This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The world has known the term artificialintelligence for decades. Developing AI When most people think about artificialintelligence, they likely imagine a coder hunched over their workstation developing AI models. In other cases, the model might scan and process open-source data.
To solve the problem, the company turned to gen AI and decided to use both commercial and opensource models. With security, many commercial providers use their customers data to train their models, says Ringdahl. So we augment with opensource, he says. Its possible to opt-out, but there are caveats.
The move relaxes Meta’s acceptable use policy restricting what others can do with the large language models it develops, and brings Llama ever so slightly closer to the generally accepted definition of open-source AI. As long as Meta keeps the training data confidential, CIOs need not be concerned about data privacy and security.
In a step toward solving it, OpenAI today open-sourced Whisper, an automatic speech recognition system that the company claims enables “robust” transcription in multiple languages as well as translation from those languages into English. Speech recognition remains a challenging problem in AI and machine learning.
Media outlets and entertainers have already filed several AI copyright cases in US courts, with plaintiffs accusing AI vendors of using their material to train AI models or copying their material in outputs, notes Jeffrey Gluck, a lawyer at IP-focused law firm Panitch Schwarze. How was the AI trained?
For many, ChatGPT and the generative AI hype train signals the arrival of artificialintelligence into the mainstream. Just last year, a similar proposition to Qdrant called Pinecone nabbed $28 million , though Zayarni considers Qdrant’s opensource foundation as a major selling point for would-be customers.
Even if you don’t have the training data or programming chops, you can take your favorite opensource model, tweak it, and release it under a new name. According to Stanford’s AI Index Report, released in April, 149 foundation models were released in 2023, two-thirds of them opensource.
Jorge Torres is CEO and co-founder of MindsDB , an opensource AI layer for existing databases. Adam Carrigan is a co-founder and COO of MindsDB , an opensource AI layer for existing databases. Open-source software gave birth to a slew of useful software in recent years. Contributor. Share on Twitter.
Training a frontier model is highly compute-intensive, requiring a distributed system of hundreds, or thousands, of accelerated instances running for several weeks or months to complete a single job. For example, pre-training the Llama 3 70B model with 15 trillion training tokens took 6.5 During the training of Llama 3.1
But so far, only a handful of such AI systems have been made freely available to the public and opensourced — reflecting the commercial incentives of the companies building them. billion parameters) — using ServiceNow’s in-house graphics card cluster.
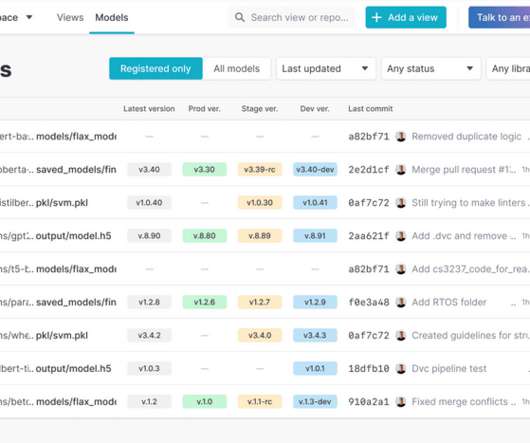
MLOps platform Iterative , which announced a $20 million Series A round almost exactly a year ago, today launched MLEM, an open-source git-based machine learning model management and deployment tool. For highly regulated industries, a system like this also offers a single source of truth for figuring out the lineage of a given model.
The nonpartisan think tank Brookings this week published a piece decrying the bloc’s regulation of opensource AI, arguing it would create legal liability for general-purpose AI systems while simultaneously undermining their development. “In the end, the [E.U.’s] “In the end, the [E.U.’s]
Activeloop , a member of the Y Combinator summer 2018 cohort , is building a database specifically designed for media-focused artificialintelligence applications. He says that there are 55 contributors to the opensource project and 700 community members overall. Activeloop image database. Image Credits: Activeloop.
Sovereign AI refers to a national or regional effort to develop and control artificialintelligence (AI) systems, independent of the large non-EU foreign private tech platforms that currently dominate the field. The Data Act framework creates new possibilities to access data that could be used for AI training and development.
