This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
With serverless components, there is no need to manage infrastructure, and the inbuilt tracing, logging, monitoring and debugging make it easy to run these workloads in production and maintain service levels. Financial services unique challenges However, it is important to understand that serverless architecture is not a silver bullet.
Organizations are increasingly using multiple largelanguagemodels (LLMs) when building generative AI applications. Although an individual LLM can be highly capable, it might not optimally address a wide range of use cases or meet diverse performance requirements.
With rapid progress in the fields of machinelearning (ML) and artificialintelligence (AI), it is important to deploy the AI/ML model efficiently in production environments. The architecture downstream ensures scalability, cost efficiency, and real-time access to applications.
Augmented data management with AI/ML ArtificialIntelligence and MachineLearning transform traditional data management paradigms by automating labour-intensive processes and enabling smarter decision-making. With machinelearning, these processes can be refined over time and anomalies can be predicted before they arise.
If an image is uploaded, it is stored in Amazon Simple Storage Service (Amazon S3) , and a custom AWS Lambda function will use a machinelearningmodel deployed on Amazon SageMaker to analyze the image to extract a list of place names and the similarity score of each place name. Here is an example from LangChain.
Traditionally, building frontend and backend applications has required knowledge of web development frameworks and infrastructure management, which can be daunting for those with expertise primarily in data science and machinelearning. The Streamlit application will now display a button labeled Get LLM Response.
Amazon Web Services (AWS) provides an expansive suite of tools to help developers build and manage serverless applications with ease. In this article, we delve into serverless AI/ML on AWS, exploring best practices, implementation strategies, and an example to illustrate these concepts in action.
This engine uses artificialintelligence (AI) and machinelearning (ML) services and generative AI on AWS to extract transcripts, produce a summary, and provide a sentiment for the call. Organizations typically can’t predict their call patterns, so the solution relies on AWS serverless services to scale during busy times.
That’s right, folks; I replaced the Xebia leadership with artificialintelligence! The magic happens through a combination of Serverless, user input, a CloudFront distribution, a Lambda function, and the OpenAI API. The post How I replaced Xebia Leadership with ArtificialIntelligence appeared first on Xebia.
However, although engineering resources may be slim, serverless offers new solutions to tackle the DevOps challenge. From improved IoT devices to cost-effective machinelearning applications, the serverless ecosystem is […].
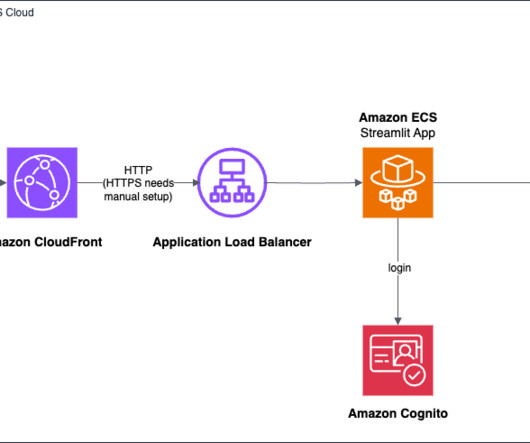
API Gateway is serverless and hence automatically scales with traffic. The advantage of using Application Load Balancer is that it can seamlessly route the request to virtually any managed, serverless or self-hosted component and can also scale well. It’s serverless so you don’t have to manage the infrastructure.
Seamless integration of latest foundation models (FMs), Prompts, Agents, Knowledge Bases, Guardrails, and other AWS services. Reduced time and effort in testing and deploying AI workflows with SDK APIs and serverless infrastructure. Flexibility to define the workflow based on your business logic.
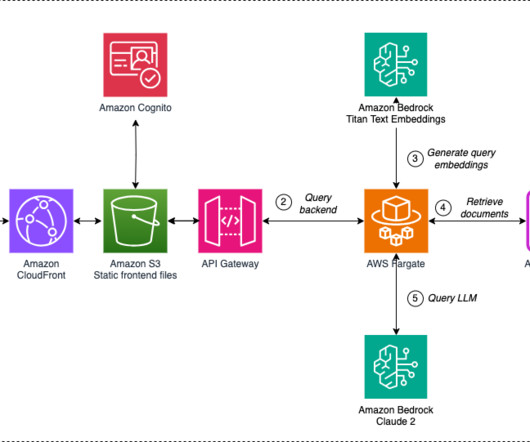
Their DeepSeek-R1 models represent a family of largelanguagemodels (LLMs) designed to handle a wide range of tasks, from code generation to general reasoning, while maintaining competitive performance and efficiency. The following diagram illustrates the end-to-end flow.
