This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Add to this the escalating costs of maintaining legacy systems, which often act as bottlenecks for scalability. The latter option had emerged as a compelling solution, offering the promise of enhanced agility, reduced operational costs, and seamless scalability. Scalability. Cost forecasting. Legacy infrastructure.
From data masking technologies that ensure unparalleled privacy to cloud-native innovations driving scalability, these trends highlight how enterprises can balance innovation with accountability. With machinelearning, these processes can be refined over time and anomalies can be predicted before they arise.
Organizations are increasingly using multiple largelanguagemodels (LLMs) when building generative AI applications. Although an individual LLM can be highly capable, it might not optimally address a wide range of use cases or meet diverse performance requirements.
With rapid progress in the fields of machinelearning (ML) and artificialintelligence (AI), it is important to deploy the AI/ML model efficiently in production environments. The architecture downstream ensures scalability, cost efficiency, and real-time access to applications.
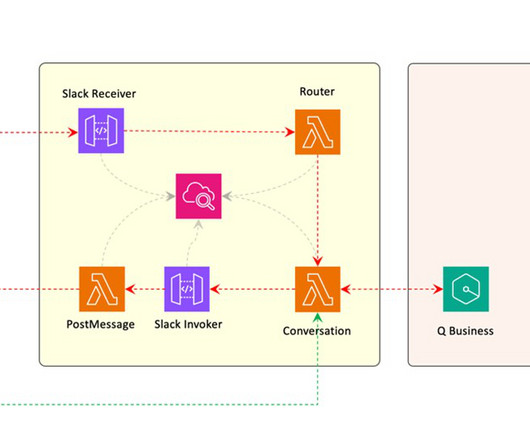
For MCP implementation, you need a scalable infrastructure to host these servers and an infrastructure to host the largelanguagemodel (LLM), which will perform actions with the tools implemented by the MCP server. We will deep dive into the MCP architecture later in this post.
National Laboratory has implemented an AI-driven document processing platform that integrates named entity recognition (NER) and largelanguagemodels (LLMs) on Amazon SageMaker AI. In this post, we discuss how you can build an AI-powered document processing platform with open source NER and LLMs on SageMaker.
Amazon Web Services (AWS) provides an expansive suite of tools to help developers build and manage serverless applications with ease. In this article, we delve into serverless AI/ML on AWS, exploring best practices, implementation strategies, and an example to illustrate these concepts in action.
This innovative service goes beyond traditional trip planning methods, offering real-time interaction through a chat-based interface and maintaining scalability, reliability, and data security through AWS native services. An agent uses the power of an LLM to determine which function to execute, and output the result based on the prompt guide.
Traditionally, building frontend and backend applications has required knowledge of web development frameworks and infrastructure management, which can be daunting for those with expertise primarily in data science and machinelearning. The Streamlit application will now display a button labeled Get LLM Response.
We demonstrate how to harness the power of LLMs to build an intelligent, scalable system that analyzes architecture documents and generates insightful recommendations based on AWS Well-Architected best practices. This scalability allows for more frequent and comprehensive reviews.
This engine uses artificialintelligence (AI) and machinelearning (ML) services and generative AI on AWS to extract transcripts, produce a summary, and provide a sentiment for the call. Organizations typically can’t predict their call patterns, so the solution relies on AWS serverless services to scale during busy times.
Their DeepSeek-R1 models represent a family of largelanguagemodels (LLMs) designed to handle a wide range of tasks, from code generation to general reasoning, while maintaining competitive performance and efficiency. The following diagram illustrates the end-to-end flow.
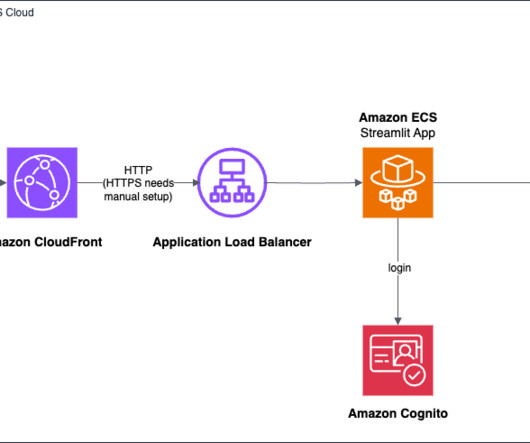
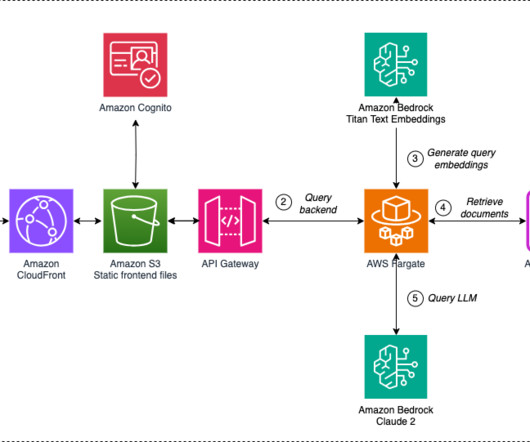
API Gateway is serverless and hence automatically scales with traffic. The advantage of using Application Load Balancer is that it can seamlessly route the request to virtually any managed, serverless or self-hosted component and can also scale well. It’s serverless so you don’t have to manage the infrastructure.