Heartex, a startup that bills itself as an “opensource” platform for data labeling, today announced that it landed $25 million in a Series A funding round led by Redpoint Ventures. When asked, Heartex says that it doesn’t collect any customer data and opensources the core of its labeling platform for inspection.
All industries and modern applications are undergoing rapid transformation powered by advances in accelerated computing, deep learning, and artificialintelligence. The next phase of this transformation requires an intelligent data infrastructure that can bring AI closer to enterprise data.
Artificialintelligence promises to help, and maybe even replace, humans to carry out everyday tasks and solve problems that humans have been unable to tackle, yet ironically, building that AI faces a major scaling problem. It has effectively built training models to automate the training of those models.
ArtificialIntelligence (AI) is revolutionizing software development by enhancing productivity, improving code quality, and automating routine tasks. It uses OpenAI’s Codex, a language model trained on a vast amount of code from public repositories on GitHub. Also Read: Will ArtificialIntelligence Replace Programmers?
Check out a new framework for better securing opensource projects. 1 - New cybersecurity framework for opensource projects Heres the latest industry effort aimed at boosting open-source software security. Plus, learn how AI is making ransomware harder to detect and mitigate.
Digital transformation started creating a digital presence of everything we do in our lives, and artificialintelligence (AI) and machine learning (ML) advancements in the past decade dramatically altered the data landscape. Implementing ML capabilities can help find the right thresholds.
AI Little Language Models is an educational program that teaches young children about probability, artificialintelligence, and related topics. Google is open-sourcing SynthID, a system for watermarking text so AI-generated documents can be traced to the LLM that generated them. It’s currently in beta. on benchmarks.
Explosion , a company that has combined an opensource machine learning library with a set of commercial developer tools, announced a $6 million Series A today on a $120 million valuation. Since then, that opensource project has been downloaded over 40 million times. .
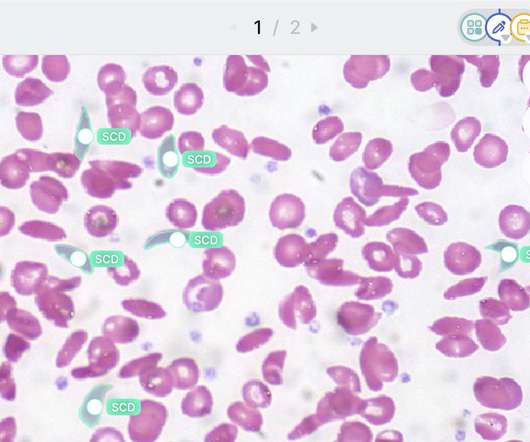
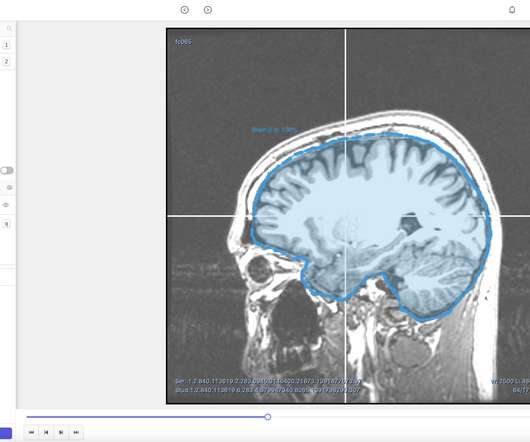
Artificialintelligence has become ubiquitous in clinical diagnosis. But researchers need much of their initial time preparing data for training AI systems. The training process also requires hundreds of annotated medical images and thousands of hours of annotation by clinicians. and Europe for marketing its tools.
Different ways to customize an LLM include fine-tuning an off-the-shelf model or building a custom one using an open-source LLM like Meta ’s Llama. Vertical-specific training data Does the startup have access to a large volume of proprietary, vertical-specific data to train its LLMs?
But in many cases, the prospect of migrating to modern cloud native, opensource languages 1 seems even worse. Artificialintelligence (AI) tools have emerged to help, but many businesses fear they will expose their intellectual property, hallucinate errors or fail on large codebases because of their prompt limits.
Production ready (pre-trained) NLP models for English are readily available ‘out of the box’ There are also dedicated opensource frameworks offering help with training models. And Hugging Face’s open-source repository for NLP models is also a great step in this direction. NLPCloud.io
Weve also seen the emergence of agentic AI, multi-modal AI, reasoning AI, and open-source AI projects that rival those of the biggest commercial vendors. Developers must comply by the start of 2026, meaning theyll have a little over a year to put systems in place to track the provenance of their training data.