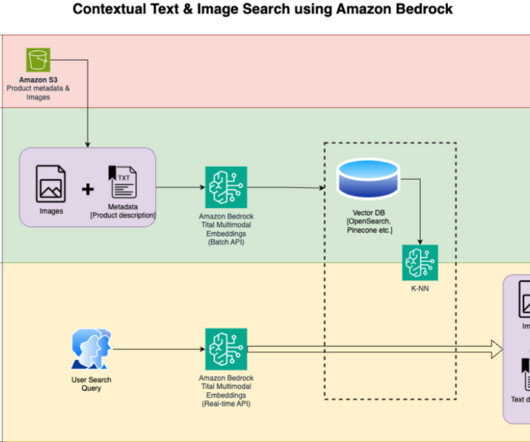
The Amazon Bedrock single API access, regardless of the models you choose, gives you the flexibility to use different FMs and upgrade to the latest model versions with minimal code changes. Amazon Titan FMs provide customers with a breadth of high-performing image, multimodal, and text model choices, through a fully managed API.
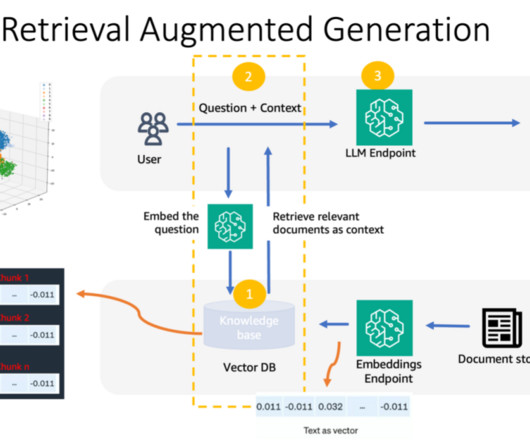
In addition, customers are looking for choices to select the most performant and cost-effective machinelearning (ML) model and the ability to perform necessary customization (fine-tuning) to fit their business use cases. The LLM generated text, and the IR system retrieves relevant information from a knowledge base.
DataRobot,a provider of a platform for building artificialintelligence (AI) applications, this week acquired Agnostic, a provider of an open source distributed computing platform, dubbed Covalent, that will be integrated with its machinelearning operations (MLOps) framework.
The solution integrates largelanguagemodels (LLMs) with your organization’s data and provides an intelligent chat assistant that understands conversation context and provides relevant, interactive responses directly within the Google Chat interface. Which LLM you want to use in Amazon Bedrock for text generation.
These assistants can be powered by various backend architectures including Retrieval Augmented Generation (RAG), agentic workflows, fine-tuned largelanguagemodels (LLMs), or a combination of these techniques. To learn more about FMEval, see Evaluate largelanguagemodels for quality and responsibility of LLMs.
The O’Reilly Data Show Podcast: Eric Jonas on Pywren, scientific computation, and machinelearning. Jonas and his collaborators are working on a related project, NumPyWren, a system for linear algebra built on a serverless architecture. Jonas is also affiliated with UC Berkeley’s RISE Lab.
Generative AI is a type of artificialintelligence (AI) that can be used to create new content, including conversations, stories, images, videos, and music. Like all AI, generative AI works by using machinelearningmodels—very largemodels that are pretrained on vast amounts of data called foundation models (FMs).
Customizable Uses prompt engineering , which enables customization and iterative refinement of the prompts used to drive the largelanguagemodel (LLM), allowing for refining and continuous enhancement of the assessment process. Brijesh specializes in AI/ML solutions and has experience with serverless architectures.
In this post, we show how to build a contextual text and image search engine for product recommendations using the Amazon Titan Multimodal Embeddings model , available in Amazon Bedrock , with Amazon OpenSearch Serverless. Amazon SageMaker Studio – It is an integrated development environment (IDE) for machinelearning (ML).
To accomplish this, eSentire built AI Investigator, a natural language query tool for their customers to access security platform data by using AWS generative artificialintelligence (AI) capabilities. Therefore, eSentire decided to build their own LLM using Llama 1 and Llama 2 foundational models.
In this post, we demonstrate how we used Amazon Bedrock , a fully managed service that makes FMs from leading AI startups and Amazon available through an API, so you can choose from a wide range of FMs to find the model that is best suited for your use case. Presently, his main area of focus is state-of-the-art natural language processing.
Of late, innovative data integration tools are revolutionising how organisations approach data management, unlocking new opportunities for growth, efficiency, and strategic decision-making by leveraging technical advancements in ArtificialIntelligence, MachineLearning, and Natural Language Processing.
Companies successfully adopt machinelearning either by building on existing data products and services, or by modernizing existing models and algorithms. I will highlight the results of a recent survey on machinelearning adoption, and along the way describe recent trends in data and machinelearning (ML) within companies.
More than 170 tech teams used the latest cloud, machinelearning and artificialintelligence technologies to build 33 solutions. Cost-effective – The solution should only invoke LLM to generate reusable code on an as-needed basis instead of manipulating the data directly to be as cost-effective as possible.
