AWS.
AWS Security Fundamentals , July 15. AWS Certified Security - Specialty Crash Course , July 25-26. Systems engineering and operations. AWS Access Management , June 6. AWS Certified Big Data - Specialty Crash Course , June 26-27. Getting Started with Amazon SageMaker on AWS , July 1.
The first quantum computers are now available through cloud providers like IBM and Amazon Web Services (AWS). Year-over-year growth for software architecture and design topics What about serverless? Serverless looks like an excellent technology for implementing microservices, but it’s been giving us mixed signals for several years now.
In the survey behind our upcoming report, “Evolving data infrastructure,” we found 85% of respondents indicated they had data infrastructure in at least one of the seven cloud providers we listed, with two-thirds (63%) using Amazon Web Services (AWS) for some portion of their data infrastructure.
Data science is generally not operationalized Consider a data flow from a machine or process, all the way to an end-user. 2 In general, the flow of data from machine to the dataengineer (1) is well operationalized. You could argue the same about the dataengineering step (2) , although this differs per company.
We suggest drawing a detailed comparison of Azure vs AWS to answer these questions. Azure vs AWS market share. What is Amazon AWS used for? Azure vs AWS features. Azure vs AWS comparison: other practical aspects. Azure vs AWS comparison: other practical aspects. Azure vs AWS: which is better?
Fundamentals of Machine Learning with AWS , June 19. Building Machine Learning Models with AWS Sagemaker , June 20. Data science and data tools. Practical Linux Command Line for DataEngineers and Analysts , May 20. First Steps in Data Analysis , May 20. AWS CloudFormation Deep Dive , June 3-4.
At our recent Evolve Conference in New York we were extremely excited to announce our founding AI ecosystem partners: Amazon Web Services (“AWS“), NVIDIA, and Pinecone. That’s why we’re building an ecosystem of technology providers to make it easier, more economical, and safer for our customers to maximize the value they get from AI.
AWS Security Fundamentals , July 15. AWS Certified Security - Specialty Crash Course , July 25-26. Systems engineering and operations. AWS Access Management , June 6. AWS Certified Big Data - Specialty Crash Course , June 26-27. Getting Started with Amazon SageMaker on AWS , July 1.
Machine learning, artificial intelligence, dataengineering, and architecture are driving the data space. The Strata Data Conferences helped chronicle the birth of big data, as well as the emergence of data science, streaming, and machine learning (ML) as disruptive phenomena.
The platform provides fast, flexible, and easy-to-use options for data storage, processing, and analysis. Initially built on top of the Amazon Web Services (AWS), Snowflake is also available on Google Cloud and Microsoft Azure. Modern data pipeline with Snowflake technology as its part. Well, almost serverless, to be exact.
Americas livestream, Citus open source user, real-time analytics, JSONB) Lessons learned: Migrating from AWS-Hosted PostgreSQL RDS to Self-Hosted Citus , by Matt Klein & Delaney Mackenzie of Jellyfish.co. (on-demand . :) 4 Citus customer talks Citus for real-time analytics at Vizor Games , by Ivan Vyazmitinov of Vizor Games.
The company’s platform is designed to give data teams a unified platform to automate the orchestration of dataengineering and analytics workloads, he says, ideally reducing the need for manual configuration. Rather, it was the ability to scale the productivity of the people who work with data.
You can hardly compare dataengineering toil with something as easy as breathing or as fast as the wind. The platform went live in 2015 at Airbnb, the biggest home-sharing and vacation rental site, as an orchestrator for increasingly complex data pipelines. How dataengineering works. What is Apache Airflow?
Today at the AWS New York Summit, we announced a wide range of capabilities for customers to tailor generative AI to their needs and realize the benefits of generative AI faster. Each application can be immediately scaled to thousands of users and is secure and fully managed by AWS, eliminating the need for any operational expertise.
A quick look at bigram usage (word pairs) doesn’t really distinguish between “data science,” “dataengineering,” “data analysis,” and other terms; the most common word pair with “data” is “data governance,” followed by “data science.” That’s no longer true. Programming Languages.
Usage data shows what content our members actually use, though we admit it has its own problems: usage is biased by the content that’s available, and there’s no data for topics that are so new that content hasn’t been developed. We haven’t combined data from multiple terms. serverless, a.k.a. FaaS, a.k.a.
What is Databricks Databricks is an analytics platform with a unified set of tools for dataengineering, data management , data science, and machine learning. It combines the best elements of a data warehouse, a centralized repository for structured data, and a data lake used to host large amounts of raw data.
Scalability and reliability backed by AWS infrastructure This means your agent systems can handle increasing workloads while maintaining consistent performance. Solution overview Each AWS service has its own configuration nuances, and missing just one detail can lead to serious vulnerabilities.
Amazon Athena is a serverless, interactive analytics service that provides a simplified and flexible way to analyze petabytes of data where it lives. Amazon Athena also makes it easy to interactively run data analytics using Apache Spark without having to plan for, configure, or manage resources.
At the heart of this transformation is the OMRON Data & Analytics Platform (ODAP), an innovative initiative designed to revolutionize how the company harnesses its data assets. Some of these tools included AWS Cloud based solutions, such as AWS Lambda and AWS Step Functions.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










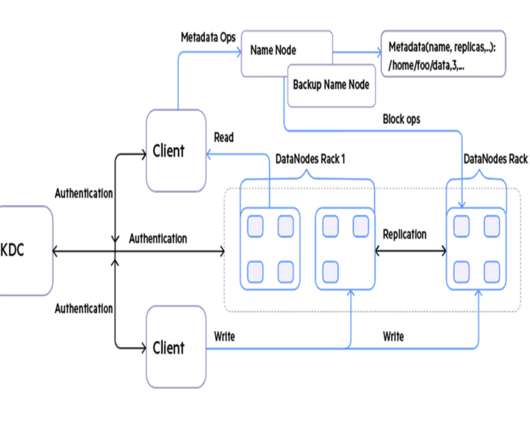




















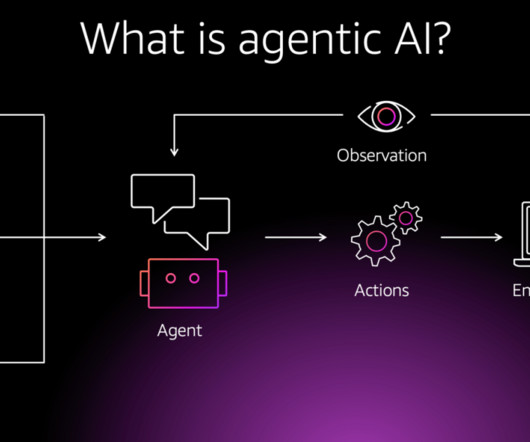











Let's personalize your content