Other times, it can be done with opensource tools or sensors. We think that transitioning to an approach where you really think about the training data in the first place will help accelerate the progression of these models.”. Ironically, those new techniques are themselves versions of artificialintelligence.
Check out why memory vulnerabilities are widespread in opensource projects. The agencies analyzed 172 projects that the OpenSource Security Foundation has identified as being critically important in the opensource ecosystem. And learn how confidential data from U.S. And much more!
Artificialintelligence, it is widely assumed, will soon unleash the biggest transformation in health care provision since the medical sector started its journey to professionalization after the flu pandemic of 1918. What is TRAIN? CHAI’s engineering partners include Microsoft (again) alongside Amazon, Google, and CVS Health.
Plus, opensource security experts huddled at a conference this week – find out what they talked about. Those are some of the initiatives the Linux Foundation’s OpenSource Security Foundation (OpenSSF) plans to undertake in the coming year, the group announced at its “Secure OpenSource Software Summit 2023” held in Washington, D.C.
With the release of powerful publicly available foundation models, tools for training, fine tuning and hosting your own LLM have also become democratized. nGen AI is a new type of artificialintelligence that is designed to learn and adapt to new situations and environments. choices[0].text'
On top of that, Gen AI, and the large language models (LLMs) that power it, are super-computing workloads that devour electricity.Estimates vary, but Dr. Sajjad Moazeni of the University of Washington calculates that training an LLM with 175 billion+ parameters takes a year’s worth of energy for 1,000 US households. Not at all.
Natural language processing definition Natural language processing (NLP) is the branch of artificialintelligence (AI) that deals with training computers to understand, process, and generate language. Every time you look something up in Google or Bing, you’re helping to train the system.
The OpenSource Initiative (OSI) has released its official definition of “open” artificialintelligence, setting the stage for a clash with tech giants like Meta — whose models don’t fit the rules.
Key to its success is that its open-source project Seldon Core has more than 700,000 models deployed to date, drastically reducing friction for users deploying ML models. Seldon has been able to build an impressive open-source community and add immediate productivity value to some of the world’s leading companies.”
This reimposed the need for cybersecurity leveraging artificialintelligence to generate stronger weapons for defending the ever-under-attack walls of digital systems. Inclusion of further programming languages, with the ability to be trained by developers of each organization with minimal effort. billion user details.
And when it comes to AI systems making consequential decisions for people, especially high standards should be applied, particularly to the transparency of data a particular AI was trained for its decision-making, and how the algorithms work to ultimately make decisions. ArtificialIntelligence should serve us, not manipulate.”
LoRA is a technique for efficiently adapting large pre-trained language models to new tasks or domains by introducing small trainable weight matrices, called adapters, within each linear layer of the pre-trained model. But, again, it depends on the implementation and complexity of the task that the adapter is being trained on or for.
Reasons for using RAG are clear: large language models (LLMs), which are effectively syntax engines, tend to “hallucinate” by inventing answers from pieces of their training data. See the primary sources “ REALM: Retrieval-Augmented Language Model Pre-Training ” by Kelvin Guu, et al., at Facebook—both from 2020.
Alignment AI alignment refers to a set of values that models are trained to uphold, such as safety or courtesy. There’s only so much you can do with a prompt if the model has been heavily trained to go against your interests.” Training is most expensive,” says Andy Thurai, VP and principal analyst at Constellation Research.
Given the importance of being able to control data access and respect privacy and regulatory concerns while harnessing GenAI’s tremendous potential, Dell Technologies and Intel have been investigating GenAI implementations, open-source models, and alternatives to trillion-plus parameter models. million in compute alone 2.
We promote innovation through regulatory sandboxes, real-world testing and opensources [excluding opensource AI systems from transparency requirement]. Significantly, the models based on opensource are exempt from the transparency requirement. “So ArtificialIntelligence, Regulation
Microsoft has added generative artificialintelligence and other enhanced features to its quantum-computing platform as part of a larger strategy to deliver the game-changing technology to a broader range of users — in this case, the scientific community.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content