Real-time monitoring and anomaly detection systems powered by artificialintelligence and machinelearning, capable of identifying and responding to threats in cloud environments within seconds. Leverage AI and machinelearning to sift through large volumes of data and identify potential threats quickly.
And the Lithia Springs production site in Georgia was converted to a serverless environment, which reduced costs and improved the company’s carbon footprint. But I’d like to see more differentiation between advanced analytics, machinelearning, and AI to better use and understand functions, areas of application, and potential.”
Cloudera is launching and expanding partnerships to create a new enterprise artificialintelligence “AI” ecosystem. In a stack including Cloudera Data Platform the applications and underlying models can also be deployed from the data management platform via Cloudera MachineLearning.
From deriving insights to powering generative artificialintelligence (AI) -driven applications, the ability to efficiently process and analyze large datasets is a vital capability. That’s where the new Amazon EMR Serverless application integration in Amazon SageMaker Studio can help.
Amazon SageMaker Canvas is a no-code machinelearning (ML) service that empowers business analysts and domain experts to build, train, and deploy ML models without writing a single line of code. You can extend this solution to generative artificialintelligence (AI) use cases as well.
Welcome to our tutorial on deploying a machinelearning (ML) model on Amazon Web Services (AWS) Lambda using Docker. In this tutorial, we will walk you through the process of packaging an ML model as a Docker container and deploying it on AWS Lambda, a serverless computing service. So, let’s get started!
In this article, we will discuss how MentorMate and our partner eLumen leveraged natural language processing (NLP) and machinelearning (ML) for data-driven decision-making to tame the curriculum beast in higher education. Here, we will primarily focus on drawing insights from structured and unstructured (text) data.
In Part 3 , we demonstrate how business analysts and citizen data scientists can create machinelearning (ML) models, without code, in Amazon SageMaker Canvas and deploy trained models for integration with Salesforce Einstein Studio to create powerful business applications.
You can deploy this solution with just a few clicks using Amazon SageMaker JumpStart , a fully managed platform that offers state-of-the-art foundation models for various use cases such as content writing, code generation, question answering, copywriting, summarization, classification, and information retrieval. Create a question embedding.
Its serverless architecture allowed the team to rapidly prototype and refine their application without the burden of managing complex hardware infrastructure. Check out MaestroQAs feature AskAI and their LLM-powered AI Classifiers if youre interested in better understanding your customer conversations and survey scores.
In part 1 of this blog series, we discussed how a largelanguagemodel (LLM) available on Amazon SageMaker JumpStart can be fine-tuned for the task of radiology report impression generation. It’s serverless, so you don’t have to manage any infrastructure. It is time-consuming but, at the same time, critical.
This is a single, integrated location that allows for a data warehouse, and large data processing. Also combines data integration with machinelearning. This is designed for large-scale data storage, query optimization, and analytics. This is ideal for exploring data without moving it into a structured data warehouse.
When Pinecone launched last year, the company’s message was around building a serverless vector database designed specifically for the needs of data scientists. This [format] is much more semantically rich and actionable for machinelearning.
Imagine this—all employees relying on generative artificialintelligence (AI) to get their work done faster, every task becoming less mundane and more innovative, and every application providing a more useful, personal, and engaging experience. Read more about our commitments to responsible AI on the AWS MachineLearning Blog.
Retrieval-Augmented Generation (RAG) is a key technique powering more broad and trustworthy application of largelanguagemodels (LLMs). By integrating external knowledge sources, RAG addresses limitations of LLMs, such as outdated knowledge and hallucinated responses.
These services use advanced machinelearning (ML) algorithms and computer vision techniques to perform functions like object detection and tracking, activity recognition, and text and audio recognition. He has helped multiple enterprises harness the power of AI and machinelearning on AWS.
Generative artificialintelligence (AI) is rapidly emerging as a transformative force, poised to disrupt and reshape businesses of all sizes and across industries. LLM chain service – This service orchestrates the solution by invoking the LLMmodels with a fitting prompt and creating the response that is returned to the user.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




























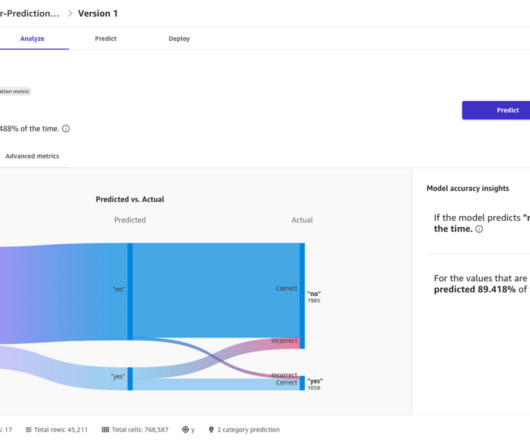



















Let's personalize your content