Since Amazon Bedrock is serverless, you don’t have to manage any infrastructure, and you can securely integrate and deploy generative AI capabilities into your applications using the AWS services you are already familiar with. Furthermore, our solutions are designed to be scalable, ensuring that they can grow alongside your business.
By leveraging genAI assistants and largelanguagemodels, AI search can interpret a user request and deliver results in a business context. Look for an open ecosystem that integrates with all the major AI foundation models and supports your own models so existing investments arent wasted.
With advancement in AI technology, the time is right to address such complexities with largelanguagemodels (LLMs). Amazon Bedrock has helped democratize access to LLMs, which have been challenging to host and manage. Amazon Textract is polled to update the job status and written into Mongo DB.
The solution integrates largelanguagemodels (LLMs) with your organization’s data and provides an intelligent chat assistant that understands conversation context and provides relevant, interactive responses directly within the Google Chat interface. Which LLM you want to use in Amazon Bedrock for text generation.
However, even in a decentralized model, often LOBs must align with central governance controls and obtain approvals from the CCoE team for production deployment, adhering to global enterprise standards for areas such as access policies, model risk management, data privacy, and compliance posture, which can introduce governance complexities.
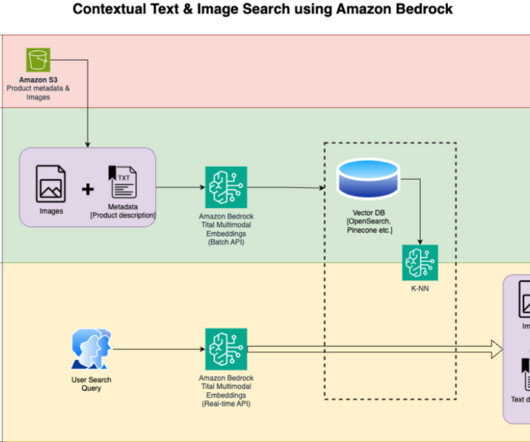
In this post, we show how to build a contextual text and image search engine for product recommendations using the Amazon Titan Multimodal Embeddings model , available in Amazon Bedrock , with Amazon OpenSearch Serverless. Amazon SageMaker Studio – It is an integrated development environment (IDE) for machinelearning (ML).
Generative AI is a type of artificialintelligence (AI) that can be used to create new content, including conversations, stories, images, videos, and music. Like all AI, generative AI works by using machinelearningmodels—very largemodels that are pretrained on vast amounts of data called foundation models (FMs).
In this post, we demonstrate how we used Amazon Bedrock , a fully managed service that makes FMs from leading AI startups and Amazon available through an API, so you can choose from a wide range of FMs to find the model that is best suited for your use case.
For knowledge retrieval, we use Amazon Bedrock Knowledge Bases , which integrates with Amazon Simple Storage Service (Amazon S3) for document storage, and Amazon OpenSearch Serverless for rapid and scalable search capabilities. About the authors Cassandre Vandeputte is a Solutions Architect for AWS Public Sector based in Brussels.
More than 170 tech teams used the latest cloud, machinelearning and artificialintelligence technologies to build 33 solutions. The objective is to automate data integration from various sensor manufacturers for Accra, Ghana, paving the way for scalability across West Africa.
These assistants can be powered by various backend architectures including Retrieval Augmented Generation (RAG), agentic workflows, fine-tuned largelanguagemodels (LLMs), or a combination of these techniques. To learn more about FMEval, see Evaluate largelanguagemodels for quality and responsibility of LLMs.
Amazon Bedrocks broad choice of FMs from leading AI companies, along with its scalability and security features, made it an ideal solution for MaestroQA. Customers can select the model that best aligns with their specific use case, finding the right balance between performance and price.
From deriving insights to powering generative artificialintelligence (AI) -driven applications, the ability to efficiently process and analyze large datasets is a vital capability. That’s where the new Amazon EMR Serverless application integration in Amazon SageMaker Studio can help.
Of late, innovative data integration tools are revolutionising how organisations approach data management, unlocking new opportunities for growth, efficiency, and strategic decision-making by leveraging technical advancements in ArtificialIntelligence, MachineLearning, and Natural Language Processing.
Generative artificialintelligence (AI) has gained significant momentum with organizations actively exploring its potential applications. As successful proof-of-concepts transition into production, organizations are increasingly in need of enterprise scalable solutions.
During the solution design process, Verisk also considered using Amazon Bedrock Knowledge Bases because its purpose built for creating and storing embeddings within Amazon OpenSearch Serverless. In the future, Verisk intends to use the Amazon Titan Embeddings V2 model. The user can pick the two documents that they want to compare.
Organizations must understand that cloud security requires a different mindset and approach compared to traditional, on-premises security because cloud environments are fundamentally different in their architecture, scalability and shared responsibility model.
This is a single, integrated location that allows for a data warehouse, and large data processing. Also combines data integration with machinelearning. This is designed for large-scale data storage, query optimization, and analytics. This is ideal for exploring data without moving it into a structured data warehouse.
With this launch, you can now access Mistrals frontier-class multimodal model to build, experiment, and responsibly scale your generative AI ideas on AWS. AWS is the first major cloud provider to deliver Pixtral Large as a fully managed, serverlessmodel.
Generative artificialintelligence (AI) is rapidly emerging as a transformative force, poised to disrupt and reshape businesses of all sizes and across industries. LLM chain service – This service orchestrates the solution by invoking the LLMmodels with a fitting prompt and creating the response that is returned to the user.
By moving our core infrastructure to Amazon Q, we no longer needed to choose a largelanguagemodel (LLM) and optimize our use of it, manage Amazon Bedrock agents, a vector database and semantic search implementation, or custom pipelines for data ingestion and management.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading artificialintelligence (AI) companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon through a single API. INST] Assistant: The following animation shows the results.
Cost optimization – This solution uses serverless technologies, making it cost-effective for the observability infrastructure. Multiple programming language support – The GitHub repository provides the observability solution in both Python and Node.js However, some components may incur additional usage-based costs.
The Asure team was manually analyzing thousands of call transcripts to uncover themes and trends, a process that lacked scalability. Staying ahead in this competitive landscape demands agile, scalable, and intelligent solutions that can adapt to changing demands.
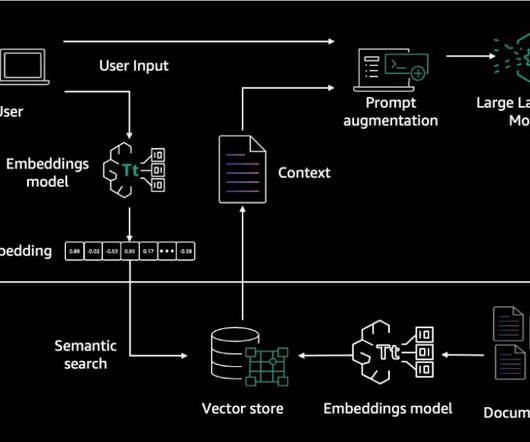
Retrieval-Augmented Generation (RAG) is a key technique powering more broad and trustworthy application of largelanguagemodels (LLMs). By integrating external knowledge sources, RAG addresses limitations of LLMs, such as outdated knowledge and hallucinated responses.
In part 1 of this blog series, we discussed how a largelanguagemodel (LLM) available on Amazon SageMaker JumpStart can be fine-tuned for the task of radiology report impression generation. It’s serverless, so you don’t have to manage any infrastructure. It is time-consuming but, at the same time, critical.
For several years, we have been actively using machinelearning and artificialintelligence (AI) to improve our digital publishing workflow and to deliver a relevant and personalized experience to our readers. Storm serves as the front end for Nova, our serverless content management system (CMS).
AWS was delighted to present to and connect with over 18,000 in-person and 267,000 virtual attendees at NVIDIA GTC, a global artificialintelligence (AI) conference that took place March 2024 in San Jose, California, returning to a hybrid, in-person experience for the first time since 2019.
Leveraging Serverless and Generative AI for Image Captioning on GCP In today’s age of abundant data, especially visual data, it’s imperative to understand and categorize images efficiently. TL;DR We’ve built an automated, serverless system on Google Cloud Platform where: Users upload images to a Google Cloud Storage Bucket.
Generative artificialintelligence (AI) can be vital for marketing because it enables the creation of personalized content and optimizes ad targeting with predictive analytics. Therefore, human evaluation was required for insights generated by the LLM. This post was co-written with Mickey Alon from Vidmob.
Chatbots use the advanced natural language capabilities of largelanguagemodels (LLMs) to respond to customer questions. They can understand conversational language and respond naturally. It augments prompts with these relevant chunks to generate an answer using the LLM.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content